G検定 予測結果の評価尺度 #1

株式会社リュディアです。G検定対策として機械学習の評価尺度についてまとめたいと思います。日本語でよく似た用語が並ぶので混乱しやすいと思います。言葉の意味をしっかりと理解してください。
機械学習に限らず予測値と測定値のあたりはずれを評価したい状況はよくあります。そのデータ集計を行う際に用いるのが混同行列 (Confusion Matrix) です。混合ではなくて混同です。間違えないようにしてください。
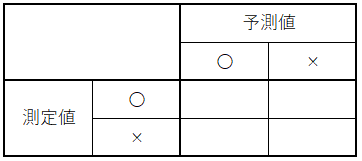
まず選択肢として〇×の2つがある場合を考えます。予測値と測定値のそれぞれに〇×がありうるので組合せの数としては以下の 4 つになります。
1. 予測値が〇で測定値が〇
2. 予測値が〇で測定値が×
3. 予測値が×で測定値が〇
4. 予測値が×で測定値が×
皆さんはどんな集計結果が欲しいと思いますか?まず全体として〇×にかかわらず予測値と測定値が一致した確率はどれくらいだったか知りたいですよね?
その次はどうでしょうか?予測値を固定して考えてみましょう。予測値が〇であったときに測定値も〇であった確率はどれくらいか?逆に×の場合も同様に考えられますね。
さらに測定値を固定して考えてみましょう。測定値が〇であったときに予測値が〇であった確率はどれくらいか?逆に×の場合も考えられますね。
以上をまとめると以下の5つに分類できることがわかります。
A. 全体で予測値と測定値が一致した確率
B. 〇と予測して測定値も〇だったものの確率
C. ×と予測して測定値も×だったものの確率
D. 測定値が〇だったもののうち予測値も〇だったものの確率
E. 測定値が×だったもののうち予測値も×だったものの確率
Aを正解率と呼びます。そのままですね。これは簡単です。数式は後回しにしてまず言葉と言葉の意味を一致させましょう。
Bは適合率と呼びます。〇を予測したうち正解であったものの確率です。〇 を予測して測定値が 〇なので適合している、と考えます。陽性的中率とも言います。
C は × の適合率ではないのか?と思われた方、正解です。ただし陰性的中率と呼びます。ただしG検定の公式テキストにはこの用語は出ていません。陽性的中率、陰性的中率の方がわかりやすいと思うのですけどね。
Dは再現率と呼びます。測定値が〇のうち、〇を予測したのはどれだけか?つまり再現したのはどれだけか?と考えます。
Eは特異度と呼びます。Dの× 版ですね。こちらも G検定公式テキストには出ていません。これだけが特異率ではなくて特異度です。注意してください。
結論として A 正解率は全体を扱う、B の適合率、C の陰性的中率は予測値を基準として測定値とどれだけ一致したか?を考える確率です。D の再現率、E の特異度は測定値を基準として予測値がどれだけ一致したか?を考える確率です。
今回は〇×を選択しとして混同行列と性能指標の用語のみをまとめてみました。
では、ごきげんよう。
この記事が気に入ったらサポートをしてみませんか?