
【Python・Tableau基礎 | PythonでData saber】Order1 fundamental 前編(1/2) a.k.a Newjeans.

本題に入る前に、雑談になりますが、最近ニュージンズのハニーちゃんがすごく可愛いな思って、その推し活を少し始めました。最近短髪になって、松田聖子の青い珊瑚礁歌った舞台は、すごくいいなと思いました。

機会あれば、是非Youtubeで動画みてみてください!
20代でも30の平成世代でも絶対昭和を感じれるはずです。(とにかくハニーちゃんが可愛すぎる)
雑談が長くなりまして、ごめんなさい🙇
それでは早速本題に入りましょう。
今回、Data saberの最初の課題をやっていました。
奇数目週の課題が、サンプルデータを用いたTableau上での可視化であり、見てみる限りでは、データフレームをいじって問題にぶつけて必要な可視化をしていく流れです。偶数目は座学ですかね。
過去このプログラムの履修者の記事を見ると、Tableau上での成動画をアップした方や座学の振り返りになっていますが、自分は動画編集ができないし、硬い概念の勉強は嫌いなので、勝手ながらですが、可能な構成にさせてください🙇
課題を解く過程を少し、確認してみると、
結構簡単なデータの読み込みから、がっつりした可視化までやるもので、Pythonの入門者にもちょうどよく展開できるもんじゃないかと思っています。
各問題に、必要な基礎知識や関連コードを表示および説明していきますので、はじめてPythonに触る、大学生・社会人(以外の人ももちろん!)の方は安心して読んでください。
Pythonの環境は、少し分けがあって、GoogleのColabを使用しています。
(自分は元々Jupyterユーザーなんですが、転職を機にこちらを使っています。)
課題を解く前にまずは、まずは必要なライブラリをインポートしていきましょう!!今回必要なライブラリは下記になります。
import numpy as np
import pandas as pd
import seaborn as sns
import japanize_matplotlib(日本語による可視化)
⇒インストールされていないと思いますので、!pip install japanize_matplotlibでインストールしてください
import matplotlib.pyplot as plt
from collections import Counter
import datetime as datetime
⇒ライブラリっていったいなんぞやという初心者の方は、こちらの記事を参考にしてくださいね。
(https://cad-kenkyujo.com/python-library-install/#:~:text=Python%E3%81%AE%E3%83%A9%E3%82%A4%E3%83%96%E3%83%A9%E3%83%AA%E3%81%A8%E3%81%AF,%E3%81%A6%E9%96%8B%E7%99%BA%E3%81%AB%E5%8F%96%E3%82%8A%E7%B5%84%E3%82%81%E3%81%BE%E3%81%99%E3%80%82)
#Q1 (データのグループ化、並び替え、水平棒グラフ)
サブカテゴリ「バインダー」は「事務用品」内で売上第何位ですか?順位を数字で明記する必要はなく、目視で分かる形になっていればよいです。
最初の問題は、よくみるデータのグループ化ですね。Excel使う社会人の方でしたら、"ピボットテーブル使ったら、一瞬じゃん!"という方がいるとおもいますが、まさにその通りです。エクセルはやっぱすばらしいツールですよね。。(笑)
せっかくなので、Pythonで見ていきましょう
まずは、サンプルデータを使うために、読み込みからはじまります。
今回のサンプルデータは、エクセルのxlsファイルでありますので、それを読み込んでみます。
⇒サンプルデータは以下の公開リンクからダウンロードできます。
(https://drive.google.com/drive/u/0/folders/1kXSb3fqPTt3VcPjGUSgOmrztlRfvvpMH)
先ほど、読んでいたPandasは利用して、まずはデータを読み込んでみましょう
#エクセルファイル読み込み
df_store = pd.read_excel("各自のデータのパス")
df_store.head()
df_storeといったデータフレームの変数名に、以下のようなデータが読み込まれました。
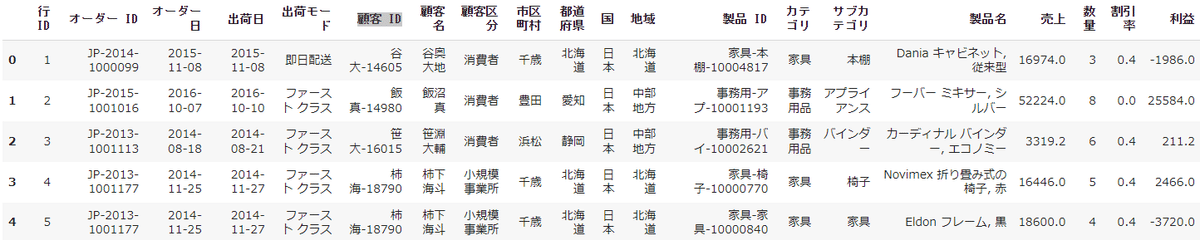
head()関数を使ったので、最初の5行目だけが表示されています。
実際は、結構デカい良なので、何千行になっているデータだと思いますが、ちゃんと読み込まれていることが確認できました。
しかし、これだけだと、カテゴリやサブカテゴリ列にいったい何が入っているだろうとわかることができませんね。
まあ、いろんなデータが重複されていると思いますが、どんなデータが入っているのかみていきましょう。
#入っているデータ確認
print(pd.unique(df_store["カテゴリ"]))
print(pd.unique(df_store["サブカテゴリ"]))
['本棚' 'アプライアンス' 'バインダー' '椅子' '家具' '紙' '画材' '保管箱' 'ラベル' '封筒' 'クリップ' '事務機器' 'テーブル' 'コピー機' '付属品' '電話機' '文房具'] ['家具' '事務用品' '家電']
pandasのunique関数を用いて、各列にはどのようなデータが格納されているのかを確認しました。今回必要なのは、カテゴリの事務用品の中で、バインダーは何位に入るかでありますので、それに基づいてデータをグループ(ピボット)します。
# 「カテゴリ」と「サブカテゴリ」列のデータ種類を基に、「売り上げ」列の売り上げを集計
grouped_df = df_store.groupby(['カテゴリ', 'サブカテゴリ'])['売上'].sum().reset_index()
# 集計結果を表示
print(grouped_df)
groupby関数を使い、まずは、カテゴリ・サブカテゴリに整理させて、売上の合計分を集計させました。通常グループ化の際は、データのインデックス(最初行のカテゴリ)をリセットするので、reset_index()も付けています。
この集計結果を表示してみると

事務用品以外の家具もでてきていたり、売り上げ金額もばらばらになっていて、バインダーの順位がわかりにくいですね。
なので、カテゴリの事務用品だけみてみましょう
# 「カテゴリ」列が「事務用品」のデータのみを抽出
office_supplies_df = grouped_df[grouped_df['カテゴリ'] == '事務用品']
#売り上げ列の降順
office_supplies_df = office_supplies_df.sort_values(by='売上', ascending=False)
print(office_supplies_df)
カテゴリの事務用品に当たるデータのみ持ってきて、売り上げを降順に並ばせました。もし、昇順にしたい場合には、ascending = Trueをすると昇順になります。
結果をみてみましょう

バインダーが4番目に位置していることがわかりましたね!
これでこの問題は終了!
といいたいところですが、見づらいので、棒グラフを描いてきれいにしていきましょう。
順序を見たい場合は、横方向で棒が立っている棒グラフをみた方がわかりやすいなので、水平棒グラフを作成してみます。
# 並べ替えたデータフレームを基に水平棒グラフを作成
plt.figure(figsize=(10, 6)) # グラフのサイズを指定plt.barh(office_supplies_df['サブカテゴリ'], office_supplies_df['売上'], color='skyblue') # 水平棒グラフを作成
# グラフのタイトルと軸ラベルを設定
plt.title('売り上げ by サブカテゴリ')
plt.xlabel('売り上げ')
plt.ylabel('サブカテゴリ')
# x軸の降順に並べ替え
plt.gca().invert_yaxis()
# グラフを表示
plt.show()

pyplotライブラリで、グラフをこのように作成しました!
これにより、バインダーが4位に位置していることが確認できましたね!
Tableau上では、

この通りになっていまして、カテゴリに事務用品のフィルタがかけられていて同時にみられています。X軸の数値もMで百万単位になっていて、最初からきれいに整理されている模様です。PythonでもX軸のスケールを変えれば、同様に変換できます。
スケールを調整できるpyplotライブラリのtickerパッケージをインポートして、描いてみました。
import matplotlib.ticker as ticker
#グラフの作成
plt.figure(figsize=(10, 6)) #グラフのサイズを指定
plt.barh(office_supplies_df['サブカテゴリ'], office_supplies_df['売上'], color='skyblue') # 水平棒グラフを作成
#グラフのタイトルと軸ラベルを設定
plt.title('売り上げ by サブカテゴリ')
plt.xlabel('売り上げ (百万)')
plt.ylabel('サブカテゴリ')
#x軸のスケールを百万単位に変換
def millions(x, pos):
return '%1.0fM' % (x * 1e-6)
ax = plt.gca()
ax.xaxis.set_major_formatter(ticker.FuncFormatter(millions))
#x軸の降順に並べ替え
ax.invert_yaxis()
#グラフを表示
plt.show()

これで単位を調整できたグラフが作られました。
カスタムさせたスケールであるため、カスタムに必要な関数を自分で作る手間は発生しましたが、何とかきれいに表示することができました。
少し、設定した関数の中の値を説明しますと、 '%1.0fM' %は.0fで小数点0までを表示させ1M,2Mで表示形式を設定させたものになります。 (x * 1e-6)は、x(今回の場合売上)の値をe-6(0.00001)をかけたものになります。つまり100万で値を割った数値になりますね。
以上にこの問題はクリアになります。
Q2(データのグループ化、平均集計)
割引率が最も大きい地域はどこですか?また、そこでの割引率は何%でしたか?
今回も、データをグループ化する問題ですね。先は、グループ化したものを合計で集計したものですが、今回は、平均で集計したものになります。
まずは、地域の属性をみてみると、
print(pd.unique(df_store["地域"]))
['北海道' '中部地方' '関西地方' '九州' '関東地方' '東北地方' '中国地方' '四国']
で出ますね。
Q1で使ったgroupby関数を使い地域を基に割引率を平均で集計させましょう。
grouped_df2 = df_store.groupby(['地域'])['割引率'].mean().reset_index()
grouped_df2 = grouped_df2.sort_values(by = "割引率" ascending=False) #割引率を基に降順
print(grouped_df2)
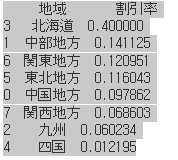
出ましたね!
これを見ると、最も高い割引率である地域は北海道であることがわかります!
これも棒グラフで表示できますが、先やったので、この回はスキップします1
Q3(データのグループ化,重複値削除,datetimeの年データの取得、長さを確認するlen関数)
オーダー日の2014年を対象とした場合,顧客IDとカテゴリの組み合わせの種類はいくつになりますか?
3問目も同じく、グループ化させるものになりますが、今回は先の問題とは異なり、2014年のものといった指定が入っていますね。つまり、2014年のデータを一回フィルタリングする必要があることになるますね。
データの種類で、年月日は、一般的な数字とは違い、別といったタイプになります。故に、日付データは、インポートしたdatetime関数を用いて、その編集を行う必要が発生するわけです。
まずは、オーダー日列のデータは何年のものなのかみていきましょう。
#オーダー年の種類確認
print(df_store["オーダー日"].dt.year.unique()) #datetime型の場合、pd.uniqueではなく、そのままunique()を使う
[2015 2016 2014 2013]
13年から16年まで、4年分のデータがあるというわけですかね?
先の1問目で、我々はカテゴリの事務用品データのみを持ってきました。
今回も同様にやれればいいですが、データの数値や文字型ではないため、datetimeの関数を組ませる必要があります。そこから2014年だけ抜き取り、集計した値をとるわけではなく、IDとカテゴリでグループ化させればいける気がします。
ただ、ここまで大きいサイズのデータは重複の値も非常に多いと思います。
例えば、Aさん家具、Aさん家具といったデータがあった場合、そのまま持ってくるわけなので、二個としてグループ化されるわけですね。故に重複は消して一個としてまとめれば、正確な場合の数が求められるはずです。
重複を消す関数としてdrop_duplicates()関数が用いられます。
重複を消しても非常に大きいサイズであると思うから、何通りあるかを行数を確認することで見てみましょう
#2014年のデータのみを抽出
df_2014 = df_store[df_store["オーダー日"].dt.year == 2014]
#ID、カテゴリ列のグループ化
grouped_df3 = df_2014[['顧客 ID', 'カテゴリ']].drop_duplicates()
#データフレーム長さの確認
print(f"通りの数は:{len(grouped_df3)}")
通りの数は:1181
出ましたね!もちろんインデックスの値は入らないので、きれいにデータの行数のみの長さを確認することができました。
補足ですが、列の長さを把握したい場合には、.column関数を使用し、そのままlen関数を用いればわかります。len(grouped_df3.column)
これで問題3も突破です!
この記事が気に入ったらサポートをしてみませんか?