
VRChat上での実用的なDNNの実装

この記事は VRChat Advent Calendar 2021 の21日目の記事として書かれました。
はじめに
今年の9月ごろにVirtualLens2に顔・瞳検出オートフォーカス機能を実装しました。
VirtualLens2 v2.8.0 をリリースしました。
— ろじ(っく) (@logi9_) September 20, 2021
大変お待たせしました、顔AF/瞳AFなどフォーカス関連の機能強化がメインのアップデートとなります。
詳細は動画やツリーをご参照ください。https://t.co/lDPVyPn9rK pic.twitter.com/bQaksDROzq
この顔検出はいわゆる深層学習 (ディープラーニング) を用いたもので、私の知る限りでは現在VRChat上で動作するものの中ではトップクラスの実用性・精度・速度を備えた機械学習アプリケーションではないかと思います。
本稿ではアバターギミックとして深層学習ベースの推論器を実装するのに使用した細かいテクニックなどをいくつかご紹介します。
ネットワークの選定
今回は一般物体検出用のネットワークのうち特に軽量なものである YOLOX-Nano を採用しました。VRChatが動く環境は比較的高性能なGPUを搭載していることが多いものの、後述するようなVRChatアバター固有の制約により理論ピークからはほど遠い性能しか出ないこととかなり高いフレームレートが要求されることから軽量なネットワークを選択する必要があります。また、軽量なネットワークはパラメータ数が少ないことも多く最終的にアバターに組み込まれることになるパラメータファイルが小さくなるメリットもあります。
プログラマブルシェーダーを用いた汎用計算
プログラマブルシェーダーを用いることでGPUで汎用計算ができることはVRChat内外を問わず広く知られています。なぜかカスタムシェーダーが利用できるVRChatアバターも例外ではなく、比較的リッチなプログラミング言語で記述されたGPUプログラムを組み込むことができます。また、GPUはニューラルネットワークの計算に適していることも広く知られています。これらを総合するとVRChatのアバターにニューラルネットワークを組み込むことは自然な流れと言えるでしょう。
シェーダープログラムの呼び出し
VRChatのアバターギミックにおいて計算用のシェーダープログラムを実行する方法は大きくカメラを用いる方法と Custom Render Texture (CRT) を用いる方法の2つにわけられます。VirtualLens2では後に解説する理由によりCRTを用いる方法を採用できなかったため、以降の節ではカメラを用いたシェーダープログラムの呼び出し方法について解説します。
基本的な構造
カメラを用いてシェーダープログラムを実行する場合、以下の図のようなカメラとメッシュの組が使用されます。ここで、カメラの Render Target に指定されている Render Texture が出力バッファ、メッシュのマテリアルに設定されているテクスチャなどが入力データとなります。そして、カメラにメッシュが写ることでマテリアルに対応するシェーダーが実行されることとなります。

更新範囲の設定
メッシュをレンダリングする際にはまずバーテックスシェーダーが呼び出されます。ここでは出力バッファのうちどの範囲に値を出力するかを求めます。この時、いわゆる視界ジャックシェーダーと似た方法で投影後の座標を求めています。
#define BUFFER_WIDTH (16) // 出力バッファの幅
#define BUFFER_HEIGHT (8192) // 出力バッファの高さ
#define DEST_OFFSET_X (0) // 出力先領域へのX方向オフセット
#define DEST_OFFSET_Y (256) // 出力先領域へのY方向オフセット
#define DEST_WIDTH (16) // 出力先領域の幅
#define DEST_HEIGHT (128) // 出力先領域の高さ
v2f vertex(appdata v){
v2f o;
// 計算用カメラでなければ何も描画しない
if(!isComputeCamera()){
o.vertex = 0;
o.uv = 0;
return o;
}
// [0, 1] の範囲の座標に変換
const float x = (v.uv.x * DEST_WIDTH + DEST_OFFSET_X) / BUFFER_WIDTH;
const float y = (v.uv.y * DEST_HEIGHT + DEST_OFFSET_Y) / BUFFER_HEIGHT;
// [-1, 1] の範囲の座標に変換
const float proj_x = (x * 2 - 1);
const float proj_y = (y * 2 - 1) * _ProjectionParams.x;
// 投影後の座標とフラグメントシェーダーに渡すUV座標の計算
o.vertex = float4(proj_x, proj_y, 0, 1);
o.uv = float2(v.uv.x * DEST_WIDTH, v.uv.y * DEST_HEIGHT);
return o;
}出力の計算
バーテックスシェーダーの処理が終わるとそこで求められた範囲内の全画素についてフラグメントシェーダーが呼び出されます。ここで返した値が Render Texture に記録されることになるため、主要な計算はここで行うことになります。ここではバーテックスシェーダーから渡されたUV座標を元にどの画素 (=インデックス) に対応するデータを担当しているのかを判断します。
float4 frag(v2f i){
const int index = floor(i.uv.x) + floor(i.uv.y) * DEST_WIDTH;
// index 番目の出力を計算する
return compute_something(index);
}中間バッファの取り扱い
深層学習においてはある層の出力を計算するために前の層の出力の各要素を複数回参照することになります。この時に前の層の出力をメモリ上に一旦保持することになるのですが、VRChatのアバターなどのスクリプトを用いることができない環境ではシェーダーの出力をメモリに書き出す方法に制約があります。今回候補に挙がったのは以下の3方式で、それぞれにメリットデメリットが存在します。
複数のカメラを用いる方法
○: 層ごとにバッファサイズを細かく制御することができる
○: カメラが有効になるまでVRAMが確保されない
○: 同一フレーム中でもバッファを使いまわすことができる
×: カリングなどに由来するカメラ1台あたりのオーバーヘッドが大きい
×: 大量の Mesh Renderer をヒエラルキーに追加することになる
GrabPass を用いる方法
○: カメラは1台で済むためそこに由来するオーバーヘッドは小さい
○: カメラが有効になるまでVRAMが確保されない
○: 同一フレーム中でもバッファを使いまわすことができる
×: 常にバッファ全体をコピーするため無駄なコピーが生じやすい
×: メッシュが他のカメラに写りこむと余分なコストがかかってしまう
CRTを用いる方法
○: カメラやバッファコピーに起因するオーバーヘッドがほぼない
○: 余計な Mesh Renderer をヒエラルキーに入れなくてよい
×: アバターがロードされた瞬間にVRAMを消費してしまう
×: フレーム中でバッファを使いまわすことができない
これらを踏まえてどの方式を採用するか検討してみましょう。まずVRAM消費の問題でCRTが除外されます。1インスタンスに複数人VirtualLens2ユーザーがいる状況も珍しくないことを考えると実装済みアバターをロードするだけで数10MB単位で追加でVRAMを消費されるのは好ましくないと言えるでしょう。次にカメラごとにかかるコストの大きさで複数のカメラを用いる方法が除外されます。カメラ1つあたりのオーバーヘッドがおよそ0.1ms程度、そして今回実装したネットワークではおよそ80回程度中間バッファを用いるためそれだけで8ms程度消費される計算となりやや難があるだろうと判断しました。というわけで、消去法でGrabPassを用いる方法を採用することとなりました。こちらも多少問題はありますが他の方式の抱える問題に比べればまだ対処の余地があります。
なお、今回は採用しませんでしたがこれらの手法は組み合わせて使用することができます。例えば基本的にはGrabPassを使用しつつバッファサイズが大きく変化するところで別のカメラに切り替える、といった手法はオーバーヘッドを加味してもなお有効な場面もあるかと思います。
データレイアウト
バッファの確保ができたので今度はバッファとして利用するテクスチャにデータをどう並べるかを考えましょう。
まず数値をどのように表現するか決めます。今回は実行時の負荷と精度や実装コストとのバランスを考慮して半精度浮動小数点数を使用することとしました。
次にピクセルフォーマットを決めます。素直に考えると R16_SFLOAT か R16G16B16A16_SFLOAT としたいところですがここでは R32G32B32A32_SFLOAT を使用します。そして、RGBA各要素に半精度浮動小数点数2つをパックしてやることで1画素あたり8つの値を記録するようにします。これはメモリアクセスの回数を減らしてテクスチャユニットの負荷を抑えるためで、これによって演算コアにかなり余裕があるのにテクスチャユニットで処理が律速してしまって性能が上がりきらない問題を緩和します。また、このときチャンネル・幅・高さ各方向に2要素ずつの要素をパックすると隣接する要素の計算では入力をいくつか使いまわすことができるためさらにメモリトラフィック自体を減らすことができます。
最後にバッファに対して3次元のテンソルデータをどう並べるかを決めます。ここではテクスチャが2次元データであることは気にせずに単なる1次元のバッファとみなしてレイアウトを考えます。今回はチャンネルがもっとも外側にあると実装上都合がよかったため行優先で (チャンネル, 高さ, 幅) の順で並べました。実際にはピクセル内でのパッキングもあるためそれも考慮すると CHWHWC のようになります。
バッファのスケジューリング
GrabPassで中間バッファを作る場合、1つの大きなバッファをネットワーク全体で使いまわすことになります。そしてGrabPassを用いると更新状況によらずバッファ全体がコピーされてしまうため、できるだけバッファのサイズを小さくすることが高速化につながります。
AlexNetやVGGのようなDNN黎明期によく見られた一直線のネットワークであれば一番出力要素数の多い層にあわせるだけで良いのですが、近年のネットワークでは Shortcut Connection などある層の出力を複数の層で利用するケースも多く適切に領域の割り当てや寿命の管理を行う必要があります。今回は比較的規模の小さいネットワークを1つだけ実装できればよかったため手動で処理順とバッファ割り当てを決定しました。
モジュールの使いまわし
DNNの計算では畳み込みを始めとしたいくつかのカーネルを何度も呼び出すことになります。このため、各カーネルはパラメータを差し替えつつ使いまわせるような実装とする必要があります。VirtualLens2では以下のようにマクロでパラメータを設定してincludeすることで処理を呼び出せるような実装としています。
// backbone.backbone.dark2.1.conv1
Pass
{
HLSLPROGRAM
#pragma target 5.0
#pragma vertex vertex
#pragma fragment fragment
#define SOURCE_OFFSET (0x1800) // 入力データへのオフセット
#define DESTINATION_OFFSET (0x1800) // 出力先へのオフセット
#define INPUT_WIDTH (120) // 入力テンソルの幅
#define INPUT_HEIGHT (64) // 入力テンソルの高さ
#define INPUT_CHANNELS (32) // 入力テンソルのチャンネル数
#define OUTPUT_CHANNELS (16) // 出力テンソルのチャンネル数
#define INPUT_TEXTURE _GrabTexture // 入力バッファ
#define WEIGHT_TEXTURE _Weights // 重みデータ
#define BIAS_TEXTURE _Biases // バイアスデータ
#define WEIGHT_OFFSET_X (32) // 重みデータへのオフセット (X)
#define WEIGHT_OFFSET_Y (848) // 重みデータへのオフセット (Y)
#define BIAS_OFFSET_X (0) // バイアスデータへのオフセット (X)
#define BIAS_OFFSET_Y (29) // バイアスデータへのオフセット (Y)
#include "Config.cginc" // 共通設定 (バッファサイズなど)
#include "../Common/Activations/SiLU.cginc" // 活性化関数
#include "../Common/Convolution1x1.cginc" // 畳み込み (1x1)
ENDHLSL
}プロファイリング
パフォーマンスチューニングを行うときには何がボトルネックになっているかをきちんと特定する必要があります。この時、プロファイラを使用すると手軽に詳細な情報を得ることができます。Unity標準のプロファイラだとシェーダーのチューニングをするには粒度が粗すぎるため外部のプロファイラを使うと良いでしょう。今回は私がNVIDIAのツールに慣れていることもあり NVIDIA Nsight Graphics を利用しました。
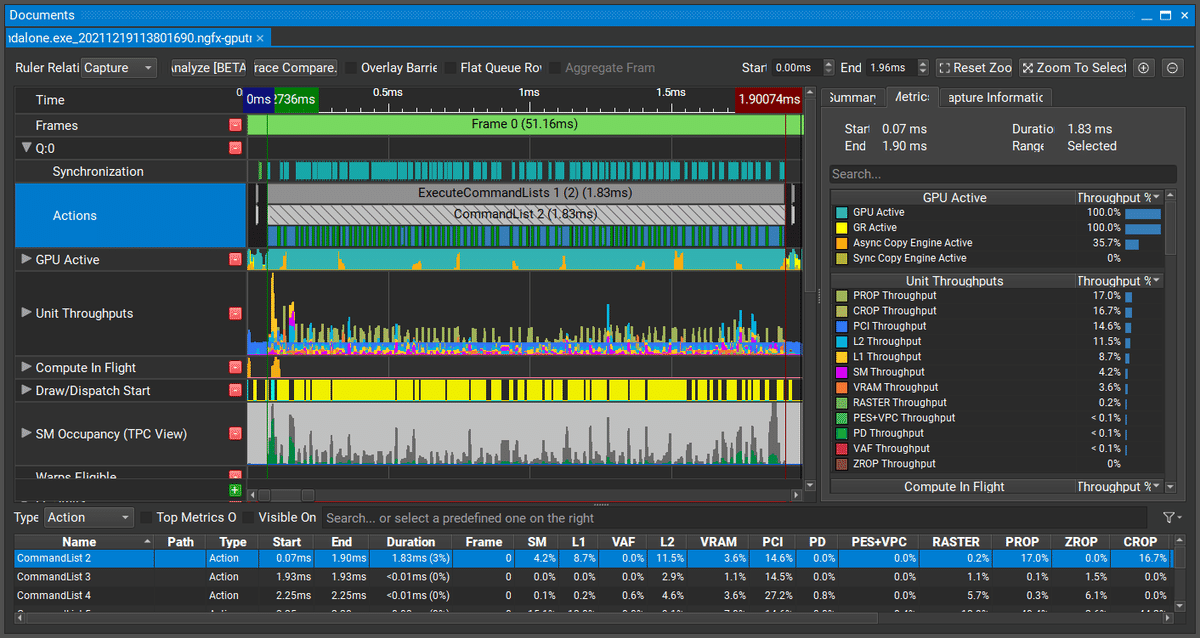
今回の実装にあたっては主に以下の点に注目してプロファイリングを行っていました:
処理時間が想定より明らかに長いパスが存在しないかどうか
Actionsにあるタイムラインを見る
コア数に対して十分なタスクを供給できているか
SM Occupancy (TPC View) を見る
GPUのどのユニットが原因で律速しているか
Unit Throughputs を見る
タスク供給状況について見ると、上の例ではコア数の多いGPU (GeForce RTX 3090) に対して非常に小さいネットワーク (YOLOX-Nano) を使用しているため全体的にタスク不足でコアが余り気味になっていることがわかります。つまり、この環境でより性能を向上させようとすると並列度を高めるために追加の処理が必要となります。一方で、VirtualLens2を動作させる環境の大部分はこれより小さいGPUが使用されることを考えると実際の稼働率は数倍程度になる環境も多いと思われます。そのため、今回はコア稼働率についてはこれくらいで妥協することとしました。
次に各ユニットの占有率を見てみます。今回の例では全体的に PROP, CROP の占有率が高いことがわかります。PROP, CROPはそれぞれテクスチャからの読み出し、テクスチャへの書きこみに対応するユニットで、コア稼働率と合わせるとそれらの操作を減らすことでより性能が向上するのではないかと考えられます。他によく問題となる要素としては演算器の占有率 (SM Throughput) とメモリ帯域の占有率 (L1, L2, VRAM Throughput) で、それぞれ占有率が高い部分を改善すると全体のパフォーマンスが向上する可能性が高くなります。
より踏み込んだメトリクスの読み方はNVIDIAの開発者ブログにある解説記事などをご参照ください。
おわりに
VRChat上である程度の規模のニューラルネットワークを十分な性能で動かすためのテクニックをいくつかご紹介しました。
まだGPUの性能に対して実効性能は非常に低く利用できるネットワークの規模は限られていますが、いわゆるAI的なギミックを実用的な精度・速度でVRChatに持ち込めることを示せたという点で今回の試行は有意義なものだったと考えています。深層学習アプリケーションの一般的なデプロイ先と比べるとツール類がろくに揃っていないため実装のハードルが高い点は否めませんが、面白そうなアプリケーションがあればぜひVRChatに持ち込んでみてください。
この記事が気に入ったらサポートをしてみませんか?