
AI企業による無許諾の記事利用を防ぐ方法

言語生成AIの基盤となっている大規模言語モデルは、インターネット上のデータを大量に事前学習することによって高い精度を出しています。OpenAIが提供するGPT-3.5の学習データサイズは45TB、GPT-3は450GB、GPT-4は公開されていませんが、その性能の高さから考えると45TBの数十倍であると考えて差し支えないでしょう(Zenn)。ちなみに、Wikipediaの中で日本語の記事の総計が20GB、本7000冊で4.5GBであることを踏まえると、そのデータサイズの巨大さがなんとなくわかると思います。

事前学習データには、当然ニュースメディア各社の記事も大量に含まれています。AI企業はメディア各社から事前に許諾をとっているわけではないため、無許諾での記事データ利用に対して国内外で著作権侵害が懸念されています。これに対し、メディア各社も共同声明を出すことで異を表明しています。例えば、日本では5月17日に日本新聞協会が「生成AIによる報道コンテンツ利用をめぐる見解」として、『著作物無断利用の懸念』や『個人情報保護上の懸念 』について意見を表明しています。直近だと、9月6日に世界中から26のメディア系業界団体が結集して表明した「人工知能のためのグローバル原則」も注目に値します。個社の動きとしては、8月にNewYorkTimesがOpenAIを訴訟する動きをしていることが報じられています(Futurism)。
このように、AI企業はこれまでメディアがパブリッシュしてきた記事コンテンツを使用していますが、その利用方法は大きく分けると2種類存在します。一つ目が、言語生成AIが基盤としている大規模言語モデルの事前学習データとしての使用です。上述の通り、著作権侵害が懸念されている使用方法です。もう一つが、対話型AI検索エンジンの参照情報としての使用です。Search Generative EngineやBing Chat、Perplexity.aiなどが該当します。これらのサービスは、ユーザーの検索クエリに対してウェブ上から最適な情報をリアルタイムで収集し要約として回答を生成します。

検索エンジンにインデックスされているウェブページの内容を元にAIが回答を生成しているため、著作権侵害の懸念は同様に存在します。それに加え、これらのサービスを使えばユーザーが検索結果を閲覧せずに回答を取得できるため、ウェブサイトへのトラフィックを減少させる恐れがあると考えられています。メディアコングロマリット企業であるIACのCEOや、Wall Street Journalの元R&Dヘッドも同様の懸念を表明しています(Digiday, Digital Content Next)。
本記事では、この2種類の使用方法における技術的な成り立ちを概観した上で、それを防ぐ方法とその限界について解説していきます。

大規模言語モデル
AI企業によるデータ収集方法
大規模言語モデルの事前学習データの構成は多様ですが、大きく2種類に大別できます。一つは、第三者が既に収集したデータベースで「コーパス」と言われるものです。2008年以降毎月30億ページ以上更新しているCommon Crawlというウェブコンテンツデータベースや、約11,000冊の本データを収録しているBook Corpus、日本語のWikipediaが約10億字収録されているWikipedia Corpusなど様々な種類が存在します。そのほとんどは非営利団体が運営しているため、AI各社が無料で使用することができます。もう一つは、AI企業が独自にクローリングして収集したデータです。
学習データの構成が公開されている大規模言語モデルを見てみると、実は前者のコーパスを利用したデータ取得が大半を占めていることがわかります。例えば、GPT-3はCommon Crawlが60%を占めており、LLaMAは67%にも及んでいます。


このコーパスですが、誰でも無料で利用することができるため実際に収録されている記事データもこのページから直接確認することができます。実際、CommonCrawlから特定期間の英語記事だけを抜き出したC3というコーパスをワシントンポスト社が解析したところ、情報ソースのトップにNewYorkTimesやLAtimes, The Guardianなど多数のニュースメディアが含まれていました。このコーパスも、クローラーが各ウェブサイトを毎月巡回して自動で更新情報を収集しています。

このように、GPT-3やLLaMAなど一世代前の大規模言語モデルは主にコーパスから取得されたデータを事前学習に使用しています。しかし、GPT-4やPaLM2、今後登場するであろうGeminiといった最新の大規模言語モデルはAI企業が独自にクローリングしたデータも事前学習に使用していると考えるべきです。例えば、Googleは7月に利用規約を「インターネットに一般公開されている情報やその他の公開情報源からの情報を収集し、GoogleのAIモデルのトレーニングのほか、Google翻訳、Bard、CloudのAI機能などのサービスや機能の構築に役立てることがあります」と更新しました。
このように、ニュース含むウェブサイトのデータは、コーパスによるクローリングとAI企業によるクローリングという2つの方法により収集されています。

クローリングを防ぐ方法
自社のウェブコンテンツが勝手に収集・使用されることを防ぐにはこのクローラーをブロックすれば良いのですが、その方法をタグとして公式に提供している企業も存在します。例えば、Googleは9月に「Google-extended」というタグを発表しました。robots.txtで以下のように記述するだけで、BardやVertex AIなど同社が提供するAIサービスの事前学習に利用されることを防ぐことができます(タグを記述したとしても、Google検索にはこれまで通りインデックスされます)。
Use-Agent: Google-Extended
Disallow: /OpenAIは「GPTBot」、Microsoftは「NOARCHIVE」、Common Crawlは「CCBot」というタグを公表しています。上述と同じように、Use-Agentの箇所にこれらのタグを記述するだけでクローラーの巡回を防ぐことができます。
しかし、クローリングを防げるのは「タグの設置以降」のみであることが重要です。これまでに収集・事前学習された自社コンテンツを大規模言語モデルから削除することはできません。収集されたデータは大規模言語モデルへインプットされるまでに様々なクリーニングプロセスを経ますが、その過程でURL等のノイズ情報は除去されます。また、最終的にテキストはベクトル化され数値データに変換されます。このような一連の処理が施されるためで、一度学習したデータを後から特定し削除することは技術的に困難となっています。

また、クローリングを防ぐ公式のタグを用意していないAI企業やコーパスも存在するでしょう。robots.txtでタグを設置する以外にもクローリングを防ぐ技術的な方法は存在しますが、その実態はいたちごっこで完全に防止できる対策は存在しません。
Palewireによると、1143のパブリッシャーのうち、OpenAI、Google、Common Crawlのクローラーを1つ以上ブロックしているのは518社に存在するそうです。日本だと、日経新聞が全三社をブロックしており、読売新聞とBloomberg JapanがOpenAIとCommon Crawlをブロックしています。
対話型検索AIエンジン
AI企業によるデータ収集方法
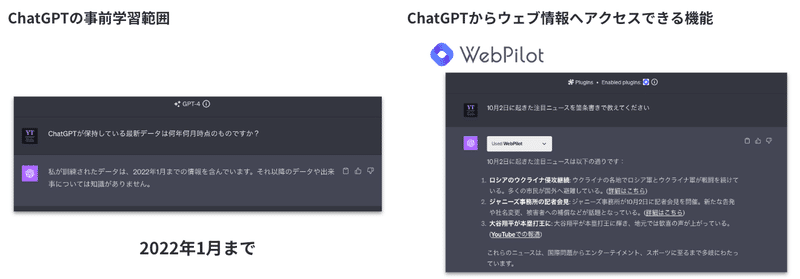
ChatGPTにデフォルトモードで情報収集を依頼すると、「2022年1月まで」が事前学習対象であると表示されます。これはChatGPTを活用する上で大きなデメリットでしたが、2023年5月にWeb Browsingという新機能が発表されました。有料会員であれば使用できる機能で、ユーザーのクエリに対してリアルタイムでウェブを検索し回答を生成・提示することができます。現在は、「Browse with Bing」としてChatGPT上からBingを経由してウェブの最新情報にアクセスすることができます。また、Webpilotというプラグインを使用しても同じようにウェブの情報を検索できます。
これは、RAG(Retrieval Augmented Generation)という技術で成り立っています。RAGは、ユーザからの質問に回答するために必要そうな内容が書かれた文章を検索し、その文章をLLMへの入力(プロンプト)に付け加えて渡す手法です。具体例を用いて回答生成までの流れを説明すると、
ユーザーがプロ野球の結果について質問
対話型AI検索エンジンがウェブ上でプロ野球の結果を検索
試合結果とユーザーからの質問を組み合わせたプロンプトをバックエンドで作成
プロンプトをLLMへ渡す
LLMがユーザーへの回答を生成し提示

引用を防ぐ方法
ここまで見てきた通り、対話型検索AIエンジンはクエリに対してウェブを検索しその結果を回答の情報源にしています。そのため、対話型検索AIエンジンによる引用を防ぐためには、「検索結果に自社コンテンツが含まれない」ようにするしかありません。しかしこれをすると、当然通常の検索結果にも自社サイトが表示されないことになってしまい、トラフィック観点で大きな打撃を受けてしまいます。そのため、基本的に「対話型検索AIエンジンによる引用を防ぐ現実的な方法は、現状存在しない」ということになります。
ただし、Microsoftが提供しているBing Chatのみは例外です。NOARCHIVEタグをつけることで、Bing Chatの回答に引用されるのを防ぐことができます。もしくはNOCACHEタグをつけることで、引用される内容を「URL/スニペット/タイトルのみ」に制限することができます(Bing Blog)。
利用規約の実効性
対策として真っ先に思いつくのが、ニュースサイトの利用規約での規定でしょう。例えば、朝日新聞デジタルは利用規約上で明確にコンテンツのスクレイピングやAI学習への利用を禁止しています。
デジタル版について、当社の事前の書面による許可なく、データマイニング、ロボット等によるデータの収集、抽出、解析または蓄積等をする行為 、およびAIの開発・学習・利用またはその他の目的のために、情報・データの収集、抽出、解析または蓄積等をする行為
しかし、AI企業側がこれを遵守しているとは言えないのが実態です。例えば、Common Crawlには朝日新聞のコンテンツが多数含まれています。

以上より、利用規約には「一定の抑止効果はあるものの、実効性は不十分」であるということができます。
Liquid Studioについて

Liquid Studioは、メディアエンタメ業界に特化した併走型コンサルティングスタジオです。生成AIなどの先端テクノロジーに強みを持ち、ビジネスと技術の両面からハンズオンでご支援致します。これまで、大手新聞社やデジタルニュースメディア、エンタメ系スタートアップ、雑誌社など多数の企業様に対し、社内セミナーや技術導入、戦略提案、オペレーション構築など多角的な支援を提供してきました。
HP: https://www.liquidstudio.biz/
この記事が気に入ったらサポートをしてみませんか?