
Snowflake入門

Slack、Notionなどと一緒に最近よく聞くようになったSnowflake。
TredureDataなどと同様にクラウドのデータウェアハウスであるが、何が違うのか、どのような特徴があるのか調査した。
Snowflakeとは
クラウド型のデータウェアハウス。
従量課金制のためスケーラビリティに優れており、Azure, AWS, GCPと連携してデータ格納ができる。
メリット
スケーラビリティ(従量課金制、WH制)
クラウド(インストールやハードウェア必要ない)
ストレージと実行環境を分けることでデータのサイロ化を防ぐ
非構造化データの管理も可能(python UDFsなどを使って分析もできる)
デメリット
ユーザビリティ(アドオン、テーブル作成)
ルールしっかりしている分、ユーザーの知識が求められる
例)ロールの切り替えがめんどくさい、テーブル作成時間違ってしまう(テーブル作成時)
画像やPDFなどの非構造データの扱い
単なる資料の管理はNotionの方が専門知識必要なく使える。
一方でSnowflakeではpython UDFsを使って分析などができるのでデータ分析、画像・音声解析といった事項をやりたい場合はSnowflakeで一括管理した方がよさそう。
日本語のサポート資料が少ない
「ESS-DWW Badge 1: Data Warehousing Workshop」とは
Snowflakeが提供する無料の講座。
だいたいコースすべてを終えるのに2営業日程かかる。
コースの中ではSnowflakeを使ったデータの格納、DB,テーブルの作成、データの抽出などの方法を学ぶことができる。
テストのSnowflakeアカウントを作ってそこで実習を行うため実際にどのような機能があるのか、ユーザビリティはどうなのかなど確かめることができる。
またコース終了時にはバッジが配布される。
SnowflakeUI画面の説明は講座内で詳細な説明ないので公式ページを参照
https://docs.snowflake.com/ja/user-guide/ui-snowsight-quick-tour.html
Role(権限関係)
認証(Authenticated): 自分の身分を証明できること
認可(Authorized): 何かにアクセスする権利があることを証明できること
Snowflakeではログインで認証を行い
ロールベースアクセスコントロール(RBAC)で認可を行っている
(セキュリティ、ユーザーアドミン、システムアドミンなど役割毎に権限を変える)
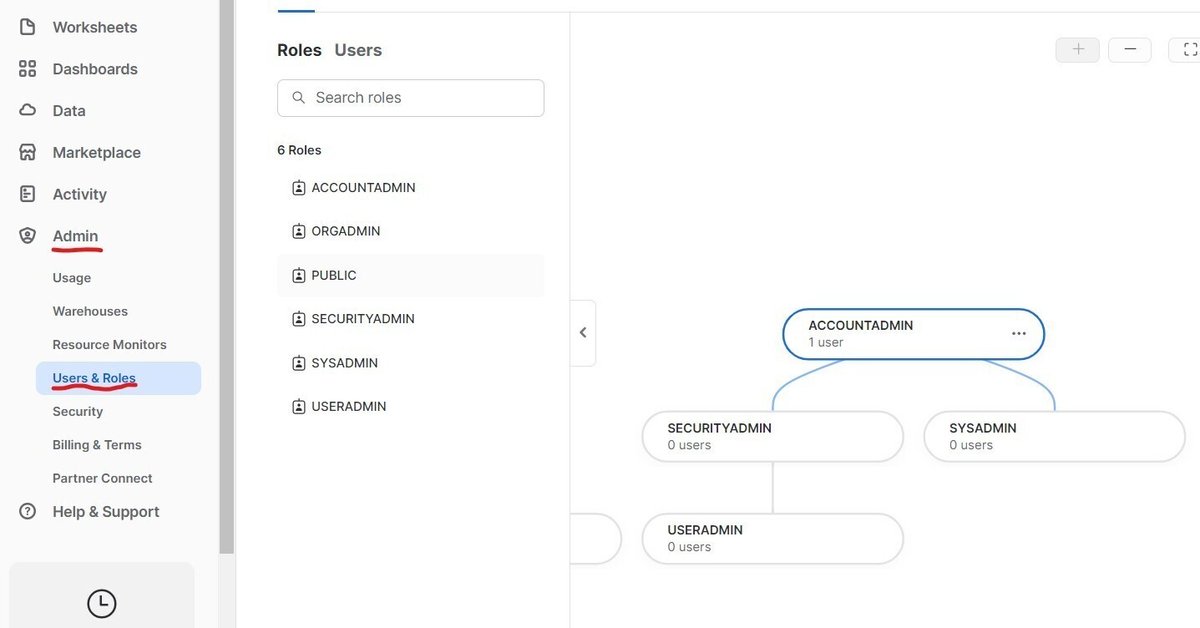
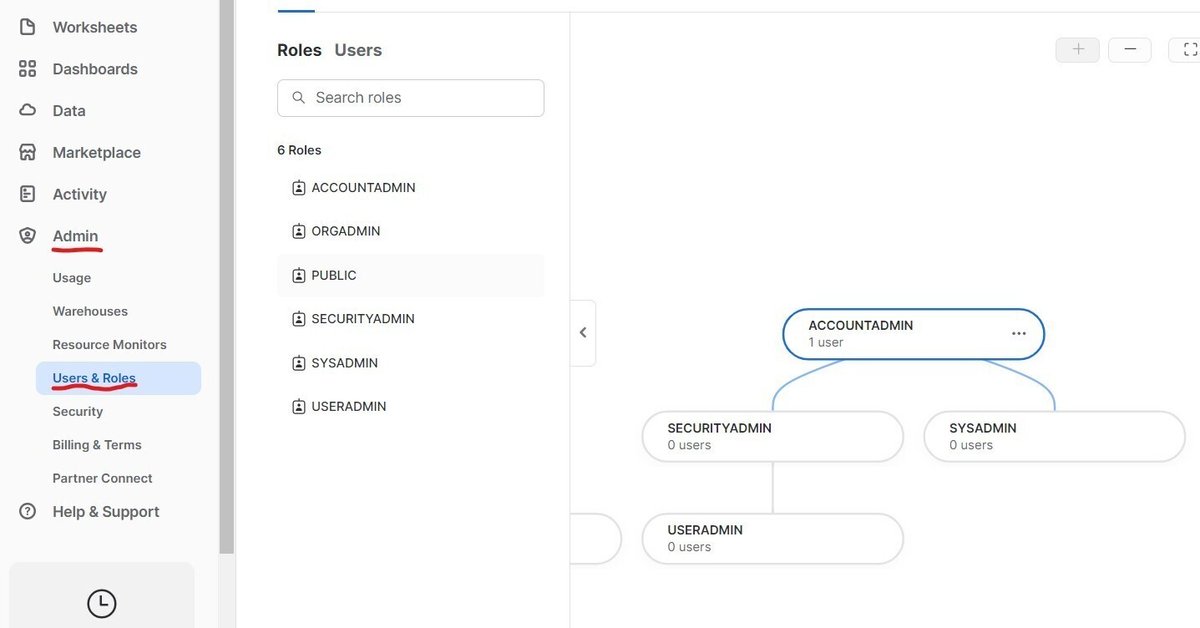
ロール設定はAdmin → Users & Rolesから確認できる。
親は子の権限を全て持っている。(子のロールを選ぶことができる)
例えば上記では「AccountAdmin」が親、「SecurityAdmin」、「SysAdmin」が子である。
この場合、AccountAdmin権限を持っていればSysAdminのロールを使うこともできる。
※ロールを変更した後、一度画面の再読み込みを行わないとロールが反映されない
また新規作成されたDBはそのロールに対して権限付与される。(作成後もData画面からロールの権限も設定可能)
Data(データの管理関係)
データベースの階層構造
DB>スキーマ>テーブルに分かれている。以下のようなイメージ。
DB=ファイル
スキーマ=SSファイル
テーブル=SSシート
Tables
通常のテーブル。実際にデータを保持している。
Table Details
テーブル作成に使用したクエリとテーブルの権限設定が確認できる
Columns
カラムの一覧を確認できる。データ型、null可能かなど詳細設定も確認できる。
Data Preview
テーブル内のデータを確認できる。毎回プレビュー作成するためWHの実行が必要。
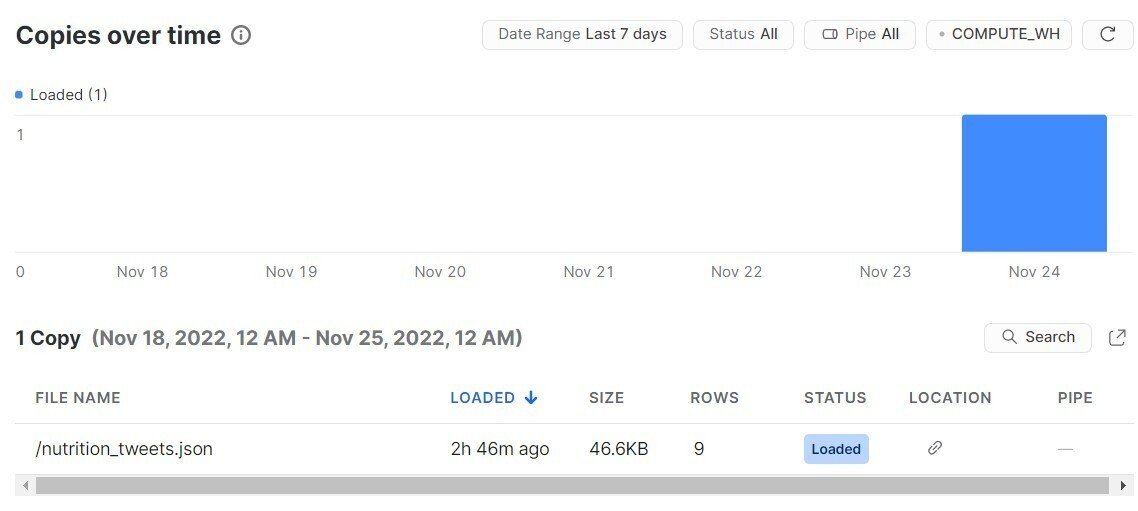
Copy History
テーブルに対するデータの追加、削除、編集などの履歴を確認できる

Views
テーブルと異なりデータを保持していない。毎回内容確認のためにWHの実行が必要。
Stages
S3との連携のための設定情報が格納されている
DB作成時に自動作成される2つのスキーマ
INFORMATION_SCHEMA(公式)
削除、移動、名前の変更が不可能
データベースに含まれるすべてのオブジェクトのビュー、およびアカウントレベルのオブジェクト(ロール、ウェアハウス、データベースなどの非データベースオブジェクト)のビュー
アカウント全体の履歴データと使用データのテーブル関数。
PUBLIC
削除、移動、名前の変更が可能
ワークシート
コードを記述、実行、保存、共有できる場所
クエリ実行時
RoleとWHは必須で指定
DB、スキーマはオプショナル(fromで直書きでもOK)
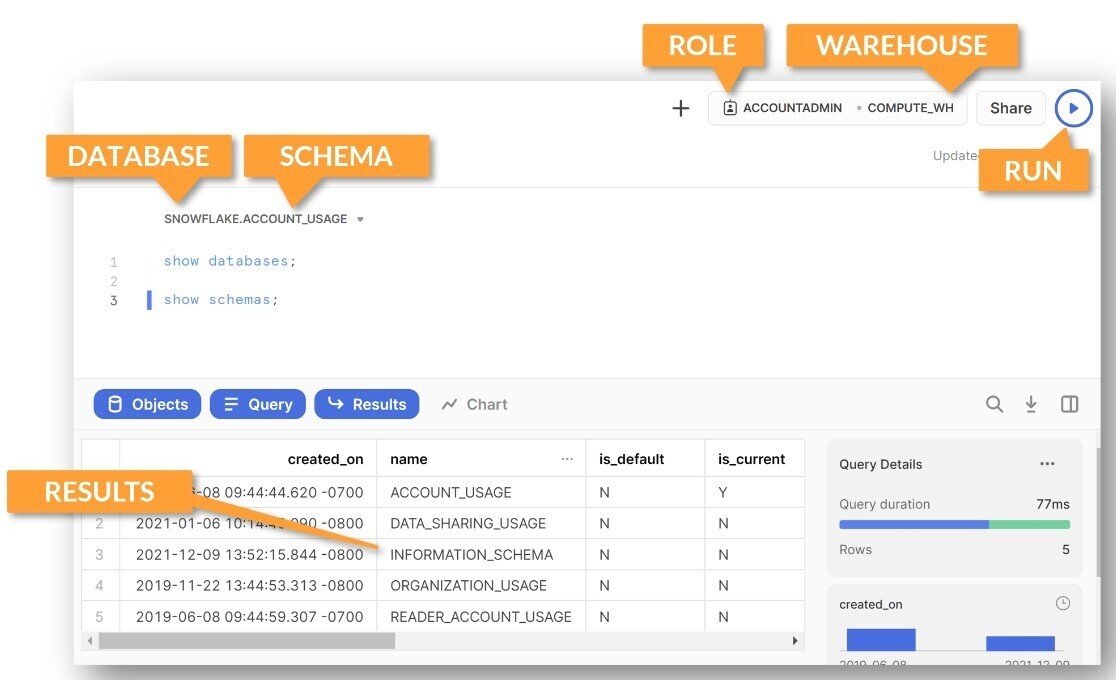
2つ以上のクエリがかかれているときは、
記入現在地の行、または次の「;」があるクエリが実行される。
実行後はスクショのように実行されたクエリの左が青くなる。


show databases;
データベース一覧を表示できる
show schemas;
選んでいるデータベースのスキーマを表示
show schemas IN ACCOUNT;
現在のロールに閲覧権限のあるすべてのスキーマを表示
データの格納:UI操作
csvデータの格納
Help&Supportからデータ格納が可能。
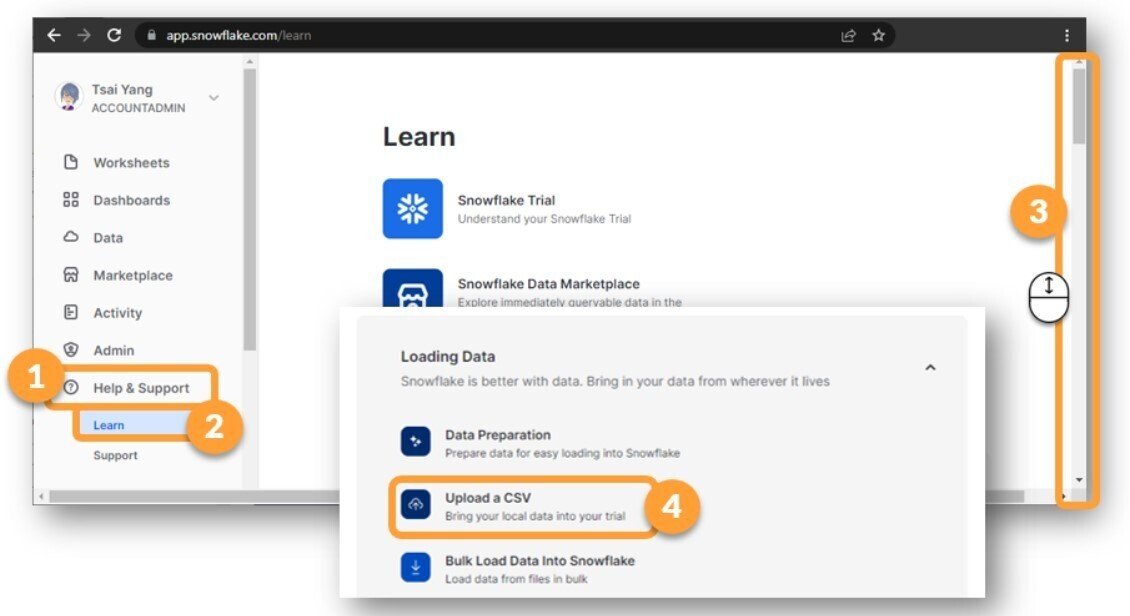
裏側のデータ格納フロー
1,PUTでいったんcsvデータを格納
2,1で格納したデータを指定先のテーブルにCOPY INTO
3,1で作成したテーブルを削除
データの格納:クエリ操作
クラウドストレージ:AmazonS3, GCP, Azureと連携できる
スキーマ内の「Stages」に実際にクラウドストレージとやり取りするための設定ファイルを格納する。
クラウドストレージからのデータ読み込み手順
stagesにS3へのリンクを登録
テーブルの作成
格納フォーマットの定義(FMTファイル作成)
copy into関数でデータのコピー
StagesにS3へのリンクを登録
S3側でバケットというものを用意してリンクURLの発行が必要。
講座はSnowflakeの演習のためその作業は省略。
以下コードを実行しStagesのテーブル作成
create stage db_name.schema_name.stages_name
url = 's3のバケットURL';実際に作成されたファイル内容
name: S3内のどこにあるかリンク情報
size: ファイルサイズ
md5: S3へアクセスするためのハッシュ情報
last_modified: 最終編集時間

テーブルの作成
//データ格納先のテーブルの作成
create or replace table table_name(
--以下カラムとデータ型の定義
plant_name varchar(25),
UOM varchar(1),
Low_End_of_Range number,
High_End_of_Range number
);格納フォーマットの定義(FMTファイル作成)
//FMTファイルの作成(読み込むデータ形式、ヘッダーの有無など)
create file format db_name.schema_name.fmt_file_name
TYPE = 'CSV'--file fmt
FIELD_DELIMITER = ',' --区切り文字
SKIP_HEADER = 1 --ヘッダーの場所
FIELD_OPTIONALLY_ENCLOSED_BY = '"' --this means that some values will be wrapped in double-quotes bc they have commas in them ;copy into関数でデータのコピー
//S3からデータのコピー
copy into table_name
from @stages_name --stagesに作ったファイル名を指定
files = ( 'file_name.csv') --s3のファイル名を指定
file_format = ( format_name=fmt_file_name); --上で作成したfmtのファイル名を指定データストレージ
プレゼンテーションレイヤ
ユーザーに表示されるUI画面
ストレージレイヤ
プレゼンテーションレイヤ表示のために裏側で情報保持している層
ERD(エンティティリレーションシップダイヤグラム)として可視化されたりする。
エンティティ
主キー(ユニークID)
主キーが定性情報だったりすると別でIDを作ることもある。主キーの変更がされたとき書き換えが必要だったりするため
アトリビュート(属性)
リレーションシップ
エンティティ同士の関係や紐づけのこと
正規化の定義
エンティティがちゃんと分かれている
ユニークIDが決まっている
同じ情報が重複していない
SnowflakeにはsequenceというユニークIDを割り振る機能がある
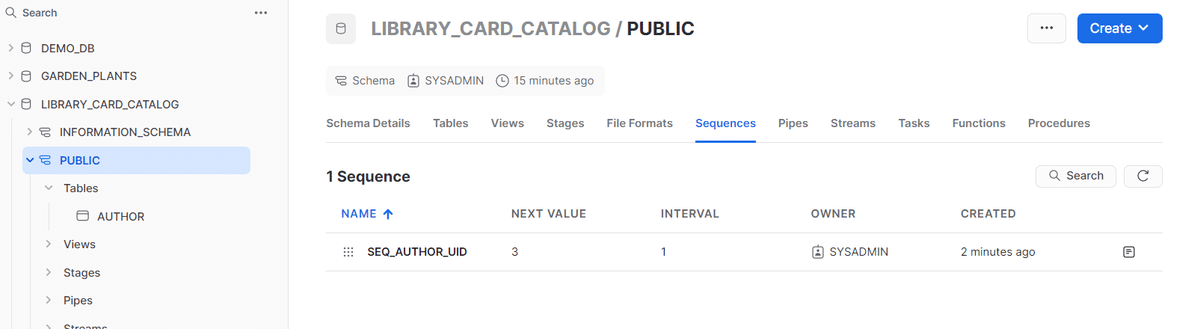
sequencesは上の画面のcreateか以下のコードを実行することで設定ファイルを作ることができる。
//コードからsequencesの作成
CREATE OR REPLACE SEQUENCE "db_name"."schema_name"."table_name"
START 3 --何番から数え始めるか
INCREMENT 1 --数字をいくつづつ追加していくか
COMMENT = 'Use this to fill in the AUTHOR_UID every time you add a row';sequenceの機能の使い方
//SEQ_AUTHOR_UID.nextvalを変数として指定することでUIDとして格納できる
INSERT INTO AUTHOR(AUTHOR_UID,FIRST_NAME,MIDDLE_NAME, LAST_NAME)
Values
(SEQ_AUTHOR_UID.nextval, 'Laura', 'K','Egendorf')
,(SEQ_AUTHOR_UID.nextval, 'Jan', '','Grover')
,(SEQ_AUTHOR_UID.nextval, 'Jennifer', '','Clapp')
,(SEQ_AUTHOR_UID.nextval, 'Kathleen', '','Petelinsek');半構造化データ
非構造化データにタグなど属性をつけて構造化データとして扱えるようにしたもの
JSON型のデータについては取り出したりするのに専用の関数使ったりする必要あり。(XMLGETなど)
XMLデータの扱い方

カラムの後に”$”をつけるとxmlの形式を分解し、配列配下に連想配列を格納した形式になる

”@”+カラム名を指定するとバリューだけを取り出せる(数値カラムの場合)
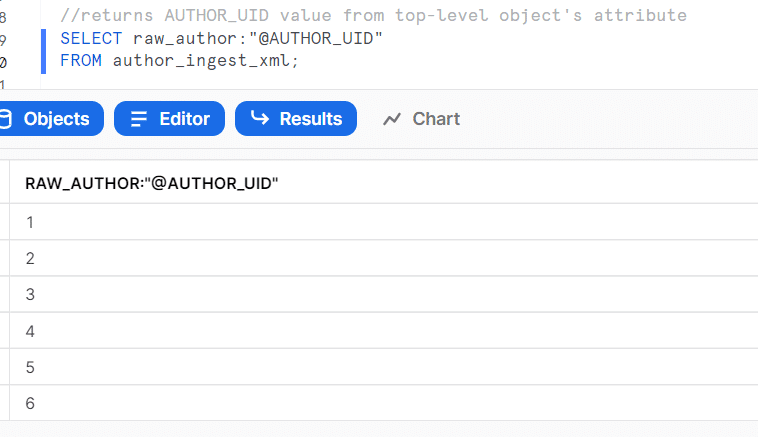
xmlget関数を使うと<xxx>ごとにデータを取り出すことができる
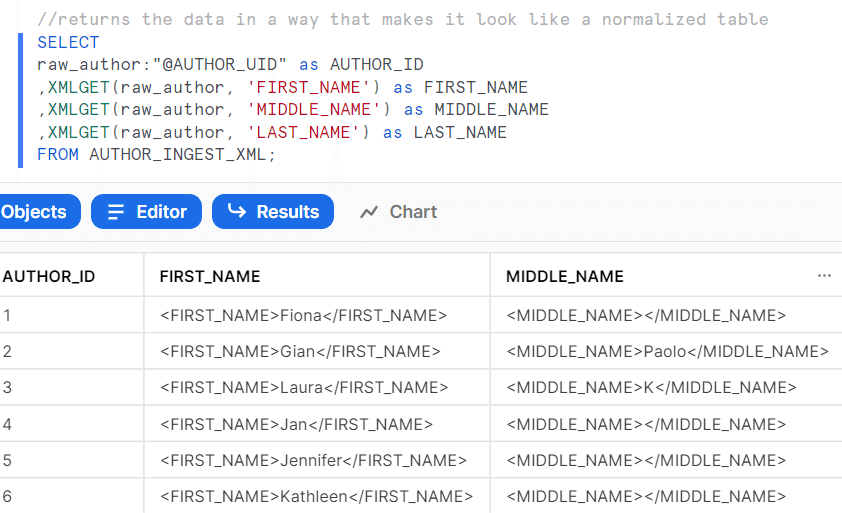
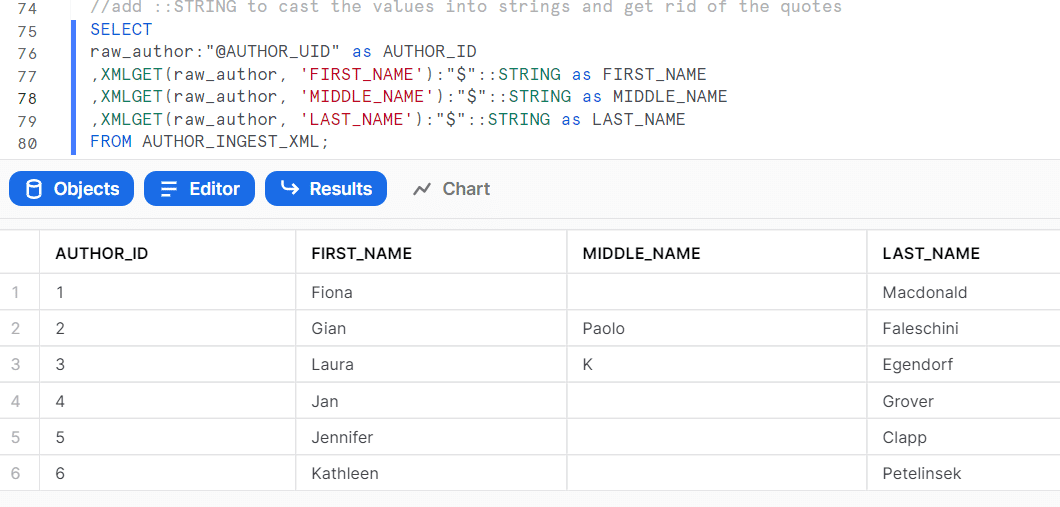
xmlget関数に$を合わせることでバリューデータだけを取り出せる

文字型データについてデータ型の指定を行うと「””」を消すことができる
※「::」はCAST関数の代わり
JSONデータの扱い方
Snowflakeではエンティティは読み込み順ではなく、昇順に並び変わっている

JSON形式のデータ出力
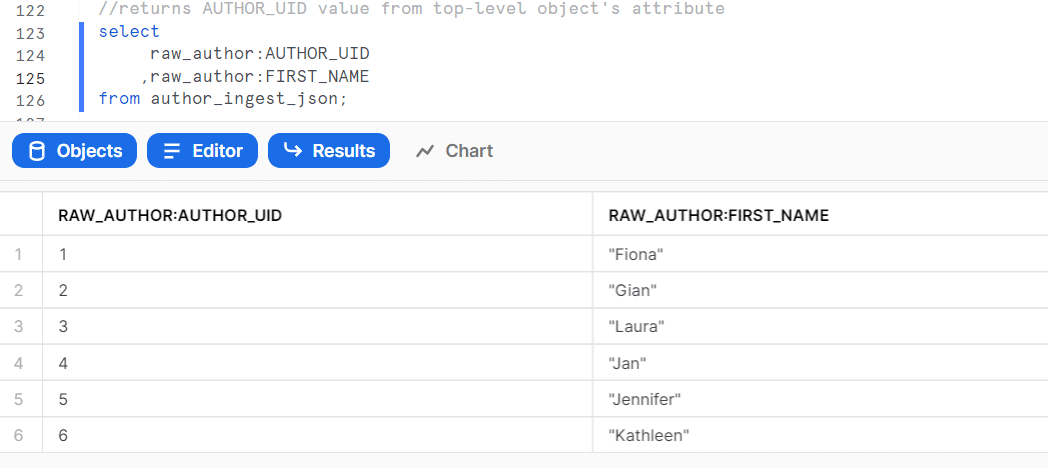
xml同様 文字型はstringの指定をすることで「””」を消すことが可能

ネスト:階層構造の扱い方
2層以上のJSONを扱う
下のスクショではauthorsの配下にfirst_name, last_nameなどのデータがネストされている

JavascriptでJSONを扱うのと同じような感覚でデータの指定ができる
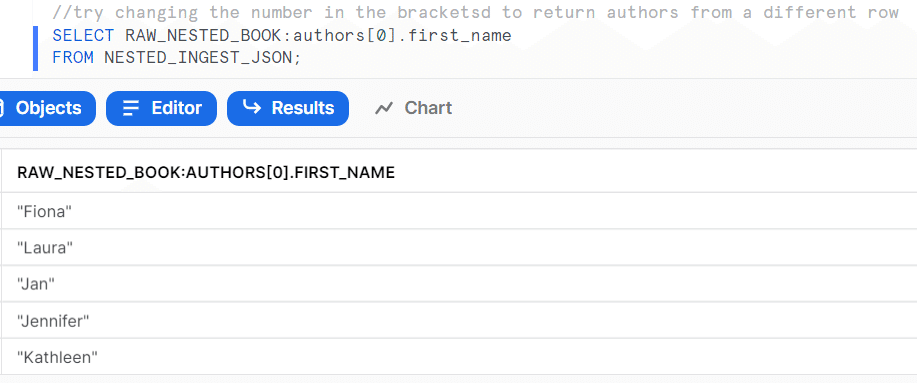
flatten関数を使うと特定階層のデータだけを取り出せる。
その階層にエンティティが2つ以上あったときは別レコードとして表示される。seqがt\元のレコード行数、indexが配列の何番目の要素かを表している。

valueに取り出された階層データが入っている。
データ型などを指定すると以下のようにデータを取り出せる。

補足:ビューの作成方法
create or replace view "db_name"."schema_name"."table_name" as
(
//ビューを作成するためのSQL文
);UDFs(組込関数)について
ユーザーが自由に設定できる関数のこと。(公式ページ)
画像、音声、動画を分析したい場合
Snowflakeでメタデータを管理、外部ストレージ内で上記のような非構造化データを管理。
外部関数を使うことで以下のようなことが可能になる。(参考サイト)
画像からテキストを抽出する
機械学習サービスを使用して画像を処理し、ラベルを認識する
PDFファイルを処理してキー/値ペアを抽出する
総評
Snowflakeの講座を通して一通りの使い方と機能を知ることができた。
講座自体は実際に手を動かしながら進めることができたため内容を理解しやすかった。一方で少し説明不足な部分は一部の講座であると感じた。
Snowflakeの機能について
使い方や構造などがしっかり決まっているためあらかじめユーザーに知識が求められると感じた。
特に講座内ではロールによる権限付与についてテーブル作成する際に見落としてしまうことが多く、作成したはずのテーブルが見つからないということがよくおこった。
一方でテーブル、ビュー、ステージ、テーブルフォーマットなどテーブルを作成する際に必要な情報やメタデータが可視化されている点は好印象だった。
SQLを書いている際にカラム定義やNullの有無はどうなっているのか、データ元や更新頻度はどうなっているかなど毎回調査しなくても確認できる点が優れていると感じた。
【memo】
・Pythonとの連携 (参考サイト)
Snowflake内でデータ分析、可視化までできるようになればやれることもっと広がりそう。
一方でSnowflake内でそれらの処理を行うことでメインのデータ管理が重くならないか、コストが跳ね上がらないかなど調査は必要そう。
実際にJupyterNotebookでのデータ分析を行っている動画
JupyterNotebookだとCPUがローカルPCのキャパに左右される。
Pythonコネクタを利用してGoogle Colaboratoryと連携すればクラウドを利用したデータ分析を行うことができる。
参考サイト:https://qiita.com/foursue/items/51920be756f1a0ab0bb7
・SnowVillage:Snowflakeに関するYoutubeチャンネル
dbtの導入など3rd partyツールの情報や実際の導入事例などがある。
・クラスメソッド:Youtubeチャンネル
Snowflakeやdbtの機能について分かりやすくまとまっている
https://www.youtube.com/watch?v=GGHHmClkwB8
この記事が気に入ったらサポートをしてみませんか?