
TensorFlowで強ノイズ文字列画像から1文字ずつ取り出す話

※全文無料です。
1. データセットの作成
前回はノイズのある文字列画像から文字数の読み取りを行いましたが、今回はよりノイズの強い文字列画像から文字ごとにラベルを付けて取り出すプログラムを書きます。
まずは画像データを生成していきましょう。ついでにTensorFlowやPathlibもimportしておきます。
from PIL import Image, ImageDraw, ImageFont
import string
import numpy as np
import pathlib
import tensorflow as tf
def noise(x):
y = np.where(x < 150, x + 150, x) - np.random.randint(0, 150, 64*64).reshape(64, 64)
return y
syms = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J']
color = list(range(1, 11))
font = ImageFont.truetype('times.ttf', 20)
for seq in range(50000):
im_str = Image.new("L", (64, 64), 0)
draw_str = ImageDraw.Draw(im_str)
im_str_col = Image.new("P", (64, 64), 0)
draw_str_col = ImageDraw.Draw(im_str_col)
c = np.random.randint(1,5)
for i in range(c):
sym = np.random.randint(0, 10)
xy = np.random.randint(0, 25, 2)
draw_str.text(xy, syms[sym], font=font, fill=255)
im_str = Image.fromarray(np.rot90(im_str))
draw_str = ImageDraw.Draw(im_str)
draw_str_col.text(xy, syms[sym], font=font, fill=color[sym])
im_str_col = Image.fromarray(np.rot90(im_str_col))
draw_str_col = ImageDraw.Draw(im_str_col)
im_str.save('sni2/label/label/'+'{:0=10}'.format(seq)+'.png')
im_str_col.convert('P').save('sni3/label/label/'+'{:0=10}'.format(seq)+'.png')
im_str = np.uint8(noise(np.array(im_str)))
Image.fromarray(im_str).save('sni1/im/im/'+'{:0=10}'.format(seq)+'.png')アルファベット52文字にラベルを付けるのは、データセットの規模が膨大になりすぎるため、大文字の最初の10文字のみを使うことにしました。領域分割に使うほうのラベル画像には、文字に対応した1から10のラベルを、ピクセルごとに付与していきます。出力される画像は次のようになるはずです。



3番目の画像は全て真っ黒に見えますが、実際には0~10の輝度がラベルとして記録されています。
では、モデルに流し込むためのジェネレータを作っていきましょう。
class DatasetGenerator(tf.keras.utils.Sequence):
def __init__(self, image_path, label1_path, label2_path):
self.image = image_path
self.label1 = label1_path
self.label2 = label2_path
self.indices = np.arange(50000)
self.length = 50000
self.batch_size = 16
def __getitem__(self, idx):
idx_shuffle = self.indices[idx * self.batch_size:(idx + 1) * self.batch_size]
image_batch_path = []
label1_batch_path = []
label2_batch_path = []
for i in idx_shuffle:
image_batch_path.append(self.image[i])
label1_batch_path.append(self.label1[i])
label2_batch_path.append(self.label2[i])
image_batch = []
for path in image_batch_path:
image_batch.append(np.array(Image.open(path)))
label1_batch = []
for path in label1_batch_path:
label1_batch.append(np.array(Image.open(path)))
label2_batch = []
for path in label2_batch_path:
label2_batch.append(np.array(Image.open(path)))
image_batch = np.reshape(np.array(image_batch)/255.0, (self.batch_size, 64, 64, 1))
label1_batch = np.reshape(np.array(label1_batch)/255.0, (self.batch_size, 64, 64, 1))
label2_batch = np.reshape(np.array(label2_batch), (self.batch_size, 64, 64, 1))
return image_batch, label1_batch, label2_batch
def __len__(self):
return self.length//self.batch_size
def on_epoch_end(self):
np.random.shuffle(self.indices)ラベル2のチャンネル数を1として、さらに画素値の正規化をしないようにします。こうすることで、ラベル2を0から10のラベルを座標ごとに割り当てられた配列として扱うことになります。
image_root = pathlib.Path('sni1/im/')
all_image_paths = list(image_root.glob('*/*'))
all_image_paths = [str(path) for path in all_image_paths]
label1_root = pathlib.Path('sni2/label/')
all_label1_paths = list(label1_root.glob('*/*'))
all_label1_paths = [str(path) for path in all_label1_paths]
label2_root = pathlib.Path('sni3/label/')
all_label2_paths = list(label2_root.glob('*/*'))
all_label2_paths = [str(path) for path in all_label2_paths]ファイルの開き方に関しては、今回は画像ファイルのみなので、パスを参照するだけで十分です。
2. モデルの構築
今回のモデルの大枠には、「ノイズ除去器→画像補間器→画像分割器」の順に3つのモデルを入れ込みます。ノイズの強度が高いため、ノイズを除去した後に画像を復元するネットワークを挟むことで、画像分割の精度を上げていきます。具体的には次のようにコードを書きました。
class segmentation_noisy_image(tf.keras.Model):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.noise_clean = self.create_noise_clean()
self.recovery = self.create_recovery()
self.segmentation = self.create_segmentation()
self.accuracy_nc = tf.keras.metrics.BinaryAccuracy(name='nc_loss')
self.accuracy_rec = tf.keras.metrics.BinaryAccuracy(name='rec_loss')
self.accuracy_seg = tf.keras.metrics.SparseCategoricalAccuracy(name='seg_loss')
def compile(self, nc_optimizer, rec_optimizer, seg_optimizer):
super().compile()
self.nc_optimizer = nc_optimizer
self.rec_optimizer = rec_optimizer
self.seg_optimizer = seg_optimizer
@property
def metrics(self):
return [self.accuracy_nc, self.accuracy_rec, self.accuracy_seg]
def create_noise_clean(self):
im_input1 = tf.keras.layers.Input(shape=(64, 64, 1))
conv1 = tf.keras.layers.Conv2D(32, (3, 3), padding='same')(im_input1)
conv1 = tf.keras.layers.BatchNormalization()(conv1)
conv1 = tf.keras.layers.Activation('relu')(conv1)
conv2 = tf.keras.layers.Conv2D(64, (5, 5), padding='same')(conv1)
conv2 = tf.keras.layers.BatchNormalization()(conv2)
conv2 = tf.keras.layers.Activation('relu')(conv2)
conv2_gate = tf.keras.layers.Conv2D(64, (5, 5), padding='same')(conv1)
conv2_gate = tf.keras.layers.BatchNormalization()(conv2_gate)
conv2_gate = tf.keras.layers.Activation('sigmoid')(conv2_gate)
mul_conv2 = tf.multiply(conv2, conv2_gate)
conv3 = tf.keras.layers.Conv2D(64, (3, 3), padding='same')(conv1)
conv3 = tf.keras.layers.BatchNormalization()(conv3)
conv3 = tf.keras.layers.Activation('relu')(conv3)
conv3_gate = tf.keras.layers.Conv2D(64, (3, 3), padding='same')(conv1)
conv3_gate = tf.keras.layers.BatchNormalization()(conv3_gate)
conv3_gate = tf.keras.layers.Activation('sigmoid')(conv3_gate)
mul_conv3 = tf.multiply(conv3, conv3_gate)
conv4 = tf.keras.layers.Conv2D(64, (1, 1), padding='same')(conv1)
conv4 = tf.keras.layers.BatchNormalization()(conv4)
conv4 = tf.keras.layers.Activation('relu')(conv4)
conv4_gate = tf.keras.layers.Conv2D(64, (1, 1), padding='same')(conv1)
conv4_gate = tf.keras.layers.BatchNormalization()(conv4_gate)
conv4_gate = tf.keras.layers.Activation('sigmoid')(conv4_gate)
mul_conv4 = tf.multiply(conv4, conv4_gate)
add = tf.keras.layers.add([mul_conv2, mul_conv3, mul_conv4])
add = tf.keras.layers.Activation('relu')(add)
nc_out = tf.keras.layers.Conv2D(1, (1, 1), activation='sigmoid', padding='same')(add)
return tf.keras.models.Model(im_input1, nc_out)
def create_recovery(self):
im_input2 = tf.keras.layers.Input(shape=(64, 64, 1))
conv1 = tf.keras.layers.Conv2D(32, (5, 5), padding='same')(im_input2)
conv1 = tf.keras.layers.BatchNormalization()(conv1)
conv1 = tf.keras.layers.Activation('relu')(conv1)
conv2 = tf.keras.layers.Conv2D(64, (9, 9), padding='same')(conv1)
conv2 = tf.keras.layers.BatchNormalization()(conv2)
conv2 = tf.keras.layers.Activation('relu')(conv2)
conv2_gate = tf.keras.layers.Conv2D(64, (5, 5), padding='same')(conv1)
conv2_gate = tf.keras.layers.BatchNormalization()(conv2_gate)
conv2_gate = tf.keras.layers.Activation('sigmoid')(conv2_gate)
mul_conv2 = tf.multiply(conv2, conv2_gate)
conv3 = tf.keras.layers.Conv2D(64, (5, 5), padding='same')(conv1)
conv3 = tf.keras.layers.BatchNormalization()(conv3)
conv3 = tf.keras.layers.Activation('relu')(conv3)
conv3_gate = tf.keras.layers.Conv2D(64, (3, 3), padding='same')(conv1)
conv3_gate = tf.keras.layers.BatchNormalization()(conv3_gate)
conv3_gate = tf.keras.layers.Activation('sigmoid')(conv3_gate)
mul_conv3 = tf.multiply(conv3, conv3_gate)
conv4 = tf.keras.layers.Conv2D(64, (3, 3), padding='same')(conv1)
conv4 = tf.keras.layers.BatchNormalization()(conv4)
conv4 = tf.keras.layers.Activation('relu')(conv4)
conv4_gate = tf.keras.layers.Conv2D(64, (3, 3), padding='same')(conv1)
conv4_gate = tf.keras.layers.BatchNormalization()(conv4_gate)
conv4_gate = tf.keras.layers.Activation('sigmoid')(conv4_gate)
mul_conv4 = tf.multiply(conv4, conv4_gate)
add = tf.keras.layers.add([mul_conv2, mul_conv3, mul_conv4])
add = tf.keras.layers.Activation('relu')(add)
rec_out = tf.keras.layers.Conv2D(1, (1, 1), activation='sigmoid', padding='same')(add)
return tf.keras.models.Model(im_input2, rec_out)
def create_segmentation(self):
im_input3 = tf.keras.layers.Input(shape=(64, 64, 1))
conv1 = tf.keras.layers.Conv2D(32, (5, 5), padding='same')(im_input3)
conv1 = tf.keras.layers.BatchNormalization()(conv1)
conv1 = tf.keras.layers.Activation('relu')(conv1)
conv2 = tf.keras.layers.Conv2D(128, (5, 5), padding='same')(conv1)
conv2 = tf.keras.layers.BatchNormalization()(conv2)
conv2 = tf.keras.layers.Activation('relu')(conv2)
conv3 = tf.keras.layers.Conv2D(64, (5, 5), padding='same')(conv1)
conv3 = tf.keras.layers.BatchNormalization()(conv3)
conv3 = tf.keras.layers.Activation('relu')(conv3)
conv4 = tf.keras.layers.Conv2D(32, (5, 5), padding='same')(conv1)
conv4 = tf.keras.layers.BatchNormalization()(conv4)
conv4 = tf.keras.layers.Activation('relu')(conv4)
conv2_1 = tf.keras.layers.Conv2D(256, (5, 5), padding='same')(conv1)
conv2_1 = tf.keras.layers.BatchNormalization()(conv2_1)
conv2_1 = tf.keras.layers.Activation('relu')(conv2_1)
conv_con2 = tf.keras.layers.Concatenate(axis=-1)([conv2, conv2_1])
conv3_1 = tf.keras.layers.Conv2D(128, (5, 5), padding='same')(conv_con2)
conv3_1 = tf.keras.layers.BatchNormalization()(conv3_1)
conv3_1 = tf.keras.layers.Activation('relu')(conv3_1)
conv_con3 = tf.keras.layers.Concatenate(axis=-1)([conv3, conv3_1])
conv4_1 = tf.keras.layers.Conv2D(64, (5, 5), padding='same')(conv_con3)
conv4_1 = tf.keras.layers.BatchNormalization()(conv4_1)
conv4_1 = tf.keras.layers.Activation('relu')(conv4_1)
conv_con4 = tf.keras.layers.Concatenate(axis=-1)([conv4, conv4_1])
seg_out = tf.keras.layers.Conv2D(11, (1, 1), activation='softmax', padding='same')(conv_con4)
return tf.keras.models.Model(im_input3, seg_out)
def train_step(self, gen_image_label):
images, labels1, labels2 = gen_image_label
with tf.GradientTape() as tape1, tf.GradientTape() as tape2, tf.GradientTape() as tape3:
predictions_nc = self.noise_clean(images)
loss_nc = tf.keras.losses.binary_crossentropy(labels1, predictions_nc)
gradients_nc = tape1.gradient(loss_nc, self.noise_clean.trainable_variables)
self.nc_optimizer.apply_gradients(zip(gradients_nc, self.noise_clean.trainable_variables))
self.accuracy_nc.update_state(labels1, predictions_nc)
predictions_rec = self.recovery(predictions_nc)
loss_rec = tf.keras.losses.binary_crossentropy(labels1, predictions_rec)
gradients_rec = tape2.gradient(loss_rec, self.recovery.trainable_variables)
self.rec_optimizer.apply_gradients(zip(gradients_rec, self.recovery.trainable_variables))
self.accuracy_rec.update_state(labels1, predictions_rec)
predictions_seg = self.segmentation(predictions_rec)
loss_seg = tf.keras.losses.sparse_categorical_crossentropy(labels2, predictions_seg)
gradients_seg = tape3.gradient(loss_seg, self.segmentation.trainable_variables)
self.seg_optimizer.apply_gradients(zip(gradients_seg, self.segmentation.trainable_variables))
self.accuracy_seg.update_state(labels2, predictions_seg)
return {'nc_loss': loss_nc, 'nc_accuracy': self.accuracy_nc.result(),
'rec_loss': loss_rec, 'rec_accuracy': self.accuracy_rec.result(),
'seg_loss': loss_seg, 'seg_accuracy': self.accuracy_seg.result()}
def test_step(self, gen_image_label):
images, labels1, labels2 = gen_image_label
predictions_nc = self.noise_clean(images)
loss_nc = tf.keras.losses.binary_crossentropy(labels1, predictions_nc)
self.accuracy_nc.update_state(labels1, predictions_nc)
predictions_rec = self.recovery(predictions_nc)
loss_rec = tf.keras.losses.binary_crossentropy(labels1, predictions_rec)
self.accuracy_rec.update_state(labels1, predictions_rec)
predictions_seg = self.segmentation(predictions_rec)
loss_seg = tf.keras.losses.sparse_categorical_crossentropy(labels2, predictions_seg)
self.accuracy_seg.update_state(labels2, predictions_seg)
return {'nc_loss': loss_nc, 'nc_accuracy': self.accuracy_nc.result(),
'rec_loss': loss_rec, 'rec_accuracy': self.accuracy_rec.result(),
'seg_loss': loss_seg, 'seg_accuracy': self.accuracy_seg.result()}
def call(self, z):
w = self.noise_clean(z)
v = self.recovery(w)
return [self.noise_clean(z), self.recovery(w), self.segmentation(v)]2.1 ノイズ除去器
ノイズ除去器の部分だけ取り出してグラフ化すると次のようになります。
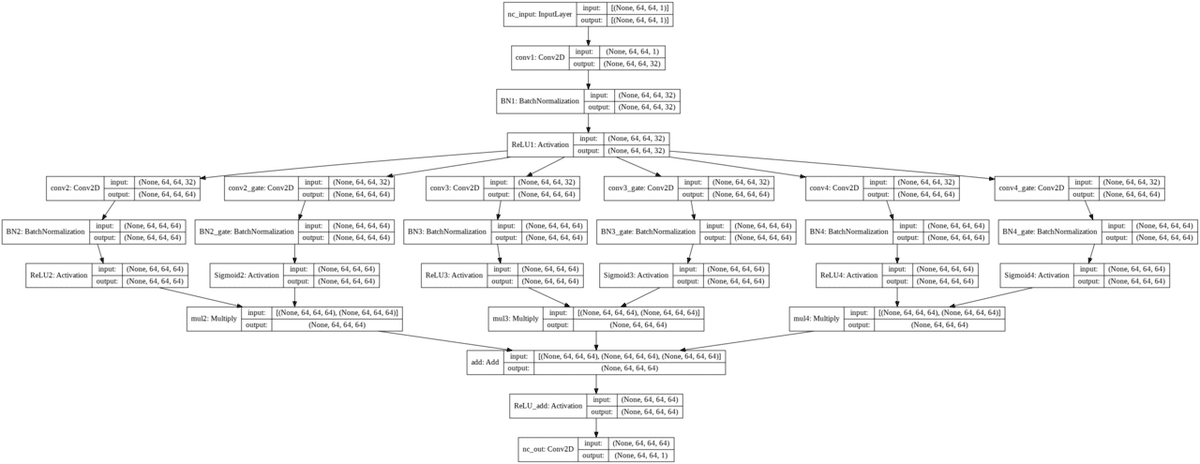
横長すぎて文字が読めないので1ブロックだけ切り出します。

画像のように入力層から、それぞれ畳み込み層とSigmoidゲート層にからなる3つのブロックに繋げています。この3つのブロックの違いは、畳み込み領域サイズの違いです。これらをAddレイヤーで足し合わせて連結します。
2.2 画像補間器
画像補間器の基本の構成はノイズ除去器と同じです。これらのネットワークの違いは、畳み込み領域サイズの違いです。ノイズ除去器の畳み込み領域はそれぞれ5×5、3×3、1×1としていたのですが、画像補間器では9×9、5×5、3×3としています。
2.3 画像分割器
画像分割器のモデルは次のグラフのようになります。

案の定サイズが大きいので1ブロックだけ切り出します。

畳み込みフィルターの違う2つの畳み込み層を、チャンネル方向で結合して次々に出力していく形です。最終的な出力層では文字数+背景色の計11チャンネルを出力します。
これをコンパイルしてfitします。
segmentation_noisy_image = segmentation_noisy_image()
segmentation_noisy_image.compile(
nc_optimizer = tf.keras.optimizers.Adam(lr=0.0001, epsilon=1e-06),
rec_optimizer = tf.keras.optimizers.Adam(lr=0.0001, epsilon=1e-06),
seg_optimizer = tf.keras.optimizers.Adam(lr=0.0001, epsilon=1e-06))
segmentation_noisy_image.fit(
DatasetGenerator(all_image_paths, all_label1_paths, all_label2_paths), epochs=20,
validation_data=DatasetGenerator(all_image_paths, all_label1_paths, all_label2_paths),
shuffle=False, steps_per_epoch=45000//16, validation_steps=5000//16)3. 学習結果と出力画像
エポックごとの学習結果は次のようになりました。
Epoch 1/20
2812/2812 [==============================] - 880s 311ms/step
- nc_loss: 0.0447 - nc_accuracy: 0.9544
- rec_loss: 0.0376 - rec_accuracy: 0.9551
- seg_loss: 0.1002 - seg_accuracy: 0.9571
- val_nc_loss: 0.0385 - val_nc_accuracy: 0.9636
- val_rec_loss: 0.0318 - val_rec_accuracy: 0.9644
- val_seg_loss: 0.0846 - val_seg_accuracy: 0.9732
Epoch 5/20
2812/2812 [==============================] - 975s 347ms/step
- nc_loss: 0.0321 - nc_accuracy: 0.9646
- rec_loss: 0.0250 - rec_accuracy: 0.9652
- seg_loss: 0.0332 - seg_accuracy: 0.9857
- val_nc_loss: 0.0279 - val_nc_accuracy: 0.9648
- val_rec_loss: 0.0218 - val_rec_accuracy: 0.9654
- val_seg_loss: 0.0312 - val_seg_accuracy: 0.9869
Epoch 10/20
2812/2812 [==============================] - 827s 294ms/step
- nc_loss: 0.0301 - nc_accuracy: 0.9649
- rec_loss: 0.0228 - rec_accuracy: 0.9656
- seg_loss: 0.0280 - seg_accuracy: 0.9887
- val_nc_loss: 0.0319 - val_nc_accuracy: 0.9646
- val_rec_loss: 0.0245 - val_rec_accuracy: 0.9654
- val_seg_loss: 0.0316 - val_seg_accuracy: 0.9893
Epoch 15/20
2812/2812 [==============================] - 878s 312ms/step
- nc_loss: 0.0283 - nc_accuracy: 0.9651
- rec_loss: 0.0216 - rec_accuracy: 0.9658
- seg_loss: 0.0231 - seg_accuracy: 0.9898
- val_nc_loss: 0.0268 - val_nc_accuracy: 0.9650
- val_rec_loss: 0.0205 - val_rec_accuracy: 0.9657
- val_seg_loss: 0.0268 - val_seg_accuracy: 0.9901
Epoch 20/20
2812/2812 [==============================] - 842s 299ms/step
- nc_loss: 0.0270 - nc_accuracy: 0.9652
- rec_loss: 0.0200 - rec_accuracy: 0.9659
- seg_loss: 0.0211 - seg_accuracy: 0.9905
- val_nc_loss: 0.0263 - val_nc_accuracy: 0.9653
- val_rec_loss: 0.0191 - val_rec_accuracy: 0.9660
- val_seg_loss: 0.0170 - val_seg_accuracy: 0.9905ちゃんとエポックごとにロスが減っていますね。画像を入れて確認してみましょう。
def noise(x):
y = np.where(x < 150, x + 150, x) - np.random.randint(0, 150, 64*64).reshape(64, 64)
return y
syms = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J']
font = ImageFont.truetype('times.ttf', 20)
im_str = Image.new("L", (64, 64), 0)
draw_str = ImageDraw.Draw(im_str)
c = np.random.randint(1,5)
for i in range(c):
sym = np.random.randint(0, 10)
xy = np.random.randint(0, 25, 2)
draw_str.text(xy, syms[sym], font=font, fill=255)
im_str = Image.fromarray(np.rot90(im_str))
draw_str = ImageDraw.Draw(im_str)
im_str = np.uint8(noise(np.array(im_str)))とすれば画像が1枚作成されます。これをモデルに入れて予測画像を見ていきます。まずは文字が1種類だけのパターン。

ノイズ画像から2段階で文字がはっきり切り出されていますね。文字ごとに切り出すには、予測リストの3つ目の要素を(64, 64, 11)とreshapeして一時変数に代入し、例えばEを取り出したいのであれば、そこから[:, :, 5]成分を画像化すればEのみの画像が取り出されるはずです。

他の文字も取り出せることを確認しましょう。


ややノイズがありますが、文字ごとに切り出せていますね。
次回の記事では、もっと現実の問題に適用できるような画像データを作成し、似たような動作を行う予定です。
ここから先は
¥ 100
この記事が気に入ったらサポートをしてみませんか?