
【画像生成AI】手書きラフ画からカラーイラスト作成のワークフロー

はじめに
text2img は、テキストを入力するだけで、フォトリアリスティックな画像から手書きイラスト風の画像まで、さまざまな画像データを生成することができ、筆者のような絵を描くのが下手な者でもパッと手軽にそれっぽい絵を作ることができるので、誰でも絵を描いた気分になることができる大変便利なツールです。
しかし、出来上がった画像は偶然によるところが大きく、キャラクターを指定して描くことが難しいので、例えばマンガのような同じキャラクターを何度も描く必要がある場合、text2imgを使って全体を仕上げようとすると、運よく使える画像を引き当てるまで、何度も何度も画像を生成し続けなくてはいけません。
しかし、text2img が純粋なノイズからテキストをヒントにノイズを除去しながら画像を生成するのに対して、img2img はベースになる画像に一旦ノイズを加えて、再度ノイズを除去することでテキストのヒントに沿った画像を生成しようとするもので、元の画像のイメージが生成画像にも反映されます。
従って、手書きのラフ画を img2img に渡すことで、クリーンアップ作業を AI に任せることができます。
例えばマンガを描く場合でも、img2img をうまく使えば、すべて手作業で行う場合に比べ、一コマ一コマの絵を素早く仕上げることができるはずです。
メモ帳とボールペン、スマホ、PC、GIMP、Stable Diffusion (AUTOMATIC1111版webui)、学習モデルとして Anything-V3.0 を使って、落書きからカラーイメージイラストの作成までを多少の試行錯誤はありながらも30分程度で終えることができたので、全体のワークフローを示します。
作業内容
落書きを描く
準備するもの:
メモ帳、ボールペン
お気軽に落書きを描きます。

デジタル化する
準備するもの:
スマホ、PC、GIMP
落書きをスマホのカメラで撮影し、PC に転送します。スマホの種類や転送方法はお好みのもので問題ないと思いますが、筆者は Androidスマホとマイクロソフト製の「スマートフォン連携」というアプリを普段から使っているので、これを使ってPCに転送しました。
転送が終わったら、GIMP で読み込み、背景を白、線を黒に二値化します。
単純な線画なので、それほど神経質になる必要はありませんが、全体のイメージがわかりやすくなるように明るさとコントラストを調整してください。
ここで色が残っていると、後の工程で img2img をかけた際、思わぬところにぼんやりシミのようなものが出てしまいます。

プロンプトの作成
準備するもの:
PC、Stable Diffusion(AUTOMATIC1111版webui)
前回も使った、AUTOMATIC1111版webui の、拡張機能「stable-diffusion-webui-wd14-tagger」を使ってプロンプトを生成します。インストールしていない場合は「Extensions」タブからインストールします。
「Tagger」タブの左側の窓に前工程で取り込んだ落書きをドラッグ&ドロップすると右上の「Tags」と書かれた窓にプロンプトが表示されます。
このときの落書き画像は、二値化する前でも後でもどちらを使っても大きな問題はないと思いますが、筆者はたまたま二値化前のデータを使いました。
フローとして考えると二値化後の画像を使った方がスマートだったかもしれません。
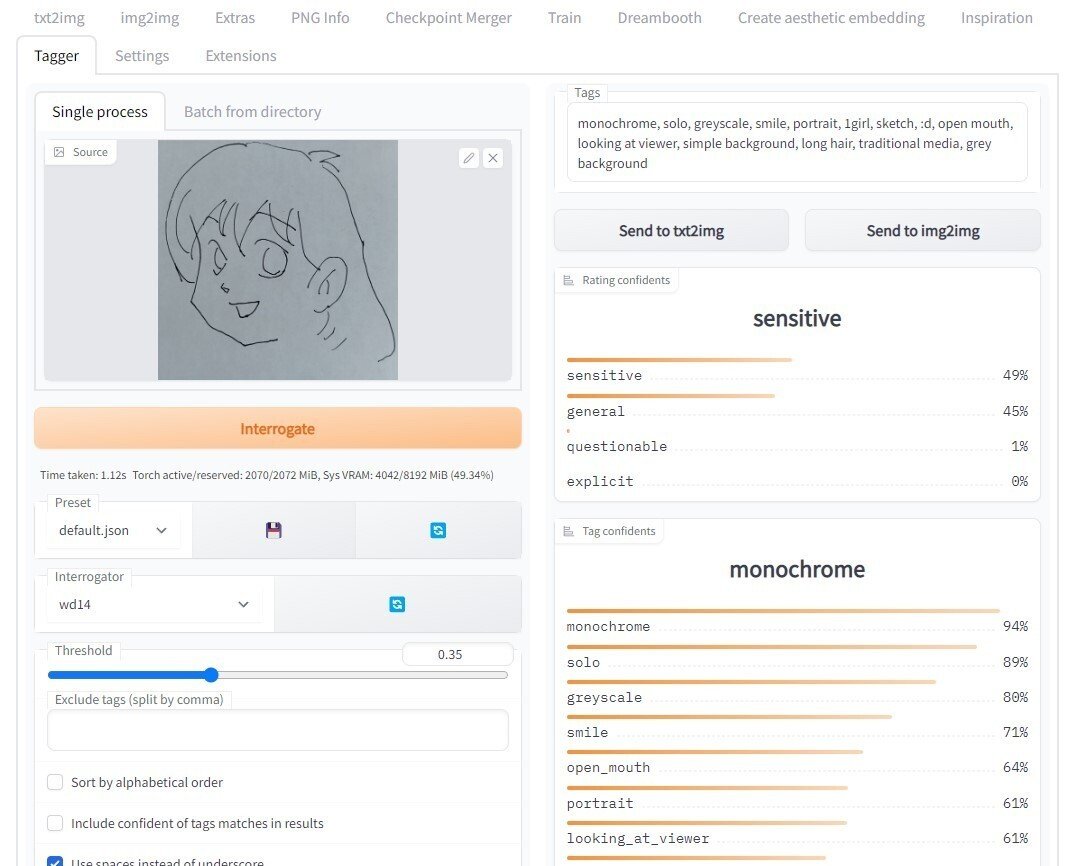
今回の落書きでは下記のようなプロンプトが生成されました。
monochrome, solo, greyscale, smile, portrait, 1girl, sketch, :d, open mouth, looking at viewer, simple background, long hair, traditional media, grey background
尚、今回は次工程の img2img で、画像生成モデル(checkpoint)として Anything-V3.0 を使うので、Tagger を使いました。
Waifu Diffusion や、Anything-V3.0 は、danbooru.donmai.us の画像とタグで学習しているようで、同じ danbooru.donmai.us から取ってきたタグからプロンプトを生成する Tagger とは相性がいいのでこれを使いました。もし、他のモデルを使うのであれば Tagger よりも img2img の画面にある Interrogate CLIP を使った方がいいかもしれません。
img2img(線画のクリーンアップ)
準備するもの:
PC、Stable Diffusion(AUTOMATIC1111版webui)
プロンプトを編集します。
最終的にカラーにしたいので、monochrome と、greyscale、simple background、grey background を削除します。
また、キャラクターのイメージを固定したかったので、今回は先頭に (toriyama akira) と追加しました。
自分で絵を描けるならば、何枚か自分の絵を用意して Dreambooth や Textual Inversion などの機能を用いて追加学習させれば、自分のスタイルを指定することができると思います。
残念ながら筆者の画力では適切な画像データを準備することができないので、今回は (toriyama akira)を使いました。
最終的なプロンプトは下記のとおりです。
(toriyama akira) solo, smile, portrait, 1girl, sketch, :d, open mouth, looking at viewer, long hair, traditional media
先もふれましたが、画像生成モデルとして、Anything-V3.0(Model hash: 6569e224)を使います。
Anything-V3.0 を使う理由は、先述のスタイル指定と同じ理由です。手元に自分で描いた絵が何枚かあれば、Anything-V3.0 でなくても追加学習させたモデルを使用することができると思います。
今回使用した設定は下記の通りです。
Steps: 20, Sampler: Euler a, Size: 512x512, CFG scale: 7
Denoising strength: 0.5
ちなみに、気に入った絵が出るまで何度か生成し直しましたが、この画像が出てきたときの Seed値は 3722298337 でした。
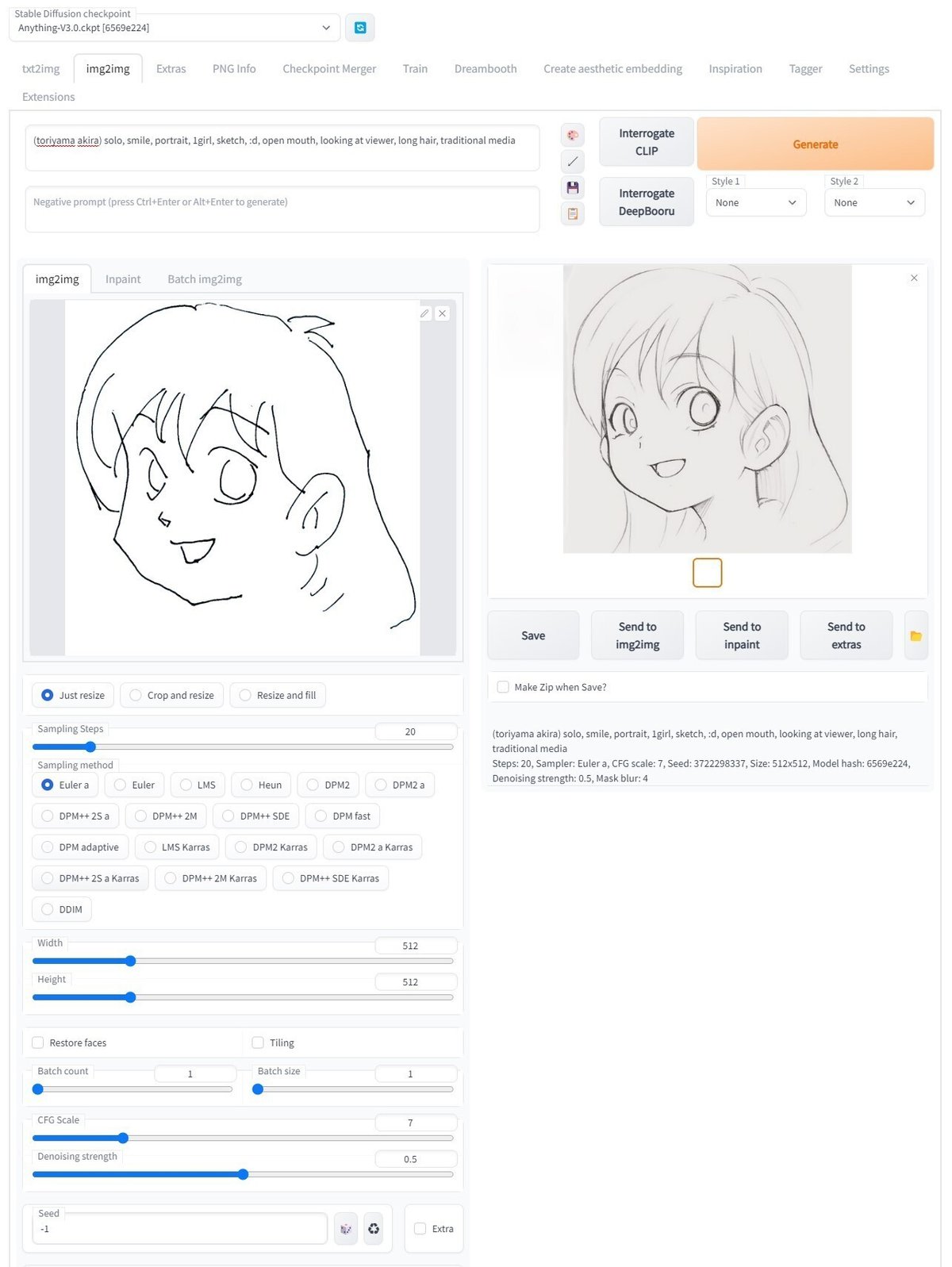

着色
準備するもの:
PC、GIMP
img2img で気に入った画像が生成で来たら GIMP で着色します。
適当に塗って大丈夫ですが、線画のレイヤーが一番上に来るようにします。バックの白を透明にする方法は下記のページを参考にしました。
ざっと着色すると、こんな感じになります。

img2img(最終クリーンアップ)
準備するもの:
PC、Stable Diffusion(AUTOMATIC1111版webui)
再度 img2img を使って仕上げをします。
ただし、線画をクリーンアップしたときの設定を全て引き継ぎたいので、まず PNG Info で線画の画像のパラメータを確認します。
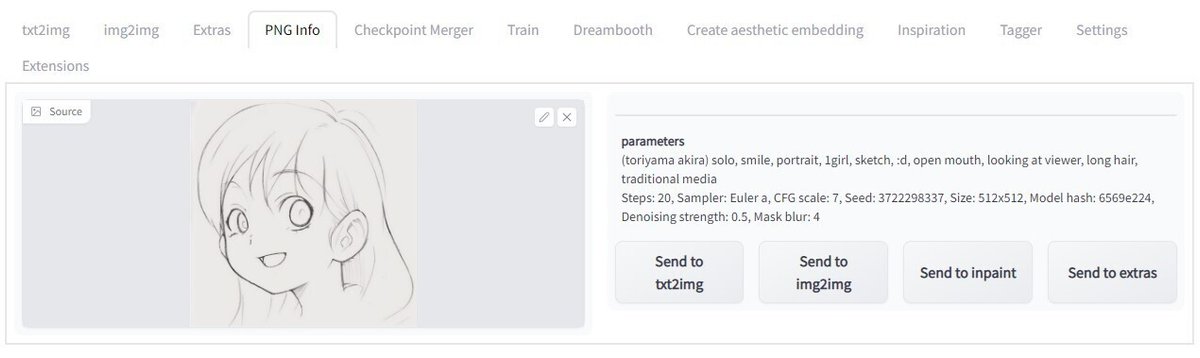
プロンプトを含め、パラメータが表示された状態で「Send to img2img」ボタンをクリックして、パラメータを img2img に送ります。Seed が線画を生成したときと同じ 3722298337 になっていることを確認してください。
続いて、img2img 画面の左側の窓に、先ほど GIMP で着色した画像をドラッグ&ドロップして「Generate」ボタンをクリックします。
すると、それっぽいイラスト風に着色された画像が生成されます。
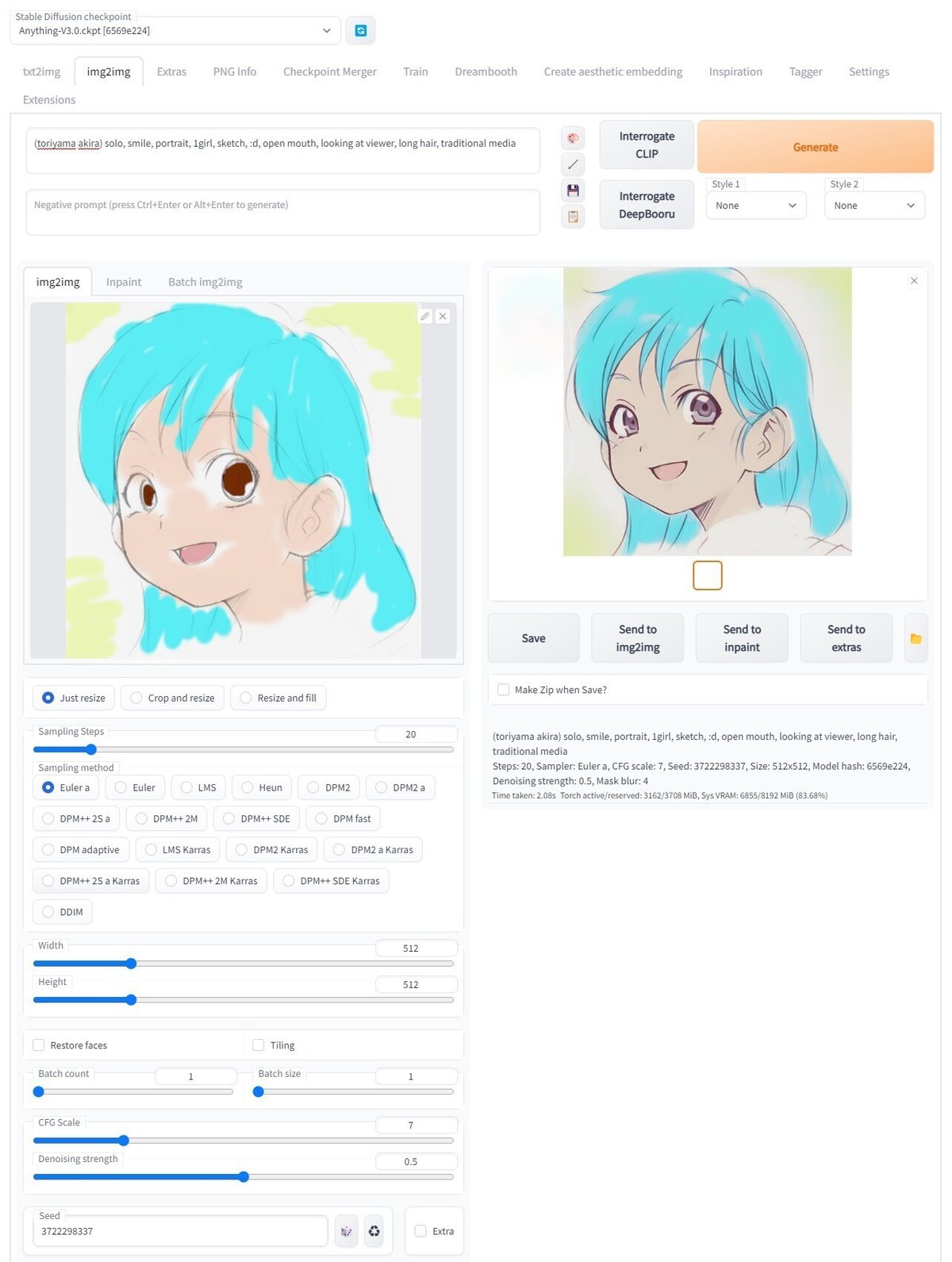

高解像度化
準備するもの:
PC、Stable Diffusion(AUTOMATIC1111版webui)
先の画面のまま「Send to extras」をクリックして Extras の画面に移ります。
一旦 webui を閉じてしまったようなら Extras の画面の左の窓にクリーンアップ後のカラー画像をドラッグ&ドロップしても同じです。
今回は縦横 512 ピクセルの正方形で生成したので、例えば、4倍の 2048 ピクセルに拡大します。
アップスケーラーには、アニメ調を意識して「R-ESRGEN 4x+ Anime6B」を使います。
アップスケーラーについては、下記のリンクなどを参照してください。
「Generate」をクリックして高解像度化します。
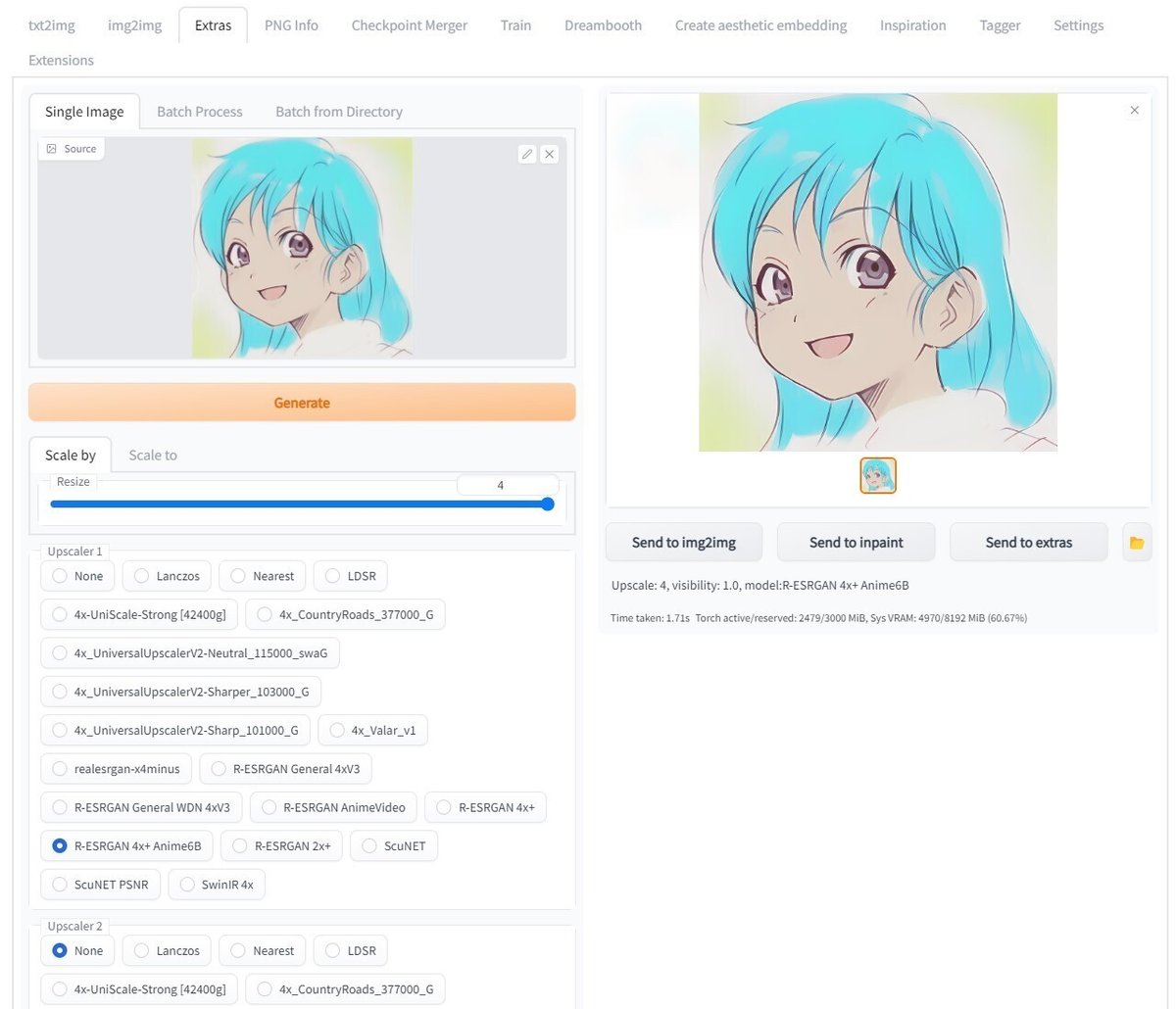

完成です!

まとめ
今回は、下記の工程で落書きをカラーイラスト化してみました。
落書き
PCに取り込み
img2img で線画をクリーンアップ
ラフに着色
img2img でカラー画像をクリーンアップ
高解像度化
ラフな作業の繰り返しで、絵心のない筆者でもそれなりのイラストを作成することができました。
おわりに
落書きのような手書きのラフ画から、あたかもペン入れや着色クリーンアップのような工程を Stable Diffusion の img2img を使用して行うことができました。
このフローでは、簡単にPOCを流してみたかったので Anything-V3.0 を使いました。従って、今回の工程をなぞるだけでは danbooru.donmai.us のデータに強く依存することになります。
この点をあまりよく思われない方もおられるかと思います。
これについては、既に作業内容の記述中にふれていますが、今後、追加学習をうまく使うことで回避可能だと思われます。
【雑談】絵師様は画像生成AIがお嫌い?
2022年12月2日、株式会社セルシスは、同社が開発販売する CLIP STUDIO PAINT に対して画像生成AI機能を搭載しないことを発表しました。
画像生成AI機能を試験的に実装した結果として、ユーザーからのお怒りの声に謝罪し、画像生成AIをご不安・ご不快な思いをさせるものとして、全否定する形で当該機能を搭載しないことが宣言されています。
CLIP STUDIO PAINT のユーザーの多くは、画像生成AI を使わなくても絵が描ける人たちです。彼らにとって絵が描けることは、練習を積んでも絵が描けない人たちと自分たちを分ける境界線だったはずです。そこに、いま、絵を描くことが苦手な人でも、それっぽい絵を作り込める画像生成AIという道具が現れたのです。つまり、誰でもがその境界線を軽々と飛び越えてくるようになったのです。「上手に絵が描けること」によってアイデンティティを維持していた人々にとって、言葉にできない不安がどんどん溜まりはじめている状態であったはずです。
そこにもってきて、これまで自分たちの境界線を形作るために使い込んできた CLIP STUDIO PAINT が画像生成AI を安易に丸ごと取り込んで、境界線自体を壊しに来たわけですから、動揺ぶりは大変なものであったでしょう。
一時期、話題になったので覚えている人も多いと思いますが、絵画コンテストで AI が生成した画像が優勝したとき、他のアーティストから不満が出たという話と似ているように感じます。
更に、話を厄介にしているのは、Anything-V3.0 のように、画像生成AI のモデルの中に、マンガやアニメ調のイラストを描いている方々の一部に大変評判の悪い danbooru.donmai.us にアップロードされた画像に特化して学習したものがあるということ。しかも、それらのモデルを使うと比較的単純なプロンプトでも、かなりそれっぽい画像を生成することができてしまいます。
これらの問題はについては、上述の作業工程の説明中でも少しふれましたが、Dreambooth や、Textual Inversion といった、追加学習の機能を使えば解決できるはずです。
追加学習の機能をうまく使えば、自分の画風や自分で作ったキャラクターなどを学習させることができ、img2img のモデルとして使えば、自分の絵を素早く綺麗に仕上げるための道具として画像生成AI を活用することができます。
こうなると、長年絵を描き貯めていて、独自の画風ができていたり、独自のキャラクターを持っている人が、学習に適したデータをたくさん持っているはずですし、場合によっては、AI の学習に都合がいい絵を大きさやパースなどを考慮しながら何枚も描ける人が、上手に追加学習を進めることができ、これまで沢山絵を描く練習をしていたからこそ AI をうまく活用できるようになります。
ただ、筆者が調べている限りでは、さまざまなサイトで、追加学習のための作業手順は公開されているものの、まだこうすればマンガやイラストを描くときのワークフローに組み込めるという具体例は確立されていないようです。
また、追加学習を行うには大きな VRAM を搭載しているグラフィックカードを使って数時間の処理を行う必要があり、個人でいろいろ試してみながらトライ&エラーを繰り返すという作業がやりにくいということもあります。
できればこのあたりは、セルシスのような企業が画像生成AI を頭ごなしに否定するのではなく、本当に絵を描くためのツールになるよう、丁寧に仕上げて欲しいと思うところです。
今回の CLIP STUDIO PAINT への画像生成AI機能の導入は、デモ映像を見る限りでは、単に Stable Diffusion を組み込んだだけで、あまりにも乱暴に見えました。
これまで CLIP STUDIO PAINT を使って絵を描いてきた人たちのワークフローをひっくり返して「ほら、AI だよ。使えよ」と投げつけておいて、「なんか、だいぶ怒ってるみたいね。みんな文句ばっかいうからやめるわ」というのは、開発の姿勢としてはあまりに稚拙。最近流行りの「顧客に訊く」とか「アジャイル開発」とか「拙速は巧遅に勝る」とかいう、一連の言葉の捉え方を完全に間違っているのではないかと感じます。
自分たちが、ユーザーの本当にやりたいことを吟味せず、Stable Diffusion 関連の公開されている機能を安易に組み込んで「画像生成AI機能」としたことが悪いのであって、画像生成AI が悪いわけではないのに「ああ、皆さん、画像生成AI のこと、お嫌いなんですね」という理解になって終わっていることが残念でなりません。
とはいえ、実のところ「自分たちが作りたいもの」や「自分たちが作るべきもの」と「簡単に作れるもの」を混同してしまう例はよくあって、筆者も起業や新規事業に関わるときはいつも「簡単に作れるものを作ってごまかそうとしていないか?」と「夢みたいなことばかりいっても、作れないものは作れない」の板挟みになっています。
セルシスの開発メンバーにしてみれば、ここ数カ月の画像生成AI のインパクトが、早く何かをやらないと後れを取ってしまうという気持ちばかりに拍車をかけてしまい、ついつい、目の前のできることにすがってしまったのでしょう。
今回のセルシスの一件については、絵師様のご機嫌を取るために画像生成AI を全否定するのではなく、絵師様が本当に使いこなせて、絵師様の活動を支援できる AI を本気で開発する方向に舵を切り直して欲しいと思いました。
頂いたサポートは今後の記事作成のために活用させて頂きます。