
【画像生成AI】Stable Diffusion V1 で、Depth-to-Imageを試す (AUTOMATIC1111/stable-diffusion-webui)

はじめに
11月24日に Stable Diffusion 2.0 がリリースされてかなり話題になっていますが、 AUTOMATIC1111/stable-diffusion-webui で使えるようになるまで、まだ少々時間がかかりそうです。あ、既に対応されているようですね。せっかく書いたのでとりあえず公開します。
今回のバージョンアップの目玉である、depth2img (Depth-to-Image) と呼ばれる depth-guided stable diffusion model の実装については、似た機能が Stable Diffusion V1 をベースとした、AUTOMATIC1111/stable-diffusion-webui に拡張機能として提供されているので、どんな感じになるのか体験してみました。
やったこと
Anything V3.0 (Model hash: 6569e224) を使うと、簡単にそれっぽいアニメ調の絵が生成できるので、これを使ってテストしてみます。
ケモ耳メカ少女の生成
まず、ケモ耳メカ少女を生成します。

呪文等、設定は以下の通りです。
ちなみに、この Prompt の部分は、ネットの拾い画を Tagger (stable-diffusion-webui-wd14-tagger) という拡張機能に読み込ませて生成したものです。
Prompt:
high definition, 1girl, breasts, navel, solo, headgear, bangs, weapon, cleavage, standing, gradient, armor, thighhighs, long hair, mecha musume, blue eyes, zoom layer, looking at viewer, hair between eyes, grey hair, animal ears, closed mouth, full body, gradient background, medium breasts, white background, small breasts, mechanical ears
Negative prompt:
(part of the head: 1.2), (mutated hands and fingers: 4.0), (inaccurate limb and hand and finger and arm:1.2), deformed, blurry, bad anatomy, disfigured, mutation, extra limb, ugly, poorly drawn hands, missing limb, blurry, floating limbs, disconnected limbs, malformed hands, out of focus, long neck, long body, text, error, bad hands, missing fingers, bad feet, extra digit ,fewer digits, cropped, wort quality ,low quality, normal quality, jpeg artifacts, signature, watermark, username, low-quality, low-quality light, low-quality mountain, low-quality illustration, low-quality background
Steps: 50, Sampler: Euler a, CFG scale: 4, Seed: 4183570477, Size: 512x512, Model hash: 6569e224
たまたまですが背景が枠のついた空の絵になっています。メカ少女なので、背景は宇宙がいいかなと思いました。
宇宙の生成
それっぽい宇宙の画像を作ります。

こちらの Prompt の部分は、 https://openart.ai/community/doZURfcxt0RfAbv8tVnX から拝借しました。
後々のことを考えて、Prompt 以外の設定は全て、Negative prompt まで含め、ケモ耳メカ少女と同じにしてあります。
背景をこの画像で差し替えたいと思います。
Prompt:
ethereal fantasy galaxies in space, painting by Thomas Kinkade and Greg Rutkowski and Gustave Doré, center frame, hyperdetailed 8k uhd, epic nebula, distant stars and planets
Negative prompt:
(part of the head: 1.2), (mutated hands and fingers: 4.0), (inaccurate limb and hand and finger and arm:1.2), deformed, blurry, bad anatomy, disfigured, mutation, extra limb, ugly, poorly drawn hands, missing limb, blurry, floating limbs, disconnected limbs, malformed hands, out of focus, long neck, long body, text, error, bad hands, missing fingers, bad feet, extra digit ,fewer digits, cropped, wort quality ,low quality, normal quality, jpeg artifacts, signature, watermark, username, low-quality, low-quality light, low-quality mountain, low-quality illustration, low-quality background
Steps: 50, Sampler: Euler a, CFG scale: 4, Seed: 4183570477, Size: 512x512, Model hash: 6569e224
【余談】Negative promptについて
ちなみに、Negative prompt に書き込んでいる呪文は、ネット上に流れている情報を参考に少しずつ調整したもので、Anything V3.0 を使うときはいつも書き込んでいるおまじないです。
効果のほどはというと、同じ設定で Negative prompt を消すと、先ほどのケモ耳メカ少女がこんな感じになります。

ポーズや表情が変わってしまい、単純な比較は難しいのですが、髪の毛の表現や、線や影の使い方などを見ると細かいところで効果は出ているようです。
ただ、人物の絵を生成することを想定して書き込んでいるので、宇宙のイメージなど、人が登場しない画像では必要ないものです。
拡張機能 multi-subject-render のインストール
さて、本題に戻ります。AUTOMATIC1111/stable-diffusion-webui を使っている限り、拡張機能のインストールは極めて簡単です。
UI の一番上、右端に現れる Extensions タブの中の Available タブを選んで、Load from: ボタンをクリックすると現れる拡張機能のリストの中から、(かなり下の方にある)multi-subject-render を選んで、Install ボタンをクリックするだけです。
インストールが終わったら、AUTOMATIC1111/stable-diffusion-webui を再起動します。
text2img タブに移動して、画面下の方の Script のプルダウンメニューから Multi Subject Rendering が選択できればインストール成功です。
合成
multi-subject-render を使えば、全て自動でやってくれますが、合成の流れは以下のようになります。
背景になるそれっぽい宇宙の画像を生成する
ケモ耳メカ少女の画像を生成し、これを元に深度マップを生成する
深度マップを抜き型にして、背景になるそれっぽい宇宙の画像を切り抜き、抜けたところに img2img で再度ケモ耳メカ少女を生成する
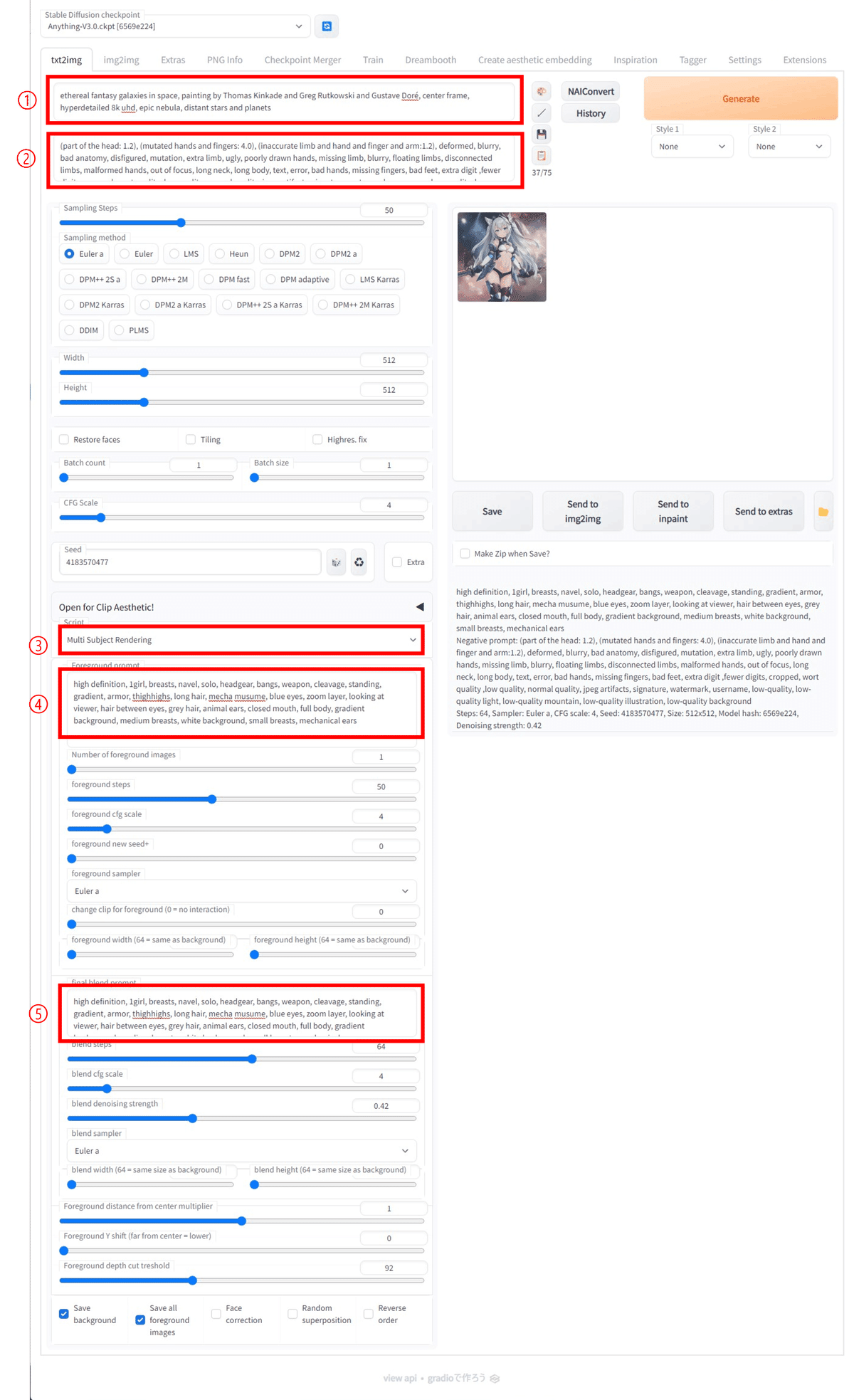
それでは、text2img の画面で、各種設定をしていきます。
まず、普段 text2img で Prompt を入力しているところには、背景になるそれっぽい宇宙の画像の Prompt を入力します。
➀ Prompt:
ethereal fantasy galaxies in space, painting by Thomas Kinkade and Greg Rutkowski and Gustave Doré, center frame, hyperdetailed 8k uhd, epic nebula, distant stars and planets
次に、Negative prompt を入力しますが、これは上記3つの画像生成の工程すべてで共通して使われます。
➁ Negative prompt:
(part of the head: 1.2), (mutated hands and fingers: 4.0), (inaccurate limb and hand and finger and arm:1.2), deformed, blurry, bad anatomy, disfigured, mutation, extra limb, ugly, poorly drawn hands, missing limb, blurry, floating limbs, disconnected limbs, malformed hands, out of focus, long neck, long body, text, error, bad hands, missing fingers, bad feet, extra digit ,fewer digits, cropped, wort quality ,low quality, normal quality, jpeg artifacts, signature, watermark, username, low-quality, low-quality light, low-quality mountain, low-quality illustration, low-quality background
その他のパラメータも、それっぽい宇宙の画像を生成したときと同じ値に設定します。
Steps: 50, Sampler: Euler a, CFG scale: 4, Seed: 4183570477, Width: 512, Height: 512, Model hash: 6569e224
➂Script:
Multi Subject Rendering
Script のプルダウンメニューから Multi Subject Rendering を選ぶと、更にパラメータを入力できるようになります。
ここで、Foreground prompt の欄には、ケモ耳メカ少女の生成に使ったプロンプトを入力します。
➃ Foreground prompt:
high definition, 1girl, breasts, navel, solo, headgear, bangs, weapon, cleavage, standing, gradient, armor, thighhighs, long hair, mecha musume, blue eyes, zoom layer, looking at viewer, hair between eyes, grey hair, animal ears, closed mouth, full body, gradient background, medium breasts, white background, small breasts, mechanical ears
今回、ケモ耳メカ少女は一人だけなので、Number of foreground images は 1 。
ケモ耳メカ少女のイメージが変わらないように、foreground steps と foreground cfg scale は、はじめにケモ耳メカ少女の生成に使ったものと同じ値、foreground steps: 50、foreground cfg scale: 4 に設定します。
更に、Seed も同じ値を使いたいので、foreground new seed+ を 0 、その他のパラメータも、foreground sampler: Euler a、 change clip for foreground: 0、foreground width: 64、foreground height: 64 と、とにかく、ケモ耳メカ少女の生成に使ったものと同じ条件になるようにしました。
ここまで Foreground prompt 以下に入力したパラメータを元にケモ耳メカ少女の画像が生成され、この画像を元に深度マップが作られます。
次に、深度マップで切り抜かれた背景の中にimg2imgで再度ケモ耳メカ少女を生成するための設定です。
同じケモ耳メカ少女の画像を生成したいので final blend prompt には、上記の ➃ Foreground prompt と同じ呪文を書き込みます。
⑤ final blend prompt:
high definition, 1girl, breasts, navel, solo, headgear, bangs, weapon, cleavage, standing, gradient, armor, thighhighs, long hair, mecha musume, blue eyes, zoom layer, looking at viewer, hair between eyes, grey hair, animal ears, closed mouth, full body, gradient background, medium breasts, white background, small breasts, mechanical ears
blend steps は初期設定のまま 64、blend cfg scale は、元のケモ耳メカ少女に合わせて 4、blend denoising strength は初期設定のまま 0.42、blend sampler は元のケモ耳メカ少女と同じ Euler a、サイズに関しても元のサイズと同じ値が使われるように foreground width: 64、foreground height: 64、あとの設定は初期設定のまま、Foreground distance from center multiplier: 1、Foreground Y shift: 0、Foreground depth cut treshold: 92 を使いました。(UI 上の treshold は threshold の誤記と思われます)
また、Save background と、Save all foreground images にチェックを入れておけば、途中で生成されるバックグラウンドとフォアグラウンドの画像も保存されます。
この設定で UI 上部の Generate ボタンをクリックすると以下のような画像が生成されます。

どうにかうまく、それっぽい宇宙の背景にケモ耳メカ少女が合成できました。
下記に、実行中の画面のキャプチャ画像を貼っておきます。
赤枠の➀~➄は本文中の番号に対応しています。
おわりに
最終段階で、img2img を使ってケモ耳メカ少女を再生成しているので、⑤ final blend prompt の部分を書き換えればケモ耳メカ少女をヒョウ柄ビキニ少女にも書き換えられるはずだと思い、実はいろいろトライしてみたのですが、部分的にヒョウ柄なメカ少女になるだけで、どうもきれいにヒョウ柄ビキニ少女になりませんでした。
今回は、お手軽にそれっぽい画像を生成するためにモデルとして Anything V3.0 を使ったので、アニメ調の平面的な絵になってしまいましたが、深度マップをうまく使うには、もう少し立体的に見える絵を使った方がいいのかもしれません。
【雑談】Stable Diffusion のバージョンアップと、NSFW対応について
今回、Stable Diffusion が V2 にバージョンアップして、大きく話題になったのが、機能アップの話に加えて、ポルノ画像などを生成できないようにモデル作成時にトレーニングデータからヌードやポルノ画像を削除したという話です。
ポルノ画像が生成できない。いいね! 誰もが画像生成AIを安心して使えるように、真っ当に開発者としての責任を果たしておるじゃないか。
……と、まぁ、世の中の権威ある方々なら言うのかもしれませんが、筆者としては今回の対応については、とても残念だと感じています。
筆者は自分自身のことを決して品行方正な人間だとは思っていませんが、逆にポルノ中毒だとも思っていません。(世の中からどう思われているかはわかりませんが)
なので、Stable Diffusion でポルノ画像を作りたくて作りたくてたまらない、Stable Diffusion でポルノ画像が生成できなくなったら人生が終わってしまう! などと思ったことは一切ありません。
それでも、今回の対応は残念でなりません。
なぜなら、その行為があまりにもハッカーらしくないからです。悲しいほどにハッカーらしくない行為です。
例えば、ポルノ画像が見たければ、インターネットを使って、それなりのサイトに行けばいくらでも見ることができます。わざわざ探し回らなくても、SNS でそれなりのアカウントをフォローしていればタイムラインに常時ポルノ画像を流し続けることも可能です。
親に隠れてこっそり週刊プレイボーイのページをめくった昭和の時代を経験している筆者からすると、既に、インターネットに限らず世の中はポルノであふれています。
更に、重要な問題だとされている、既存のポルノ画像と組み合わせて有名人のフェイクポルノが作られるなどという話は、本来、AI の開発者が気にする話ではありません。これらは、印画紙をハサミで切り貼りしていた時代から行われていた行為です。例えば、三原順子ウラ本騒動は1983年の出来事です。Stable Diffusion でポルノ画像が作れるかどうかなんて全く無関係な話なのです。
そんなことは Stable Diffusion の開発者たちも当然わかっているでしょう。
ではなぜ、わざわざトレーニングデータをフィルタリングしたのか。それはもう単純に、この手の面倒事から逃げようとしたわけです。
事情は理解できます。開発元である Stability AI は、Stable Diffusion が話題になって10月17日に1億100万ドルの資金調達を公表しています。
出資元のベンチャーキャピタルなどは、Stability AI の株価に大きく影響する Stable Diffusion の世間での評判を気にするでしょう。
ただ、残念ながらトレーニングデータをフィルタリングしただけではこの問題から逃げきれていないのです。
The Verge の記事には、Stability AI の創設者である Emad Mostaque 氏が、Discord で、“A good model should be usable by everyone and if you want to add stuff add stuff,”(よいモデルは、誰もが使えるものであるべきで、もし何かを追加したければ、(あなたが)それを追加しなさい) と、発言したと書かれています。(肝心の Discord へのリンクが切れているので確認できませんが)
これは一見「満足するものが無ければ、自分で作ればいい」というオープンソースコミュニティの精神に沿った発言のようにも読み取れます。
ただ、この発言が本当だとすると、問題は大きく2つあります。
まず第一に「無ければ、自分で作ればいい」というのは、作る側の台詞であって、作らない側が口にしてはいけません。しかも、作らない側が1億100万ドルの資金調達を受けているのはおかしな話です。こちらには身を削る思いで自作した20万円のPCが一台あるだけです。「文句があるならお前が作ればいいじゃん」と言われても、「パンがなければケーキを食べればいいじゃない」というレベルの認識違いがあります。
次に、「俺は手を汚さない。お前がやれ」は裏社会の台詞です。誰かが追加学習を行うことにより、Stable Diffusion でフェイクポルノや児童虐待の画像を生成することを暗に認めてしまっています。
これによって Stable Diffusion で作られたフェイクポルノが話題になっても「俺はやってない。知らない誰かが勝手にやっただけ」と言い逃れし続けられると考えているようですが、逆にこれは危険です。
ベンチャーキャピタルはマフィアのボスではありません。
実際に Stable Diffusion でフェイクポルノや児童虐待の画像が作られ続ければ、いつかは「対策したんじゃなかったのか?」という話になるでしょう。
中途半端に逃げようとしたため、逆に面倒な話に首を突っ込んでしまったのです。
例えるなら、うちで製造している包丁は切れ味が良すぎて、殺人事件に使われるといけないので先端から 5cm は刃を付けていないんですよ、というようなものです。
「先端を使いたければ、自分で砥げばいいんです。砥石もお渡しします」
といわれれば、え? どういうこと??? とみんな考え始めます。
よその切れの悪い包丁を使ったかもしれない犯罪者が、一生懸命この包丁を砥ぎ始めます。
切れ味のいい包丁を作ることだけにこだわっていれば巻き込まれなかった問題を自ら引き寄せたわけです。
筆者は、オープンソースに対してこの手の対策は無意味であることをベンチャーキャピタルに説明して、しっかり理解してもらうのが、開発側の正しい姿勢であったと思います。
包丁で殺人事件が起きるのは、使う側の問題であって作る側の問題ではないという姿勢を貫くのです。
どうしても理解されないのであれば、理解のない相手からは資金提供をうけない。それが例え何億ドルであっても。
そういう覚悟がないのなら、はじめからモデルを無償公開するべきではなかったのです。
無償公開したからには、当然、そこは覚悟したのだと思っていました。
筆者が過去に関わった企業の AI関連プロジェクトのいくつかは、思った成果が得られないまま失敗とも言い切れず、進むに進めず止めるに止められずという状況のまま、いまも四苦八苦し続けています。
AI の専門家ではないのであまり詳しく言及できませんが、技術的な側面で見ると、うまくいかない原因のほとんどは良質なトレーニングデータが得られないか、実は得られていてもうまくトレーニングできないことによるものです。つまり AI がうまく動作するかどうかはトレーニングの段階で大方が決まってしまいます。
したがって、どんなに素晴らしい AI のソースコードが公開されても、トレーニング済みのモデルデータが作れないことには使い物になりません。たいていの場合、これは素人にはどうすることもできないのです。
Stable Diffusion ではすでにトレーニングの終わったモデルデーターも無償で配布されました。当初、筆者はこれに大変驚きましたし、同時に興奮しました。
ついに使える AI が、お金の流れと切り離された! 彼らは本気だ! これをきっかけに世の中が変わるかもしれない! そう思ったのです。
ただ、その興奮も半年はもちませんでした。
スポンサーのご意向に沿ったものしか作らないのであれば、オープンソースである価値は極めて低くなります。
世の中の権威ある方々は、基本的にいまの自分の居場所を守るため、変化を妨げる方向に動きます。目新しさを派手にアピールすることは大好きですが、自分の地位が危うくなるような大きな変化は望みません。
社員を集めた集会ではいつも「チャレンジする社員を応援する」「変化を恐れるな」「変革が必要」といっていた某大手メーカーの社長が、少人数の会議室で、血気盛んな若手社員から「僕も会社を変えたいんです!」といわれたとたんに「お前らに変えて欲しないわ!」と周囲の人目もはばからず激怒したという有名な裏話があります。既に地位や権威を手に入れた人は、口で何をいっていても本質的には変化を嫌うのです。
今後、スポンサーを怒らせないためには、ちょっとした「使える」「便利」の開発に終始することになるでしょう。そして、世の中をひっくり返すような隠れたエネルギーの塊を、自分たちも気付かないまま、徹底的にそぎ落とす作業に追われることになるのです。
もちろん、それも全く意味のないことではありませんので、是非がんばって欲しいのですが、いろんな可能性を内包していた Stable Diffusion も世の中を変えることはなく、結局、大量のお金に巻き取られていってしまうのです。このことは、本当に残念でなりません。
参考リンク
multi-subject-render についての詳細は、GitHub の README.md に記載されています。
【雑談】で引用した DIAMOND SIGNAL の記事です。Stability AI が 1億100万ドル調達したことについて書かれています。
同じく【雑談】で引用した The Verge の記事です。Stable Diffusion のバージョンアップと、モデル作成時のトレーニングデータについて書かれています。
頂いたサポートは今後の記事作成のために活用させて頂きます。