
【STATA Techs-002】データの要約

THEME:STATAでのデータ要約
GOAL:STATAで度数、平均値、標準偏差、最小値、最大値、分散、変動係数、歪度、尖度、中央値を返す
◯サンプルデータ◯
◯使用コマンド◯
table varname
:変数の度数(freq.)を返す
※「tab」だけでも可
table varname varname
:2変数のクロス集計を返す
※「tab」だけでも可
summarize varname
:変数の回答者数(obs)、平均値(mean )、標準偏差(Std. Dev.)最小値(min)、最大値(max)を返す
※「sum」だけでも可
mean varname
:変数の回答者数(obs)、平均値(mean )、標準誤差(Std.Err.)を返す
tabstat varname, statistics( var cv skewness kurtosis median )
:変数の分散(variance)、変動係数(coefficient of variation)、歪度(skewness)、尖度(kurtosis)、中央値(median)を返す
◯やり方◯
①度数(「table」)
まず、男女の回答者数を返してみましょう。回答者数をみる場合はtableコマンドを使います。以下のようにコマンドすると男女の回答者数が返されます。
table d_sex
この場合、「0」が男性、「1」が女性をとるダミー変数となっているため、男性の回答者は106人、女性の回答者は94人となります。
次に学歴別の度数(回答者数)を返してみましょう。やり方は先ほどと同様、以下のようにコマンドします。
table eduyear
この場合、「9」は修学年数が9年を意味するため、中卒(「9」)が40人、高卒(「12」)が55人、大卒(「16」)が83人、大学院卒(「18」)が17人が学歴別の回答者数ということになります。また、今回のデータでは無回答は99になっているため、無回答者数が5人いることになります。無回答者がいると、分析に支障が出るため、後で処理(欠損値化、欠陥値化)しましょう。
②クロス集計(「table」)
では次に、性別と学歴のクロス集計を作りましょう。Excelでのクロス集計(複数条件集計)はCOUNTIF関数を使い作成するため些か複雑ですが、STATAでのクロス集計は非常に簡単です。コマンドは以下の通りです。
table d_sex eduyear「table」「d_sex」「eduyear」の間はそれぞれ半角スペースを入れます。

例えば、学歴が「9」かつ性が「0」、つまり中卒かつ男性の回答者数は27人です。一方、学歴が「9」かつ性が「1」、つまり中卒かつ女性の回答者数は13人となっています。STATAでのクロス集計はとても簡単です。
③平均値、標準偏差、最小値、最大値(「summarize」)
要約統計は位置(平均、中央値、最頻値、階級値、最小値、最大値)、データ群の様々な観点でのばらつきの尺度を表す分散(標準偏差、変動係数など)やモーメント(分散、歪度、尖度)に分けられます。
まず、年収の平均値(Mean )、標準偏差(Std. Dev.)、最小値(Min)、最大値(Max)を返してみましょう。コマンドは以下の通りです。
summarize income
Obsが観測数(number of observations)を意味するため、回答者数に該当します。サンプルサイズが200であることを意味します。Std.Dev.は標準偏差(standard deviation)を意味し、272.90となっています。標準偏差は分布の集中度(分散具合)を表す指標で、数値が大きいほど分布は分散していることを示します。また、他の性質として、標準偏差を求めると、母平均が存在する区間の推定ができ、平均±1SD範囲中に約68パーセントの確率で母平均が含まれ、平均±2SD範囲中に約95パーセントの確率で母平均が含まれ、平均±3SD範囲中に約99.7パーセントの確率で母平均が含まれるという性質があります。

MinとMaxはそれぞれ最小値と最大値を意味し、この場合はそれぞれ225と3000です。次に、平均(Σxi/n-1)は539.56です。ある変数の平均値と平均値の標準誤差(standard error)は以下のコマンドでも返すことができます。
mean income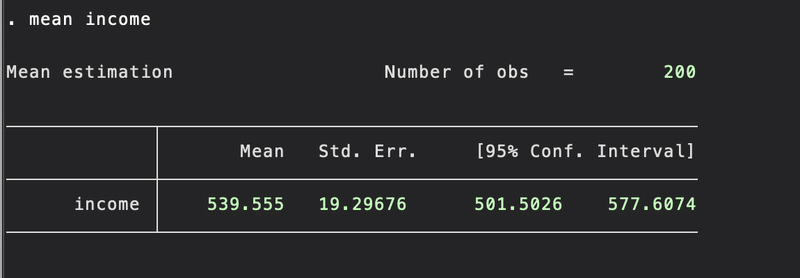
このコマンドを使うと、1変数の平均、標準誤差、95%信頼区間が返されます。標準誤差(Std.Dev./√N)は推定量の精度を測る指標で、標準誤差が小さいことは、推定量の精度が良いことを意味します。この場合は19.30です。データのバラツキが知りたいときは標準偏差を、母集団の性質を知りたいときは標準誤差を使用します。
④分散、変動係数、歪度、尖度、中央値(「tabstat」)
最後に、「tabstat」コマンドを使って、分散(variance)、変動係数(coefficient of variation)、歪度(skewness)、尖度(kurtosis)、中央値(median)を返してみましょう。コマンドは以下の通りです。
tabstat income, statistics( var cv skewness kurtosis median )
TIPS
tabstatでは tabstat varname1 varname2 とすると、2変数の要約が返されますし、tabstat ~, by(varname3) stat(…)とby(varname)を指定すると、指定のvarname毎に区分けされたものが返されます。
まず、分散は分布のひろがりを表す統計量の一つで、標準偏差の2乗に等しいです、定義式は下部です。この場合は74472.99ですが、分散同士比較する分散比較以外は標準偏差を使用して分析するのが一般的です。

次に、変動係数は標準偏差を平均値で割った値のことで、この値に100をかけてパーセントで表すこともあります。身長や体重、テストの点数などスケールの異なるデータのバラツキを絶対値ではなく相対値で比較しようとする場合に標準偏差ではなく、変動係数を使用します。定義式は下部です。この場合の変動係数は0.51です。

次に、歪度は分布が正規分布からどれだけ逸脱しているかを表す統計量で、左右対称性を示す指標です。定義式は下部です。分布の山が左にずれて裾が右に伸びているときは正の値を、山が右にずれて裾が左に伸びているときは負の値をとり、正規分布では0となります。この場合は4.8ですので、山が左にずれて裾が右に伸びている分布であることを意味します。

次に、尖度は分布が正規分布からどれだけ逸脱しているかを表す統計量で、山の尖り度と裾の広がり度を示します。定義式は下部です。3未満のときは尖りが緩やかで裾が短く、3より大きいときは尖りが急で裾長に。正規分布では3となります。この場合は38.8なので裾の広い分布であることを意味します。

最後に中央値です。観測値を大きさの順に並べ、データのちょうど中央にあるデータが返されます。この場合は504が中央値です。
※定義等の引用は「統計WEB」を使用しています。
======
本田恒平(Kohei Honda)
一橋大学大学院経済学研究科博士後期課程(政治経済学、労働政策)
▼質問やご意見等はコメントかホームページのフォームから▼
▼SNS▼
Twitter: https://mobile.twitter.com/4strings725
Facebook: https://www.facebook.com/profile.php?id=100002374515435
この記事が気に入ったらサポートをしてみませんか?