
[Python]pandas DataFrameの複数列の文字列を結合する2つの方法

はじめに
Pythonで、pandasのDataFrameの複数列の文字列を結合する方法を2つご紹介します。
使用するライブラリ
pandas
データ分析、機械学習の実装で最も使用されるライブラリ。
動作環境
・windows10
・Jupyter Notebook 6.2.0
実装
1.複数列の文字列を結合する
使用するサンプルのDataFrameは下記です。
import pandas as pd
address1 = [['神奈川県','横浜市鶴見区','鶴見中央'],['宮城県','仙台市','青葉区本町'],['東京都','大田区','蒲田本町']]
df1 = pd.DataFrame(address1,index=range(3),columns=['Pref','City','Town'])
print(df1)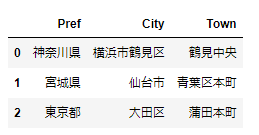
ラベル「Pref」「City」「Town」の列の文字列を結合します。
①str.catメソッドを使う
print(df1['Pref'].str.cat([df1['City'],df1['Town']]))出力結果は下記です。

戻り値は、Series型です。
②+演算子による結合を使う
print(df1['Pref'] + df1['City'] + df1['Town'])出力結果は下記です。

こちらも戻り値は、Series型です。
2.データ内に欠損値がある場合
使用するサンプルのDataFrameは下記です。
address2 = [['神奈川県','横浜市鶴見区','鶴見中央'],['宮城県','仙台市','青葉区本町'],['東京都','大田区']]
df2 = pd.DataFrame(address2,index=range(3),columns=['Pref','City','Town'])
print(df2)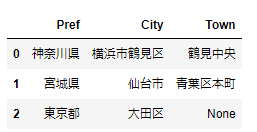
最後の「Town」列が欠損値となっています。それぞれ出力結果を確認してみます。
①str.catメソッドの場合
print(df2['Pref'].str.cat([df2['City'],df2['Town']]))
②+演算子による結合の場合
print(df2['Pref'].str.cat([df2['City'],df2['Town']]))
str.cat、+演算子による結合のどちらの場合でも、欠損値がある行は、NaNとなってしまいます。
いずれかの要素に欠損値があっても、欠損値がない要素は結合されてほしいです。
その場合、それぞれのケースで下記のようにすると結合することができます。
①str.catメソッドの場合
print(df2['Pref'].str.cat([df2['City'],df2['Town']], na_rep=''))na_rep引数で、欠損値のある場合の置き換え文字列を指定することができます。今回は空白に置き換えています。
②+演算子による結合の場合
print(df2['Pref'] + df2['City'] + df2['Town'].fillna(''))fillnaメソッドを使用して、要素が空の場合の処理を指定できます。
注意としては、こちらの場合、列に対して記載する必要があるので、列ごとにfillnaメソッドで指定する必要があります。
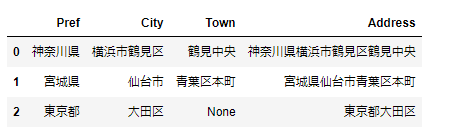
最後に、結合した文字列を新しい列「Address」として設定します。
①str.catメソッドの場合
df2['Address'] = df2['Pref'].str.cat([df2['City'],df2['Town']], na_rep='')
print(df2)②+演算子による結合の場合
df2['Address'] = df2['Pref'] + df2['City'] + df2['Town'].fillna('')
print(df2)①、②どちらのケースでも、下記のように新しい列が作成され、値を設定することができました。
まとめ
今回は、Pythonで、pandasのDataFrameの複数列の文字列を結合する方法と、結合した文字列を新しい列に設定する実装についてご紹介しました。
参考サイト
この記事が気に入ったらサポートをしてみませんか?