
【JKI】003_CDC Cancer Data_02_解答への試み

【解答するためのデータ絞り込み】
Just KNIME It!の第3回目に挑戦中です。
データ内容を理解しようと四苦八苦しているところです。
課題は
(1)女性で発生する最も頻度の高いがんの種類のトップ5は何ですか。(2)男性に発生する最も頻度の高いがんの種類のトップ5は何ですか?(3)癌の発生率が最も高い(つまり、人口の大きさで正規化された癌の症例数が最も多い)米国の州はどれですか?
でしたね。
上記の課題のために解析する対象データは下記の通りとしました。
年齢層: 19種
病名: 81種
州名: 51種
性別: 2種
に分類された
19 x 81 x 51 x 2 = 156,978行
のみを扱うこととし、そのためのデータの絞込はRow Splitterで下記の設定をすれば実施できます。
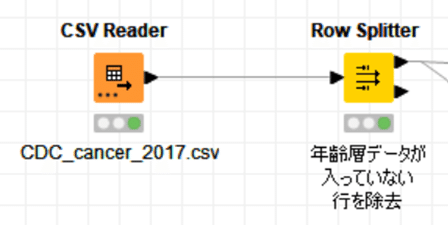

【病名分類を考え直す】
課題の(1),(2)は性別ごとにデータを分けて、Count数のトップ5をリストアップすれば良さそうです。
つまり重要なのは病名別の症例数ですがここで疑問が生じます。81種って分類数は多いのではないか?
CDCのホームページだと17項目を挙げていました。
Bladder Cancer
Breast Cancer
Cervical Cancer
Gynecologic Cancers
Head and Neck Cancers
Kidney Cancer
Liver Cancer
Lung Cancer
Lymphoma
Mesothelioma
Myeloma
Ovarian Cancer
Prostate Cancer
Skin Cancer
Thyroid Cancer
Uterine Cancer
Vaginal and Vulvar Cancers
そこで、病名と性別で群分けして集計してみました。
【Group Byで群別に集計】
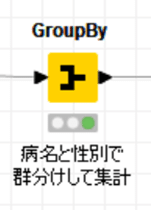
設定:


結果:
病名分類81種と性別2種の掛け合わせで81x2=162群それぞれの症例数が算出されます。

162行ぐらいのデータ数になれば内容を吟味することもできるようになります。
実はどうやらデータの前処理がさらに必要そうです。詳しく見ていきましょう。
【A. 部位の特定ができないケース】
例えばですが、最上部の2行は男女それぞれ
All Invasive Cancer Sites Combined
複数部位での発症例となります。
あるいは、Miscellaneous「その他」という項目もあるのですね。
今回の課題(1),(2)においてはこの項以外でTop5の部位を示すべきと考えました。

【B. データが重複しているケース】
これは詳細に各データを見て気づいたのですが、似たようなID(Cancer Sites Code)で全く同数の症例数の行があります。

あるいは

症例数が一致するってかなりの低確率ですし、病名も極めて似ているので重複データと判断しました。一方は削除してから解析することにします。
【C. 部位が細分化されて分類されたケース】
データの内容をどこまで吟味するか迷うところですが、かなり詳細な分類をしている項目もあります。
例えば
Oral Cavity and Pharynx
Tongue
Salivary Gland
Gum and Other Mouth
Tonsil
は大分類では頭頚部にあたるように思います。
あるいはLeukemiaも細分化されています。

もし名寄せなどする場合は81種のうちどの項目同士は同じ部位と見なすかのTableを作成し、JOINして部位の新カラムでCountの再集計をするでしょう。
TeachOpenCADD紹介でも取り上げましたが、データの内容をより本来の目的に合わせて前処理するには、その分野の知識などが必要ですね。
言い出すときりがないのと私はそもそも医学の知識はほぼないことから、今回はグループ分けを変えないで考えることにしました。
【一部の項目に絞り込み】
上記のようにデータを吟味した結果、
A. 「All Invasive Cancer Sites Combined」と「Miscellaneous」についてはTop5判定では対象としないこととしました。
B, また、重複しているデータも一方を取り除く必要があります。
今回は「Female Breast」と「Female Breast, In Situ」を対象としました。
よって以上の4種に該当する行をRow Splitterで分割します。
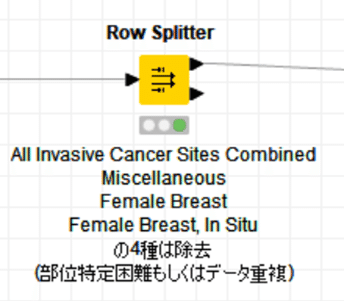
正規表現での複数項目の一括指定が便利です。

結果:

4種8行が分離されたので154行となりました。
【課題の(1)(2)回答】
あとは男女で分けてそれぞれのトップ5を取り出して完了ですね。

(1)

(2)

KNIMEのWFとしては動作におかしなところはないので(1)(2)の回答完了です。
でも、データの内容には気になるところが残ってしまいました。Respiratory SystemとLung and Bronchusって部位が重複しているのではないかと。この2項目を合算したら順位が変わりますよね。上記C)では断念した部位分類の見直しがあっても良かったかなと思いつつ、時間切れでここまでとします。
【課題の(3)回答】
「癌の発生率が最も高い(つまり、人口の大きさで正規化された癌の症例数が最も多い)米国の州はどれですか?」
との設問なので、発生率を算出します。
前回で検討した通り、州名をキーIDとして2つのデータファイルを結合します。
また、州名データにピリオド(.)がついてしまっているデータは事前に変換しておきます。さらに、これはおそらく独自の判断となりますが上記で重複と判定した2つの病名のデータは除いて集計すべきかなと考えました。
WFとしては下記の通り。

各ノードの設定画面を以下に示します。




続いて州別に症例数を集計して、人口で割れば発生率が算出されますから、最多の州を選ぶこともできると考えます。

設定は以下の通り




結果:

以上で課題の3問への解答となります。
【WF提出】


恒例の提出の時間です。
学生の頃、テストを時間切れで提出したときの気持ちを想い出しています。
他の方がどのように考えたのかを知りたいですね。
アメリカの地図上に州別に比率を表示するのもやってみたかったなぁ。
このあとちょっと試してみます。
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。