
【JKI】039_Legislative_Limits_on_Teaching

【JKI_039】課題を確認
Just KNIME It! (JKI)
今回の挑戦はこちら

問題文のところだけをDeepL翻訳し少し加筆して以下に
課題39: 教育の法的制限
レベル: 簡単
説明:
この課題では、教育ジャーナリストとして、「educational gag orders (教育箝口令)」を調査します。これは、"幼稚園から高校までの教育において、人種、性別、アメリカの歴史、LGBTQ+のアイデンティティなどのテーマについて教えることを制限する、州の立法措置 "と定義されています。
我々は、Google認証ノードを使用することをお勧めしますので、ここにあるオリジナルのデータセットのコピーを作成してください。
このデータは、Google Authenticationノードに使用するメールアカウントで、自分のGoogle Sheets内にコピーする必要があります。
Google Sheets Readerノードで、"All Legislation Introduced Since Jan 2021 "というシートを選択し、どの州で箝口令が最も多いか、どのトピックが全体として最も議論されているかを調査するワークフローを作成してください。
【データの入手と背景】
【Google Sheets】
サンプルデータ:
をGoogle Sheetsで開いてみます。

自分のアカウントにコピーしてからKNIME Workflow (WF) での読込をします。
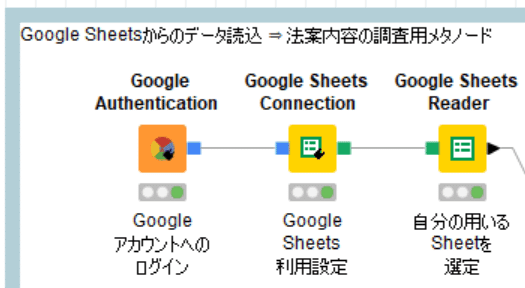
使い方の基本は全てまっきーさんが教えてくれます。いつも本当にありがとうございます。
設定はそれぞれのアカウントにより異なる部分もあるでしょうが例示はしておきます。


以下はおまけですが、読み込んだデータをWF内のdataフォルダにTable形式で格納し、以降はこのTableのデータを使う設定にしました。ほぼいないのではと思うのですがGoogleアカウントを持っていない人も今回の課題を楽しみたいかもなとこの作りにしました。今回も少々自由に課題に取り組ませていただいています。

【educational gag ordersとは何か】
さて、データの中身を見る前に、このデータの由来を少々調べてみました。
そもそも「educational gag orders (教育箝口令)」という言葉、日本ではあまり取り上げられているように思えません。実は今回の解答、ここの調査に一番時間を掛けました。
この調査を主導するPEN Americaの活動理念に基づく調査であることが分かります。
日本でのWeb記事を探してみると、いくつか関連が深そうな報道が過去にありました。
当時の報道に気付くことすらできていなかったですし、コメントできるほどには見識がないので個人的な意見表明は避けます。下記の記事は大変興味深く読みました。
真っ先に思い出したのはこちら。
ではいよいよ課題に取り掛かります。
いまアメリカではどのようなテーマについて教えることを制限する議論と立法が成されているのか、与えられたファイルを元にデータ処理します。
【Descriptionを調査する】
【キーワードを探せ】

上図が読み込まれたデータです。193の法案が掲載されています。
内容に関してはあくまで概要のみが記されているようです。
Description* *This is a summary of notable provisions. For detailed analysis of bills, see our report and monthly round-ups.
解答にあたっては、この概要を対象に各トピック別に関連が高い単語(キーワード)を検索して、その法案がどういった内容を扱うものかのフラグを立てるという方針を定めました。
そのためにどの単語で検索と分類をするかを定める必要があります。そもそもどういった単語がよく使われているか、全く課題にはないのですがタグクラウドで可視化をしてみました。

おまけ機能なので設定は割愛します。興味があればWFを見ていただくとして、結果は例示しておきます。
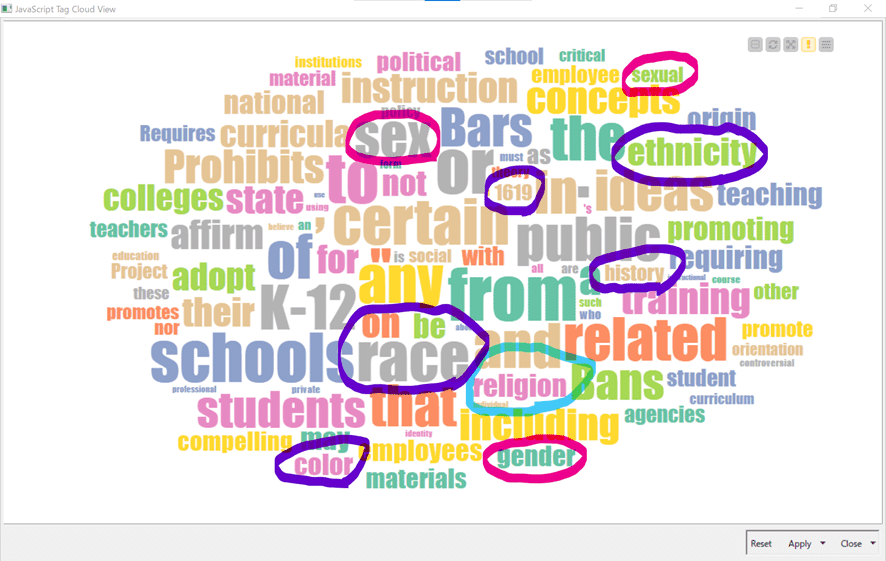
上図では一般的な単語以外に目立った語をいくつかマークしてあります。
人種問題、ジェンダー、宗教などに関して書かれている法案が多いのではないかと考え、下記のように単語の検索クエリーを設定することにしました。

正規表現を利用しつつ単語を列挙しているので見にくくてすみません。
例えば人種に関しては
“race”, ”color”, ”ethnicity” , ”1619” , ”critical” , ”CRT” , ”history” , ”racist”
のどれか1つの文字列を説明文の一部に含んだらすべてヒットと見なすと仮定しています。
ちなみに正規表現でのクエリにおいては「.+」はワイルドカード的に使い、「|」はOR検索するために使います。
1619やCRTに関しては下記のサイトを紹介しておきます。恥ずかしながら全く知りませんでした…。
<参考情報>
1619プロジェクト:
批判的人種理論(critical race theory, CRT):
https://dl.ndl.go.jp/view/download/digidepo_12289529_po_085701.pdf?contentNo=1
【Rule Engine】
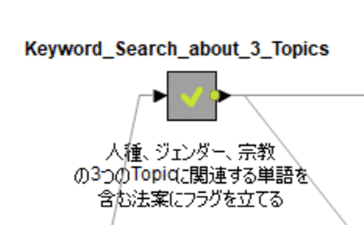
KNIMEでのフラグ付けですが、WFは以下の通り。

人種差別に関係する単語の有無は一番左のRule Engineノードで調べました。
設定:

結果:

例えばRow0は"race"が含まれるので、フラグに"1"が入力されています。
ヒットした法案を「1」、それ以外は「0」としています。
他2つのトピックも同様に扱いました。
結果、下記のメタノードで3つのフラグを追加しました。

【集計と解答】
GroupByなど使って集計をすれば、解答に必要な数値などが得られます。
【Q1: どの州で箝口令が最も多いか】

結果:

【Q2: どのトピックが全体として最も議論されているか】

結果:

解答として、ミズーリ州が法案数25で最多、
法案の内容として人種差別に関するものが146と最多でした。
数値化はわかりやすさの点では便利ですが、気を付けて内容を見ないと大切な問題点を見失うようにも思います。
例えばミズーリ州は25の法案すべてがDiedかPendingである一方で、フロリダ州は3つ法案が出たが、既に人種とジェンダーそれぞれについての2法が承認済です。
あるいは、
Prohibits “specific defined concepts” from being included in public school curriculum.
との法案が通ったアイオワ州は具体的には何を教えると罰せられるのでしょうか?
また、法で明示的に規制されているとわかるのと、全く法整備はされていないが自主規制もしくはそれを強制する圧力により表現の自由が侵害されていることのどちらが深刻なのでしょうか?
あらためて図書館戦争アニメ版でのテレビ放送のエピソードなど想い出しつつ、あまりに脱線が過ぎるのでここまでに。
KNIME Hubに解答は上げています。
おまけ:
【JKI_038 感想戦】
先週のJust KNIME It! (JKI) 第38回は文章から、特定の単語を前後の単語ごと抽出する仕組みを作ると言う課題でした。
公式解答は正規表現の勉強をしないと理解できない設計でした。
概要説明からGoogle翻訳して一部加筆して紹介します。
コンポーネントの構成ダイアログでは、ターゲット ワードとウィンドウ サイズを定義できます。

次に、2 つの入力変数を考慮して正規表現を作成し、この正規表現を使用して一致するすべての用語を見つけました。

join("(?i)(?:\S+\s+){0,",$${Swindow_size}$$,"}\b",$${Starget_word}$$,"\b\w*(?:\W+\b\w*){0,",$${Swindow_size}$$,"}")作成された正規表現は、
(?i)(?:\S+\s+){0,3}\beggs\b\w*(?:\W+\b\w*){0,3}

私のような素人では知らない表現がてんこ盛りでした…
下記サイトも眺めつつ、解説できるか考えましたが余りに付け焼刃なので断念します。
検索はjava Snippetで実行でした。

理解は追い付かなかったのですが、私が四苦八苦した文字列前処理などは不要ですね。
いつか私も正規表現を使いこなしたいものだなと思いました。
いいなと思ったら応援しよう!
