
【JKI】023_Modeling_Churn_Predictions_Part_1

【JKI_023】課題を確認
Just KNIME It! (JKI)
今回の挑戦はこちら

イラストは人工知能のイメージなのでしょうか。
とうとう機械学習を扱い始めましたね。一つの異世界への転換点だと思っています。
問題文をGoogle翻訳し少し加筆して以下に。
課題23:チャーン予測のモデリング-パート1
レベル:簡単
説明:
通信会社は、アカウントの属性に基づいて、どの顧客が解約するか(つまり、契約をキャンセルするか)を予測することを望んでいます。
この目的のために、決定木分類器を使用することが期待されます。
同社は2つのデータセット(トレーニングとテスト)を提供しており、両方とも多くの属性と予測されるクラス「チャーン」を備えています(値0はチャーンしない顧客に対応し、1はチャーンする顧客に対応します)。
決定木分類器をトレーニングデータでトレーニングし、テストデータでその品質を評価する必要があります(たとえば、精度、適合率、再現率、混同行列を計算します)。
注1:この課題は、分類に焦点を当てた、予測問題の簡単な紹介です。決定木分類器を適用するだけで済みます(約92%の精度が得られます)。単純なソリューションは、5つのノードで構成する必要があります。
注2:このチャレンジでは、データセット内の属性またはクラスの統計的分布を変更せず、使用可能なすべての属性を使用します。
注3:問題を理解するためにさらに助けが必要ですか?このブログ投稿をチェックしてください。
【KNIMEと機械学習】
KNIMEは初心者が機械学習を体験し、学習するのにおすすめしやすいツールです。例えばこちらの本、まっきーさんもお勧めしていましたね。
私もTeachOpenCADD - KNIMEで勉強させてもらえてとてもありがたかったです。
今回の注3で紹介されている記事も本当によい教材だと思います。ただし、「問題を理解するためにさらに助け」になると言うよりは、今回の出題内容からより発展的に学びたい方用の情報だとは思いました。正直課題そのものより難易度がかなり高いです。
機械学習という今も研究の盛んな領域をとうとうJKIでも取り上げましたね、しかもPart 1ということで今後さらに出題内容が難しくなりそうな予感ですが
一向にかまわんッッ
さて寄り道はたいがいにしてKNIME workflow (WF)の説明に進めましょう。
【2つのデータセット(トレーニングとテスト)】

データセット入手先:
CSV Readerで読みこむ設定をするにあたって一点のみご注意を。
予測されるクラス「チャーン(Churn)」は文字列データとして読み込む必要があります。今回の二値分類で、「チャーン」は0か1の値を持ちますが、nominalすなわち区別するためだけに用いられている名目上の数値なので、等しいか等しくないかのみ意味があり、幾ら大きいか、何倍大きいかなどの意味はないのです。文字列データとして読み取ることで、名目上の値 (nominal value)として次のDecision Tree Learnerの予測対象カラムとして選ぶことができるようになります。
以下は設定時の画面です。

設定:2つのCSV Reader共通の設定なので片方のみ例示


結果:
トレーニングデータ2666件

テストデータ667件

カラム数:21
【Churnデータの分布】

トレーニング:

テスト:

0か1かの分布に偏りはあるが、トレーニングとテストでデータ分布に偏りの違いはあまりないように分割してくれているようです。説明変数など(他のカラム)まで詳しく見るときりがないので次へ。
【Decision Tree Learner】
アカウントの属性に基づいて、どの顧客が解約するか(つまり、契約をキャンセルするか)を予測することを望んでいます。
この目的のために、決定木分類器を使用することが期待されます。
とのことなので下記のように決定木分類器を使用しています。

設定:

結果としてはモデルが作成されます。下図のようなsimple版の決定木閲覧ができるのを初めて知ったので紹介しておきます。性能はテストデータで評価しますのでここでは割愛します。


一番下の決定木だとDay Chargeすなわち日中の電話料金が高めの人は解約して他に行ってしまうのかなと推測されますね。顧客を逃さないよう昼間の通話料の割引でも考えるか?など、予測モデルから課題解決のヒントが得られやすいのは決定木の特長であろうかと思います。
さて、KNIMEでの決定木での機械学習についての解説記事として、t-kahiさんのブログが素晴らしいので参考にさせていただきました。
基本的に同様の設定で使ったのですが、今回のWF作成時にDecision Tree Learnerを使う際はQuality measureをデフォルトの"Gini Index"ではなく、"Gain Ratio"にしています。また、t-kahiさんの記事ではMin number records per nodeは5としていましたが、今回こちらはデフォルトの2で実行してあります。
理由を理論的に説明できるわけではないのですみません、この次のテストデータの分類時にすべての分類が実行され、かつ今回の課題の条件下で約92%の精度を得るためには上記の設定が良かったと言う試行錯誤の結果でしかないです。すなわちQuality measureをデフォルトの"Gini Index"で決定木を作った時、もしくはMin number records per nodeを5として決定木を作った時はテストデータのうち数十件が判別不能になったし、精度も数%落ちたので上記の条件にしました。
この二つの設定について少~しだけ勉強してみました。
【決定木分類器の条件設定2種】
Decision Tree Learnerノードの日本語化されたディスクリプションより
Quality measure
分割数を算出する際の品質指標を選択します。
下記の記事も読んでみましたが明白な使い分けの指針は私にはわかりませんでした。デフォルトはジニ係数となっています。
Min number records per node
各ノードに最低限必要なレコード数を選択する。
レコードの数がこの数より小さいか等しい場合、木はそれ以上成長しません。
これは停止基準(プリ・プルーニング)に相当する。
t-kahiさんの記事にある通り
過学習を防ぐためにデータ数に応じて設定する必要があるようです.
このパラメーターだけでも本当は最適化した方がいいのかもなと思いました。
他にも英語であればこのノードに関わるきわめて多様な情報がWebで無償提供されていて、感謝しきりです。
例えばこの動画、Decision Tree Learnerノード一つだけでもこんなに勉強しないと使いこなせないのかと知ることができる点ではおススメです。機械学習は底が知れないです。
日本語字幕がなかなかに理解の助けになりますのでお試しあれ。

上記の動画で本ノードは目的変数がnominalでなくても扱えるなど初めて知りました。このノード、よく作りこまれているなと感じています。
あと、こちら無料公開いただいていいのですかという充実した内容です。
もう三千字近いので、次に行きます。
【Decision Tree Predictor】

設定:

結果:

今回実は
注2:このチャレンジでは、データセット内の属性またはクラスの統計的分布を変更せず、使用可能なすべての属性を使用します。
というルールなのでデータ内容を見ないでここまで進めてきてました。
Churnを予測するのに電話番号や州名などまで学習していて心配ですが、目的変数Churnと予測結果Prediction(Churn)はなかなかの一致を示しました。
【Scorer】
決定木分類器をトレーニングデータでトレーニングし、テストデータでその品質を評価する必要があります(たとえば、精度、適合率、再現率、混同行列を計算します)。
とのことで、Scoreノードを使います。

設定:

結果:


上記の通り、学習器の設定はいくつか変えてみたりして、結果として精度で約92%は達成できたので回答完了としました。
以上で解答を完了しました。KNIME Hubにも上げています。

おまけ:
【JKI_022 感想戦】
JKI第22回の公式解答はこちら。
なんといっても可視化部分がいろいろ学べる要素があって良い解答例でした。

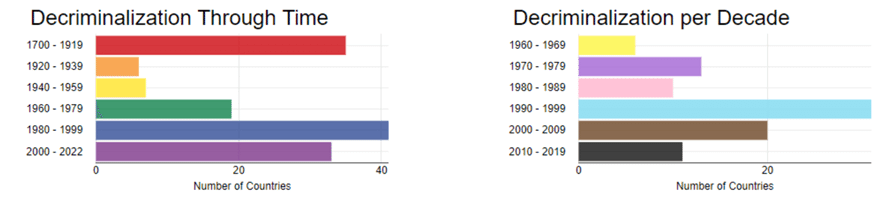
虹色のBarChartなど、色遣いが面白いなぁと感心しました。

年代分類別にPivotingでデータテーブル整形し、Color Managerで虹色の指定をしていました。なるほど、こうすればよかったのか。
世界地図への可視化はJavaScript編集までしての魅せるカラーリングになっていました。Choropleth Mapコンポーネントの中がいじってあって驚きました。難易度Easyって宣言してましたよね。


こういうカスタマイズ例はどこを変えたらいいのかを知るには貴重な実例です。また後日このコンポーネントはじっくり見て、自分の解答も改良してみたいなと思いました。
いいなと思ったら応援しよう!
