
【JKI】024_Modeling_Churn_Predictions_Part_2_02_機械学習自動化

【JKI_024】課題を再確認
Just KNIME It! (JKI)
今回の挑戦はある解約(Churn)予測の機械学習モデル構築において、精度95%以上を目指していて、
テストデータセットでこの精度を得るには、トレーニングデータセットでどのモデルをトレーニングする必要がありますか?この決定は自動化できますか?
との課題設定がされています。
決定木学習器では94%の精度が出ています。
上記のKNIMEworkflow(WF)を転用し、機械学習モデルのスクリーニングまで自動化したいと言うことで、AutoMLを使うと良さそうだと言うところまで、前回に紹介しました。
【AutoML 3分クッキング】
(参考)
材料:
Churn予測WF 1つ
AutoMLサンプルWF 1つ
下準備:
・KNIMEのインストールされたPCを用意しておく。
・上記の2つのWFが動作する環境にしておく。
・Churn予測WFのどこを機械学習自動化するためは変換が必要か考える。
作り方:
① Churn予測WF(上述)をKNIMEで開く。

② 変換する部分 (DecisionTreeLearner, DecisionTreePredictor)を削除する。

③ AutoMLサンプルWFを開く。
(例)
➃ 機械学習自動化に必要な部分をコピーする。
(AutoML, WorkflowExecutor 2つのノードを選択し、Shiftキーを押しながら右クリック)

⑤ Churn予測WFにPasteする。

⓺ ノードを適切に接続する。

⑦ トレーニングデータのCSVReaderを実行する。

⓼ AutoMLコンポーネントのConfigureを開き、内容を確認する。



特に予測対象カラムの選択は必ず確認すること。今回はChurn。
⑨ WFを別名で保存する。
アドバイス:
☑ Deep LearningやH2Oのより豊富な機械学習ライブラリなど活用してみましょう。環境整備はちょっと大変そうです。
☑ AutoMLコンポーネントをOpenして、どのように自動化しているかを学習しましょう。
☑ KNIME Forumの下記スレッドも見てみましょう。数寄者揃いで楽しめます。
【AutoMLを体験しよう】
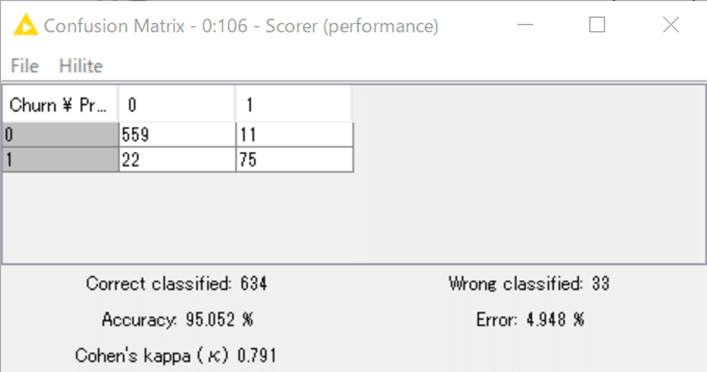
WFを実行してみてください。数分で完了し、結果は以下の通り。
Scorerノードの
View: Confusion Matrix
Flow Variablesタブ
を開くと、自動化の概要が一覧になっています。
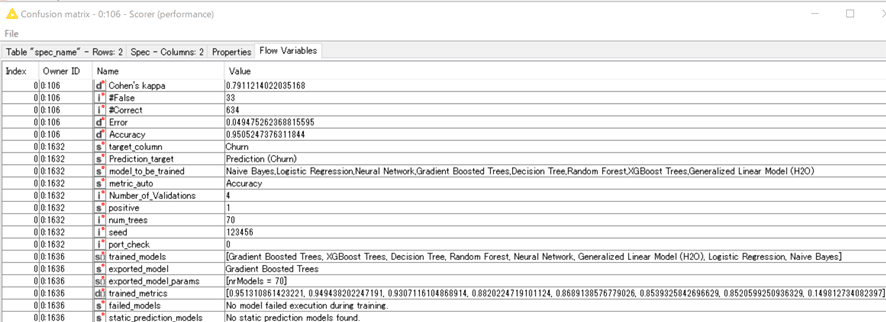
Gradient Boosted Trees, XGBoost Trees, Decision Tree, Random Forest, Neural Network, Generalized Linear Model (H2O), Logistic Regression, Naive Bayes
が検討され、
Gradient Boosted Trees
が選ばれました。
ハイパーパラメータとして
nrModels = 70
が良かったようです。
【AutoMLを見学しよう】
AutoMLコンポーネントも開いていくと、もう敬意なくして見られないほどの設計情報と機械学習モデルのスクリーニングのフローも知ることができます。階層は深く、恐るべき情報量です。

これ、私がnoteで解説したら1年で終わらなさそうです。
無料で公開されていることにあらためて感謝いたします。
さて、AutoMLの初体験、いかがでしたか?私はとにかくありがとうと言いたい。
KNIME Hubに解答は上げています。

おまけ:
【機械学習自動化技術がもたらす世界】
データサイエンスを「民主化」するという言葉、私はDataRobotの方から聞きました。
DataRobot の自動化は、従業員が AI を活用して価値を創造するのを支援します。ベストプラクティスが組み込まれているため、初心者のユーザーでも信頼できるインサイトを獲得できます。また、目的を絞ったトレーニングにより、スキルを構築できます。既存のチームが専門家チームになれるよう DataRobot が支援します。
今回のAutoMLの体験でも感じられるかもしれませんが、機械学習のモデル選択や軽微なチューニングはもう自動化できています。DataRobotやH2Oを使えば、AI担当者が数年前までもしくは今でも何日間も掛けないとできないレベルの最適化まで完全自動化しうると思います。
AI創薬研究に携わる知己が自分の役割、あるいは求められる貢献の質が変わると言っていたのを思い出します。
現場でのAI活用の担い手ももう実際に変わっているのではないでしょうか。
AutoMLノードではまだできないのは、問題の適切な設定、入力する説明変数の適切な選択などかと思います。そこは未来も人間側に求められる領域でしょう。
より問題解決のために必要なドメイン知識を多く持つ現場担当者が、機械学習技術習得に囚われないで得意分野に注力できることが機械学習の自動化の最も大きな効果なのであろうと期待しています。
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。