
【JKI】037_Text_Deduplication

【JKI_037】課題を確認
Just KNIME It! (JKI)
今回の挑戦はこちら

問題文のところだけをGoogle翻訳し少し加筆して以下に
課題37: テキスト重複除去
レベル: 簡単
説明:
Tika Parser を使用して、PDFからスウェーデン語のテキストデータを読み取るように求められます。
次に、テキストの多くが重複していることに気付きます。
これは、PDF自体のエンコーディングの問題である可能性があります。
その結果、テキストを重複排除することにしました。
この課題では、できるだけ少ないノードを使用して、過剰な量の重複テキストを削除するために最善を尽くしてください。
このようなほとんどの場合、テキストを完全に削除することを目指しているのではなく、重複の大部分を排除する費用対効果の高いアプローチを目指しています。
ヒント: このソリューションは5つのノードで構成されていますが、ワークフローによっては5番目のノードが不要な場合があります。
【PDFデータをKNIMEで取り込む】
【サンプルデータを読んでみると】
今回はスウェーデン語データを扱うのですね。サンプルデータを取ってきましょう。
サンプルデータ:

内容はさっぱり見当もつかないです。でも最近は自動翻訳が素晴らしいですね。

なるほど、何となくリンネ大学の「健康と行動科学」分野の教育プログラム説明なんだなと当たりが付きました。
さていつも通りWorkflow(WF)のdataフォルダに入れておいて読み込んでみましょう。
【Tika Parser再び】
第15回のJKIでTika Parserの利用例は紹介済です。
PDFデータをKNIMEで読み込むと言えばTika Parserの出番ですので、上記の記事を参考に今回も実行してみます。
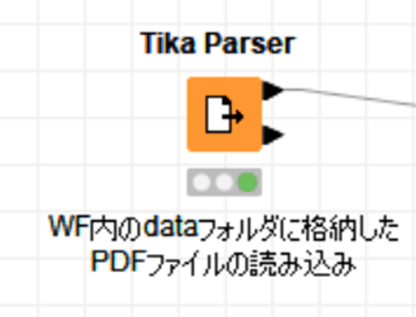
設定:
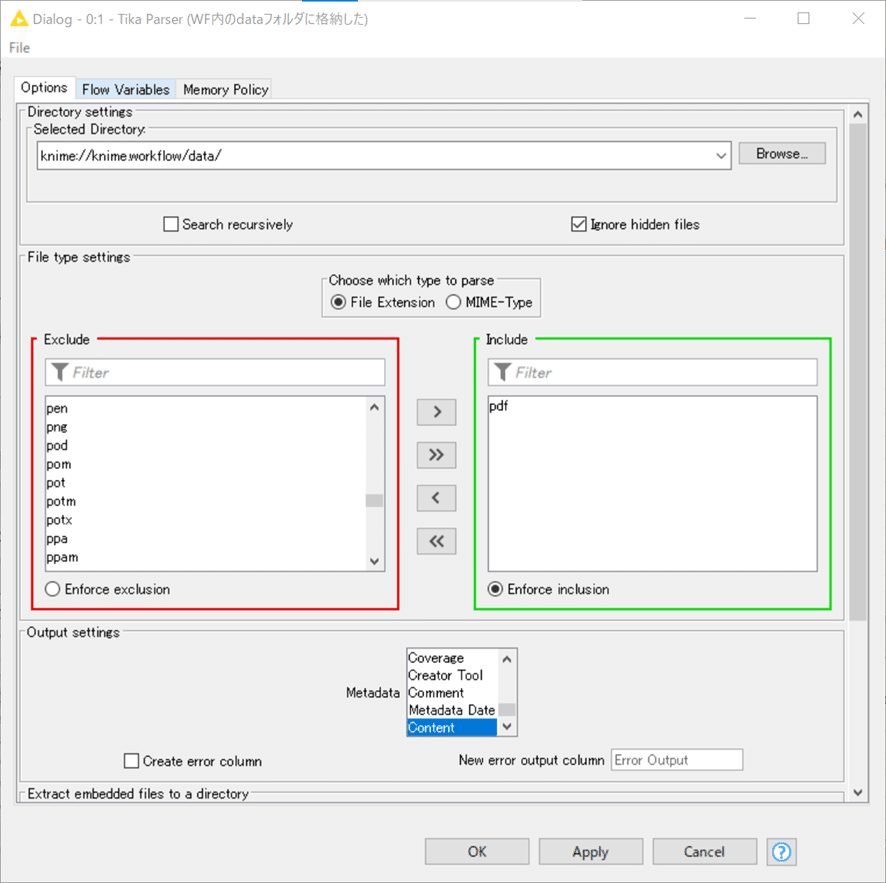
結果:

さて、これだけ見てもデータ重複にはなかなか気づきません。
実際には4回繰り返され、繰り返される前には

空白行3行ののちに
「Dnr: FAK/2011/84」以降の同じ内容が繰り返し入っています。
この法則性を利用して繰り返し部分と分けていきます。
【必要なデータの切出し】
Tika Parserは1つのセルに文章を丸ごと取り込んできますので、セルのデータを分割していく最初の一歩はCell Splitterノードがよく使われることでしょう。
【Cell Splitter】

設定:

先述の通り、重複する部分の間には空白行が3行続くという特徴がありました。つまり、文章の最後には4回改行が入りますね。
改行4連続を正規表現で表して、デリミタつまり切り分ける境目としました。

結果:

4つのセルに分けられていて、文頭に1行だけ空白行がある分ずれてはいるものの、同じ内容が書かれているとわかっていただけると思います。
【Column Filter】

今回重複分はいらないので1列目だけ残して出来上がりです。3ノードで効率はよかったと思います。
設定:

結果:

KNIME Hubに解答は上げています。
おまけ:
【JKI_036 感想戦】
先週のJust KNIME It! 第36回はタイムアライメントを練習しました。
1979年12月31日から1998年12月31日の土日を除くすべての日付の行を作る、すなわち祝日による欠損を埋めよという問題でした。

Timestamp Alignmentコンポーネントは与えられたデータで一番古い日付と一番新しい日付の間をすべて埋めたデータを発生できる機能を持っています。後で土日を除いて、結果として4959日間のデータになります。

公式解答はこちらです。

へぇー毎週のループにして、無駄に土日の荷付けを発生しなくしたんだと思いつつ、結果を見て日数が少なくて驚きました。4834行なので125日欠損が生じています。
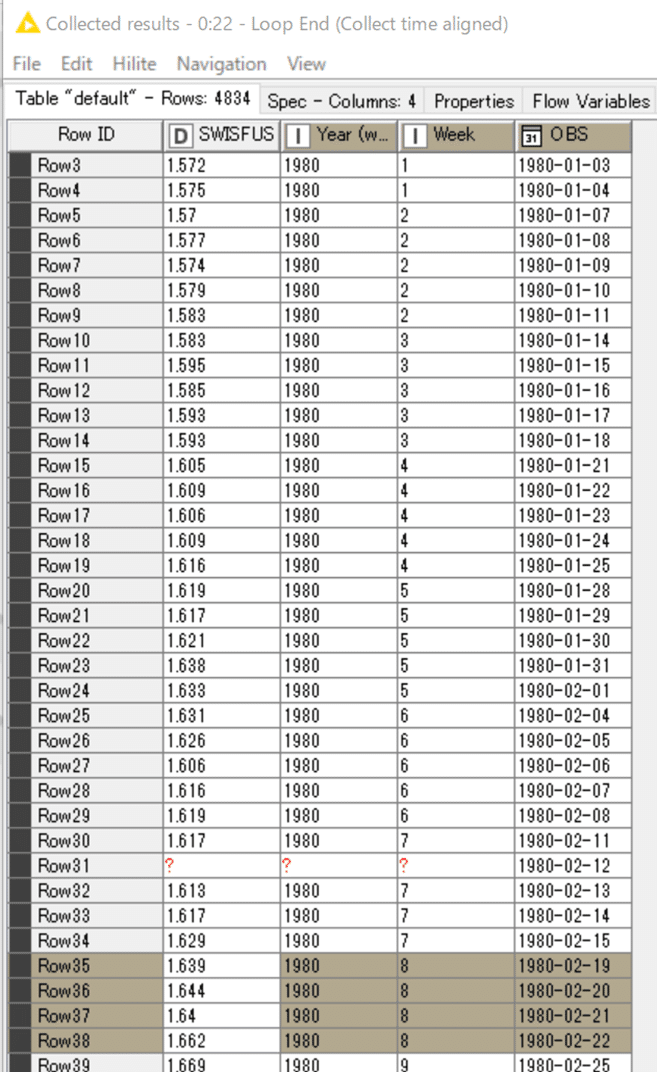
アクティベートした週は1980年2月18日(月)が欠損してしまっています。
実は先に紹介したコンポーネントの性質上、自明の欠損でして、月曜日か金曜日が祝日の場合はこの処理方法だと欠損を埋められないとわかります。
コンポーネントは確かに便利なのですが、その仕組みを理解しておけるといいですね。不具合発生時にどうしてこそういう結果になったかを見つけやすいです。
以下は全くの余談です。
5年前ぐらいと思いますが、AIが流行り出したころ、KNIMEやDataRobotで素人でも機械学習が手軽に使えるようになると喜んでいたら、ある玄人さんに苦言を呈されたことがあったなぁと思いだしています。ひとまず便利に体験をして面白いと思うのはいい。だが本当に実際に活用する前には深く技術理解を進めるべきだと。
全くもって正論です。今でもしばしば思い出すってことは、必ずしもできていないんですよね、実際。もう一回気を付けたいなと思いました。もう一回もう一回。
いいなと思ったら応援しよう!
