
Pythonでやってみた4:画像の自動取得

0.概要
画像の機械学習を実行する場合大量の画像データが必要になります。今回はWebから自動で画像データを取得します。
【参考】
会社で品質管理などをする場合は独自の画像データになるため自社のデータベースから取得するか、ない場合は自分で撮影する必要があります。
1.Pythonライブラリ:iCrawler
一つ目の手法としてはPythonライブラリの「iCrawler」を使用します。これにより簡単に画像が取得できます。
pip install icrawler注意点してiCralwlerの「GoogleImageCrawler」が使用できない可能性があるためBingを使用しました。
[In]
from icrawler.builtin import BingImageCrawler
import os
searchkeywords = '美女' # 検索するキーワード
savedir = 'photos_美女' # 画像を保存するディレクトリ
counts = 100 # 収集するデータ数
def getimages(q=searchkeywords, maxnum=counts, save_dir=savedir):
if not os.path.exists(savedir): # ディレクトリがなければ作る
os.mkdir(savedir)
print(f'{savedir}フォルダを作成しました。')
bing_crawler = BingImageCrawler(storage={'root_dir': save_dir})
bing_crawler.crawl(keyword=q, max_num=maxnum, filters=None) #filtersでは画像のサイズやタイプを指定可能
getimages(q=searchkeywords, maxnum=counts, save_dir=savedir) 
【出力結果】

これだけで簡単に画像が取得できました。今回は53枚取得できましたがエラーで取得できなかった分がはじかれたためです。
【参考1:train/val用データ取得】
別記事でフォルダ+画像取得する関数を作成したのでご参考までに
[IN]
import os
import glob
from icrawler.builtin import BingImageCrawler
#フォルダ作成
def make_dirs(rootpath='./'):
if not os.path.exists(f'{rootpath}/data'): os.makedirs(f'{rootpath}/data') #データ保存用:ルート
if not os.path.exists(f'{rootpath}/data/train'): os.makedirs(f'{rootpath}/data/train') #train用データ
if not os.path.exists(f'{rootpath}/data/val'): os.makedirs(f'{rootpath}/data/val') #val用データ
def getimages(keys, maxnum, save_dir):
for keyword in keys:
bing_crawler = BingImageCrawler(storage={'root_dir': save_dir})
bing_crawler.crawl(keyword=keyword, max_num=maxnum, filters=None) #filtersでは画像のサイズやタイプを指定可
#ファイル名の書き換え
_path_imgs = glob.glob(f'{save_dir}/*') #全ての画像パスを取得
path_imgs = [i for i in _path_imgs if os.path.basename(i)[0].isdigit()] #数字で始まるファイル名のみ処理
for idx, path_img in enumerate(path_imgs):
dirname = os.path.dirname(path_img)
extension = os.path.basename(path_img).split('.')[-1]
os.rename(path_img, os.path.join(dirname, f'{keyword}_{idx}.{extension}'))
#画像の取得
keywords = ['dog', 'cat'] #検索キーワードと保存先の指定
#フォルダ作成
make_dirs()
#データ取得
getimages(keys=keywords, maxnum=2, save_dir='data/train') #train用データの取得
getimages(keys=keywords, maxnum=2, save_dir='data/val') #val用データの取得
[OUT]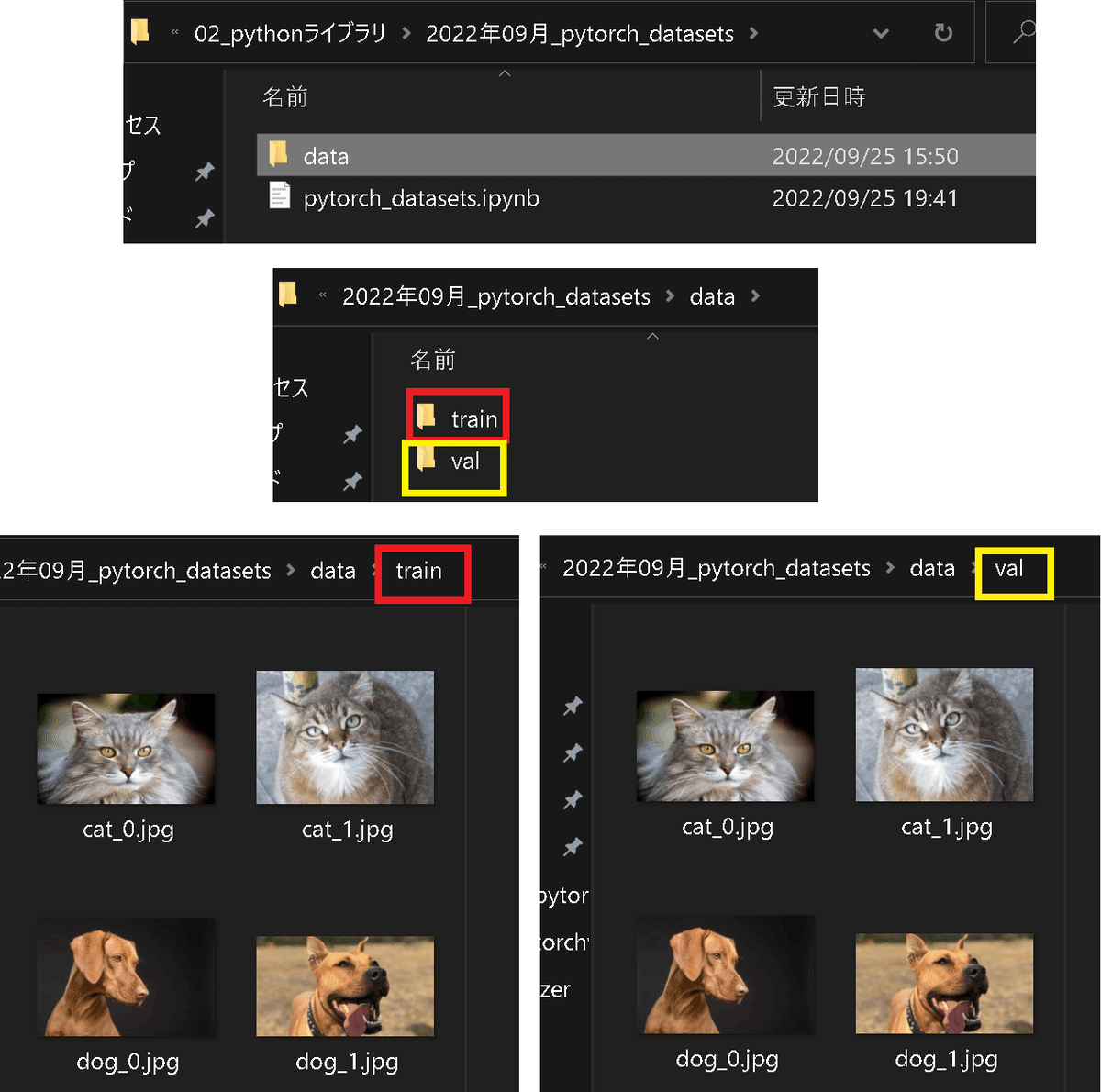
2.HTTPクライアント:urllib.request
ほしいファイルのURLが分かっているのであればPython標準ライブラリのurllib.requestが使用可能です。使用例としてスクレイピングで指定サイトのURLを収集して、そのURLを連続処理することでデータ取得できます。
画像は下記記事のファイルリンクを使用しました。
[In]
import urllib
url= 'https://note.com/api/v2/attachments/download/f6b77f70d3749b3a7bbda8830ff8083a'
urllib.request.urlretrieve(url, 'test.jpg')
[Out]下記の通りtest.jpgファイルが作成された
3.APIの使用
次はAPIを使用してデータを取得します。APIは簡単にいうと特定のサービスをHTTPクライアントなどを利用して簡単に使えるサービスです。
APIは企業が提供しているため使用できないサービスも多数あります。
3ー1.API:フォト蔵
API使用時に登録がいらないサイトとして「フォト蔵」があります。なお動画共有はサービスが終了しており写真のみとなります。「美女」写真がなかったのでデータ数が比較的少ない可能性があります。
3-1-1.HTTPクライアントによるAPIの利用
ざっくり説明すると、フォト蔵にキーワードを含めた依頼信号を送って結果を返してもらいます。
[In]
import requests
endpoint = 'https://api.photozou.jp/rest/search_public.json' #APIのエンドポイント
keyword = 'イケメン' #キーワード=美女は検索結果0だったため変更
url = endpoint + '?keyword=' + keyword #キーワードをURLに追加
res = requests.get(url) #APIを叩く
res.json() #JSON形式で返ってくる[Out]
{'stat': 'ok',
'info': {'CONTENTS_VIEW_LANG': True,
'NO_VIEW_FCEBOOK_TWITTER': False,
'photo_num': 100,
'photo': [{'photo_id': 269023538,
'user_id': 3097248,
'album_id': 8234203,
'photo_title': 'Nov12#最愛第5話映画の様な最終話の様なエンディングに日本列島号泣(TT)「それぞれの “最愛” という感情がたかぶり、そしてすれ違ってしまった」「繊細な演出、丁寧な伏線考察しながら今クール最高」',
'favorite_num': 1,
'comment_num': 0,
'view_num': 27,
'copyright': 'normal',
'original_height': 1151,
'original_width': 2048,
'geo': {'latitude': 0, 'longitude': 0},
'date': '2021-11-14',
'regist_time': '2021-11-20T22:53:15+09:00',
'url': 'http://photozou.jp/photo/show/3097248/269023538',
'image_url': 'http://kura4.photozou.jp/pub/248/3097248/photo/269023538.jpg',
'original_image_url': 'http://kura4.photozou.jp/pub/248/3097248/photo/269023538_org.jpg',
'thumbnail_image_url': 'http://kura4.photozou.jp/pub/248/3097248/photo/269023538_thumbnail.jpg',
'large_tag': '<a href="http://photozou.jp/photo/show/3097248/269023538"><img src="https://kura4.photozou.jp/pub/248/3097248/photo/269023538.v1637456437.jpg" alt="Nov12#最愛第5話映画の様な最終話の様なエンディングに日本列島号泣(TT)「それぞれの “最愛” という感情がたかぶり、そしてすれ違ってしまった」「繊細な演出、丁寧な伏線考察しながら今クール最高」" width="450" height="253"></a><br><a href="http://photozou.jp/photo/show/3097248/269023538">Nov12#最愛第5話映画の様な最終話の様なエンディングに日本列島号泣(TT)「それぞれの “最愛” という感情がたかぶり、そしてすれ違ってしまった」「繊細な演出、丁寧な伏線考察しながら今クール最高」</a> posted by <a href="http://photozou.jp/user/top/3097248">(C)@y4uk</a>',
'medium_tag': '<a href="http://photozou.jp/photo/show/3097248/269023538"><img src="https://kura4.photozou.jp/pub/248/3097248/photo/269023538.v1637456437.jpg" alt="Nov12#最愛第5話映画の様な最終話の様なエンディングに日本列島号泣(TT)「それぞれの “最愛” という感情がたかぶり、そしてすれ違ってしまった」「繊細な演出、丁寧な伏線考察しながら今クール最高」" width="240" height="134"></a><br><a href="http://photozou.jp/photo/show/3097248/269023538">Nov12#最愛第5話映画の様な最終話の様なエンディングに日本列島号泣(TT)「それぞれの “最愛” という感情がたかぶり、そしてすれ違ってしまった」「繊細な演出、丁寧な伏線考察しながら今クール最高」</a> posted by <a href="http://photozou.jp/user/top/3097248">(C)@y4uk</a>'},
{'photo_id': 269023536,
'user_id': 3097248,
show more (open the raw output data in a text editor) ...
'url': 'http://photozou.jp/photo/show/207472/263869598',
'image_url': 'http://art5.photozou.jp/pub/472/207472/photo/263869598.jpg',
'original_image_url': 'http://art5.photozou.jp/pub/472/207472/photo/263869598_org.jpg',
'thumbnail_image_url': 'http://art5.photozou.jp/pub/472/207472/photo/263869598_thumbnail.jpg',
'large_tag': '<a href="http://photozou.jp/photo/show/207472/263869598"><img 3-1-2.APIの戻り値を処理
返り値のJSONはごちゃごちゃしているように見えますが分解してみると下記の通りです。
「info_Key内のphoto_Keyの値がリスト->リスト内のimage_url_KeyがURL」
返り値からURLを抽出して画像をDLするコードは下記の通りです。
[In]
import requests
import urllib
#APIを叩く処理
endpoint = 'https://api.photozou.jp/rest/search_public.json' #APIのエンドポイント
keyword = 'イケメン' #キーワード=美女は検索結果0だったため変更
url = endpoint + '?keyword=' + keyword #キーワードをURLに追加
res = requests.get(url) #APIを叩く
#返り値から画像のURLを抽出してダウンロード
datas = res.json()['info']['photo']
print(type(datas), len(datas))
datas = datas[:10] #10件だけ取得
savedir= 'photo_フォト蔵' #保存するディレクトリ名
if not os.path.exists(savedir): # ディレクトリがなければ作る
os.mkdir(savedir)
print(f'{savedir}フォルダを作成しました。')
for idx, data in enumerate(datas):
url = data['image_url'] #画像のURL
filepath = os.path.join(savedir, f'{idx:03d}.jpg') #保存するファイル名を指定
urllib.request.urlretrieve(url, filepath)
3-2.Flickr
APIの登録が必要ですが別のサービスとしてFlickrがあります。
3-2-1.事前準備
【ライブラリのインストール】
事前に専用のライブラリをインストールします。
pip install flickrapi【API登録】
ライブラリとは別にAPIの登録が必要となります。
APIの発行手順は上記サイトから下記の通りです。

発行されたKeyとSecretをメモしておきます。
3-2-2.APIを叩いて写真を取得
KeyとSecretを取得した値に入れ替えるとAPIで写真が取得できます。
[In]
Key = '47dfxxxxxxxxxxxxxxxxxx2d'
Secret = 'ff5xxxxxxxxxxxxxxxxxaf'
from flickrapi import FlickrAPI
import urllib
def jsondatas_flicker(Key, Secret, keyword):
flickr = FlickrAPI(Key, Secret, format='parsed-json')
photos = flickr.photos.search(
text=keyword, # 検索するキーワード
per_page=10, # 取得する画像の数
media = 'photo', # 写真のみ
sort = 'relevance' # 関連度順
)
return photos
def download_flickr(photos, savedir):
if not os.path.exists(savedir): # ディレクトリがなければ作る
os.mkdir(savedir)
print(f'{savedir}フォルダを作成しました。')
for idx, photo in enumerate(photos['photos']['photo']):
url = 'https://farm{farm}.staticflickr.com/{server}/{id}_{secret}.jpg'.format(
farm = photo['farm'],
server = photo['server'],
id = photo['id'],
secret = photo['secret']
)
filepath = os.path.join(savedir, f'{idx:03d}.jpg') #保存するファイル名を指定
urllib.request.urlretrieve(url, filepath)
photos = jsondatas_flicker(Key, Secret, keyword='美女')
download_flickr(photos=photos, savedir='photo_flicker')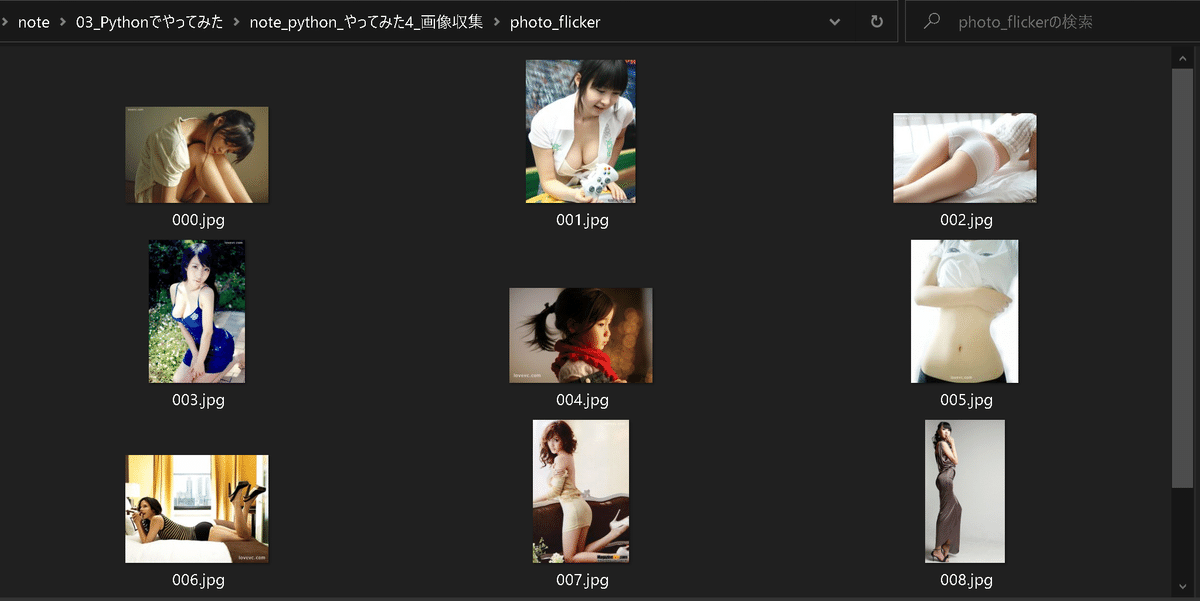
photo_flickerフォルダに美女の写真が10枚取得されました。
あとがき
とりあえずgifが見れない可能性があるので、それはnoteのアップデート後で対応予定
pixelサイズの編集でgifが投稿できそう。やっと一歩進んだ!
この記事が気に入ったらサポートをしてみませんか?