
【Calm2-7b】サイバーエージェントの最新LLMが優秀すぎたので、ChatGPTと比較レビューしてみた

Calm2-7b(CyberAgentLM2-7B)は、サイバーエージェントが公開した最新の日本語LLMです。
このモデルは、既存のLLMをベースにするのではなく、1から独自に構築されており、チューニングモデルではなんと32,000トークンの入出力に対応しています。
GPT-4に迫る量のトークンに対応しているのはすごいですよね!
今回は、Calm2-7bの概要や使ってみた感想をお伝えします。
是非最後までご覧ください!
Calm2-7bの概要
Calm2-7bは、サイバーエージェント社が2023年11月2日に公開した最新の日本語LLMです。
このモデルは、ここ最近の日本語LLM開発のトレンドになっている、既存のLLMをベースに継続事前学習を適用して構築する方法ではなく、1から新規に構築されたモデルです。
最近の日本語LLMはほとんど継続事前学習で構築されていたため、それらと比較して出力にどのような差があるのか気になりますね!
Calm2-7bは、約1.3兆トークンの日本語と英語の公開データセットでトレーニングされており、70億のパラメータを持っています。
モデルの種類は、ベースモデルのCalm2-7bとチャット形式でのチューニングを行ったCalm2-7b-Chatの2種類です。
ベースモデルのCalm2-7bは、4096トークンの入出力に対応しており、チューニングモデルのCalm2-7b-Chatは、なんと32,000トークンの入出力に対応しており、日本語では約50,000字を処理できることになります。
これは、他の多くのモデルの対応トークン数を上回っており、このモデルの注目ポイントと言えます。
そんなCalm2-7bは、Hugging Faceで公開されており、誰でもダウンロードして使うことができます。
また、Apache License 2.0で提供されているため、商用利用可能になっています。
それでは、概要の説明はここまでにして、早速ダウンロードして使ってみたいと思います!
その前に、他の日本語LLMとの比較表を掲載しておきます。是非参考にしてみてください。
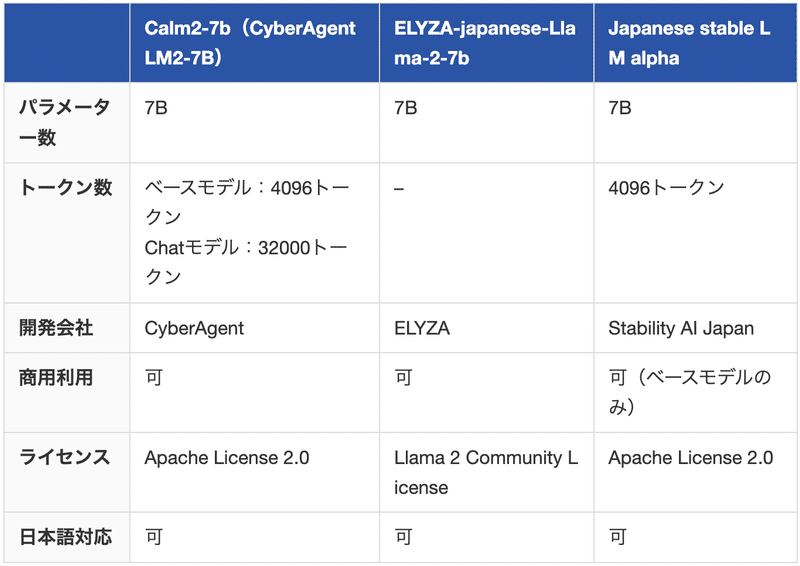
なお、Stability AI最新のLLMであるJapanese stable LM Betaについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Japanese Stable LM Beta】国内最大級日本語LLMをGPT-4と比較してみた
Calm2-7bの使い方
今回は、入出力トークン数が大幅に強化されたCalm2-7b-Chatを使っていきたいと思います。
なお、今回はより安定した出力をさせたいので、Google Colab proでA100GPUを使用してモデルを実装、実行します。
動作自体はT4GPUなどでもできるようです。
モデルは以下のページで公開されています。
まずは必要なパッケージをインストールします。
!pip install transformers accelerate続いてモデルとトークナイザーのロードを行います。
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
assert transformers.__version__ >= "4.34.1"
model = AutoModelForCausalLM.from_pretrained("cyberagent/calm2-7b-chat", device_map="auto", torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained("cyberagent/calm2-7b-chat")
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)モデルのロードは約2分ほどで完了しました。
これで推論を実行する準備は完了しました。
早速使っていきましょう!
Calm2-7bを実際に使ってみた
これ以降は、以下の記事からご確認ください。
他の記事もご覧になりたい方は、こちらをご覧ください。
この記事が気に入ったらサポートをしてみませんか?