twitterで公開中の、小説家になろうの統計の大雑把な作成方法(具体例つき)

大雑把な流れ
似たようなものが沢山あるので需要はなさそうですが、一応twitterで公開している統計情報の作成方法について軽く記録していきます。
統計の作成には主に「なろう小説API」とpython、googleスプレッドシート、Canvaを利用しています。
小説家になろうの運営様に問い合わせたところ、APIを介さないプログラミングはお断りしているという返信を頂いたので、直接的なスクレイピングは行っていません。
手順としては、
1、pythonのスクリプトを実行し、なろう小説APIから目的の情報を抽出
2、抽出した情報をスプレッドシートに書き込む
3、スプレッドシートやpythonのスクリプトを適宜用意、利用して欲しいデータ形式に変更
4、スプレッドシート、もしくはCanvaを使用し、グラフを作成
5、データとして公開
という流れです。
スクリプトは全て独自で用意したものを使用しています。
スクリプト開示は基本受け付けておりませんが、どういうシステムになっているのか、また一部の独自関数については、アマチュアの拙いものでよければ、DMなどで直接ご相談していただければお答えします。
割りと扱うデータの母数が膨大になりがち(20万~2千程度)なので、スプレッドシートのマクロはあまり利用しません。単にマクロの言語であるJavaをほとんど学んでいないからという理由もありますが。
グラフの元データとなった表などについては、需要がありそうなら今後積極的居に公開していく所存ですが、なにぶん情報量が膨大なので、形式に迷っています。スプレッドシートで共有するか、どうするか……。ご意見があればお願いします。
具体例
さて、粗方説明を終えたところで、最後に例を示して終わろうと思います(思ったよりアクセス数が多くなっているので追記しますが、ここで示している方法にはいくつか問題点があります。いつか書き直すのでお許しを……。一応後述の問題点含めて、初心者の方には有益な内容にはなっているはずなので、それでも良ければ読んでいってください)。
以下のようなグラフの作成手順を具体的に示します
①、なろう小説APIを使って初回掲載日時、最終掲載日時の情報を得る。
この時、pythonのスクリプトを用いて、具体的には以下のようなURLにアクセスします。
https://api.syosetu.com/novelapi/api/?of=gl-gf&order=weekly&lastup=1668524400-1669129199&lim=500&st=1&libtype=2
上のパラーメータの詳細については、小説APIのマニュアルを御覧ください。以下でも一応大雑把に説明していきます。
"of=gl-gf"という部分では、所得する情報を、小説の最終掲載日と最新掲載日に限定しています。限定しなくとも目的の情報は得られますが、応答までに時間を要する上、サイトに負荷をかけるのでなるべく必要最低限の情報で済ませるようにします。
"order=weekly"では出力順序を週間ユニークユーザー数順にするように指定しています。これが割りと大切。なぜ週間ユーザー順なのかは後から説明します。
lastupの後に続いている数字はUNIXタイムスタンプで、日付を指定しています。
この場合だと、11月16日の0時ジャストから、11月22日の23時59分59秒までのちょうど7日間に最終部分が掲載された作品に限定して出力しています。
このとき、後者の時間を11月23日の0時ジャストにしてしまうと、1秒多めに情報が所得されてしまいます。上に貼り付けてあるグラフからも分かる通り、なろうの作品の更新時間は0時がほぼ最多なので、その1秒だけで結構なズレが生じるので注意しましょう。
掲載時間のデータがほしい場合などは、データの範囲をN週間分にして、どの曜日も必ず同じ回数ずつデータの中に入っている環境にすると偏りが少なくて済みます。
"lim=500"では、小説の出力数を指定しています。500は最大値です。
つまり、APIのシステムの都合上、一つのパラメータで即時的に所得できる情報は500作品が限界ということです(一応出力順序を新着更新順などにしておくと、重複にさえ気をつければ、段階的に500作品以上の情報を所得することは可能です)。
無作為に集められたわけでもない500作品の情報だと、偏りが明らかで、流石に統計データとして正しく機能しません。そこで、その後ろにある"st=1"の値をいじります。これは表示開始位置を指定している部分です。
例えば、"order=weekly","lim=500"の状態で"st=200"にすると、200番目に週間ユニークユーザーが多い作品を先頭に500作品の情報が出力されます。stの最大値は2000です。なので、これを利用してst=1をst=501などに変更していけば、一つの条件につき最大で2499作品分の情報が所得できます。
この時、出力順序が、すぐに変動してしまうような日間ポイント順や最終掲載順だと、収拾したデータに重複が発生したり穴ができたりすることがあります。なので、「毎週火曜日の早朝」と、情報が更新される時間がおおよそわかっていて、且つ更新回数の少ない週間ユニークユーザー数が、そういったエラーのないデータを集めるための一番の近道なのです。
よって、"order=weekly"は、上述したような方法で情報を収集する場合、忘れてはならないパラメータなわけです。
言うまでもないことだとは思いますが、プログラミングでこのページにアクセスする際には、サーバーになるべく負荷をかけないように、アクセス間隔を明けることも忘れないようにしましょう。
ちなみに、このページに、プログラミングを介さずGoogleChromeで直接アクセスしてみると、こんな画面が表示されます。

allcountというのは、検索条件に見合った作品の合計数。このページには、そのうちユニークアクセスが上位500位以内の全ての作品の、初回掲載日と最終掲載日が出力されています。
そうなんです。実はここでCtrl+Aで全選択してコピーしてしまうと、プログラミングなしでも情報を得ることができます。それを使える形に直そうとなると流石にプログラミングなしだと手間ですけれど、エクセルやスプレッドシートなどの関数を利用すれば、あるいはある程度の処理が可能かもしれません。
プログラミングはハードルが高い、という方は挑戦されてみてはいかがでしょうか。
余談でした。話を戻しましょう。
さて、ところで皆さんお気づきでしょうか。上の画像を見る限り、上述した方法には問題点がいくつかあります。
1つ目は、そうです。
allcountが8937なんです。
先程も説明したように、一つの条件につき最大で2499作品までの情報しか出力できません。ということは、このままだと条件に見合う作品を全て所得することがません。
この問題点を改善するために、lastupの後の値をいじって最終更新時刻の間隔を短く細切れにして、条件を満たす全ての作品の情報を所得します。
しかし2つ目の問題点は解消不能です。
出力順序の話で書いたように、最終掲載時刻は変動するし、全作品データを所得しない限りは偏りも生じる、ということです。
例えば、データを所得している最中に、2週間前が最終掲載時刻だった作品が更新されたりすると、場合によってはデータに重複と穴が生まれてしまいます。また、最終掲載時刻で2周間ぶんのデータを取ったとしても、火曜日の夜にデータ所得を行ったとすると、最終掲載時刻は全体に火曜日に偏ります。すると、正しいデータを得られない可能性があります。
なので実は、変動のない初回掲載時刻をもとに同じようなことをしているんですが、これはなぜかAPIのマニュアルに載っていなかったので、特に問題はないと思いますが、念のために具体的な話は控えておきます。
教える気がないのならどうして具体例にこのグラフの作成方法を選んだんだよと苦情が来るかも知れませんが、マニュアルに載っていないことに気づいたのがほとんど書いてしまった後だったので……まあ、筆者の怠惰です。
需要がほとんどない前提で書いている事もあって、書き直すにはモチベーションが足りません。本当に申し訳ない……。
一応ここで紹介した方法も試してみたところ、大差はなかったことを言い訳に、とりあえずこれでよしとしています。
そうして得た情報を、プログラミングを用いて利用しやすい形にします。こればかりは皆さんの好みです。参考までに、私はデータの順序はそのままで、種類別に分けて複数のファイルに保存しています。
違う作品のデータの間を改行で区切っておくと、スプレッドシートに反映するときに非常に楽です。
その後、スクリプトを用いて掲載時間のデータから年、月、日、それから分の一の位と秒を削除して、10分ごとの、時刻だけのデータを新たに作成。それをスプレッドシートを用いて昇順に直し、グラフ化して、「集計」という欄にチェックを入れれば終了です。
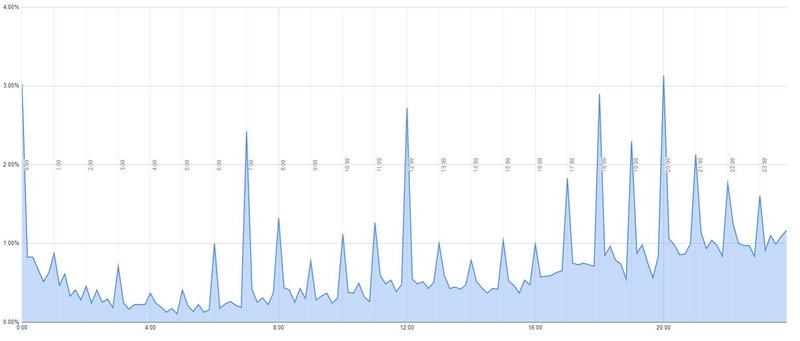
以下はそれの母数を5週間ぶんにして、更にプログラミングを用いて、縦軸を作品数ではなく割合として編集したものです。少し古いデータですが、完成するのはこんな感じ。
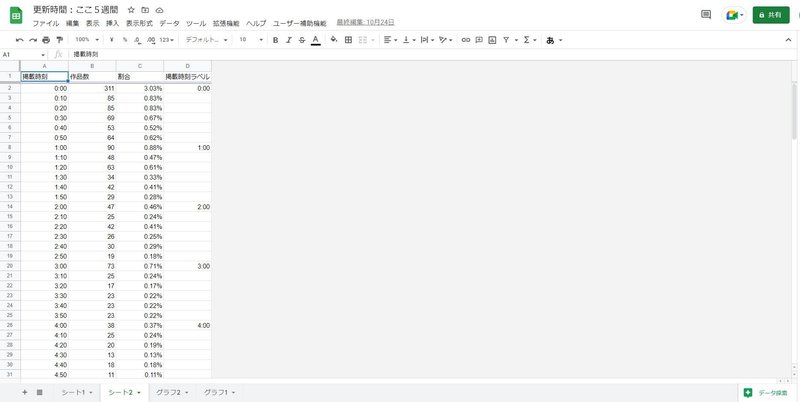
ちなみにこのグラフの元データはこんな感じ。
ちなみに、上のグラフは初回掲載時刻をもとに作っていますが、最終掲載時刻をもとに作ってもほとんど変わらないものが得られます。気が向けば試されてみてはいかがでしょう。
以上。我流のグラフの作り方と、その手順でした。
この記事が気に入ったらサポートをしてみませんか?