
Python初心者 無料で学習を極める(7)

「機械学習のためのpython入門講座」SkillupAI様のday7目の講座から学んだことを記載していきます☆
本記事は、「あ!どんなふうにあれ使うっけ?」っと言うときに参考にしてもらえると嬉しいです。一通りpythonに慣れてきたら、実際のプログラムを載せるなどして皆さんと一緒にレベルアップができればと思います!
それでは7日目行ってみましょう!
day7:データの前処理
※下準備まで
ちょっと、記載を行って情報過多になってきたので、分割します!
言葉の定義
目的変数 : 予測したい変数
説明変数 :目的変数を予測するためにモデルに投入する変数
使用データの確認
データ分析を行う上で有名なデータセット?らしい タイタニックに関するデータを用いていきます。下記のURLから入手できますのでご参考に!
前処理のステップ1:インポート設定
①ライブラリのインポート
・numpy , pandas , seaborn , matplotlib を使える状態にしましょう
# ライブラリのインポート
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
%matplotlib inline
②データセットのインポート
・訓練用データ、 テスト用データ をCSVファイルからインポートしましょう。また、それがまとまった状態を一つのリストにしましょう。
# データセットのインポート
#下記はpythonの作成コードと同じディレクトリにtitanicフォルダがある状態を意味しています。
train=pd.read_csv("./titanic/train.csv")
test=pd.read_csv("./titanic/test.csv")
前処理のステップ2:データの概要を確認
①データの状態確認
以前のデータ処理でもあったように、入手したデータの状態を確認しましょう。データの概要を確認するのは、 .info() でしたね。
train.info() と test.info() で状態を確認しましょう。
②データの欠損値及び文字列の確認
入手したデータには、欠損している部分や、学習に活用できない文字列表記などが存在します。
・どの項目に欠損値があるのか
・どの項目のデータが文字列なのか
を確認しましょう。
前処理のステップ3:データの詳細確認(説明変数)
説明変数に対する傾向を確認していきましょう。
①欠損値の抽出
今まで学習した関数が出てきますか?下記のコマンドで欠損値の数を確認しましょう
#カラム毎の欠損値の数を表示
train.isnull().sum()
#カラム毎の欠損値ではない数を表示
train.notnull().sum()
②外れ値の確認
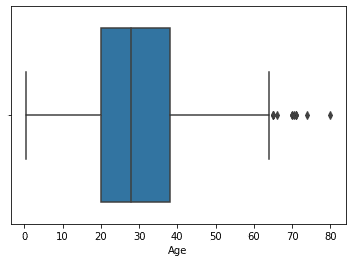
外れ値を確認する場合は、pandas で箱ヒゲ図で可視化してみましょう。
可視化してみて感じる違和感・・・。例えばですが、年齢です。
下記の図から、乗車する人の年齢に制限がある訳ではないので、この箱ヒゲ図だけでは誤った判断をしてしまいますね。
ここでさらに登場するのが、年齢毎の傾向分布(棒グラフ)を確認してみましょう。
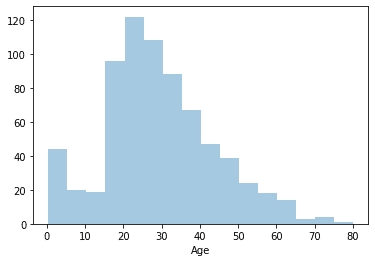
上記の図を確認すると、一つの仮説が浮かびます。
仮説:年齢によっては人数が一人のところもあるのでは?
確認してみましょう。
#それぞれの年齢における人数をカウントする関数を用いて確認し、
#人数が多い順 にカウントされているため、
#最後から 何歳の方が少ない状態 と考えることができる
#そこで、最後からのデータを確認する関数として .tail() を用いる
#例として15番目まで表示
train["Age"].value_counts().tail[15]
前処理のステップ4:データの詳細確認(目的変数)
目的変数に対する傾向を確認していきましょう。
今回の目的変数は、Survived となります。その為、何が関係しているか。を確認しましょう
①相関の確認
目的変数との関係として、何が一番関係しているか可視化を行いましょう。
相関係数で可視化と言えば、 pandas.heatmap( ) がよさそうですね。
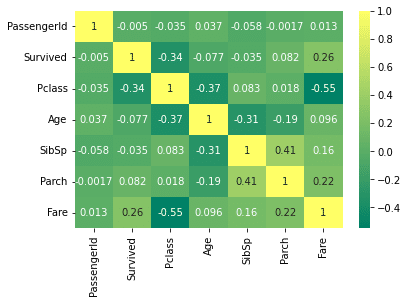
この結果から、「Survived」との相関が高い項目が何か。を確認していきます。そうすると、例えばですが、passengerld は全く相関が無い事が見えてきますね。注意が、相関係数のみで決めつけた判断を行う事はやめましょう。理由はこのサイトが分かりやすいです。一度見て下さいね。
②データの意味確認(仮説)
データの意味を確認し、それぞれの項目が何を意味するのか。を考え、仮説を立てていきましょう。例えばですが、
・【仮説1】男性と女性で衣装が異なる為、海に投げ出された時に、服の重さが重くなり沈みやすかったのではないか。
→ 「性別」と「生存」を確認
・【仮説2】仮説1に対して、そもそも乗客の人数も異なる為、生存の割合が変化するのではないか。
→ 「性別」と「生存・死亡」を確認
・【仮説3】乗船した場所によって、その国・地方の人間の特徴によって生存率が異なるのではないか。
→ 「乗船した港」と「生存」を確認
ここでは、どれだけの仮説を考えることができるか。が重要になります。まずは目的変数と関わってる様に感じる部分を見て下さい。
前処理のステップ5:不要そうなデータへの処理
データを確認して、目的変数との関係も確認し、
データの意味としても関連性が低いものは使用しない という方法が必要となる
例)人の名前 ・ 人に割り振られたID ・ チケットの種類
また、欠損値があまりに多いデータは削除することも可能
ここまでのステップで、
前処理へ使用できるデータの種類 を決定できたことになります!
いよいよ、前処理の実施です!
情報量が多くなった為、次の記事で記載することにしました。
こちらをご覧ください。
よろしければサポート頂けると幸いです!子供へのパパ時間提供の御礼(お菓子)に活用させて頂きます☆