【Style-BERT-VITS2】感情豊かな音声合成と音声学習を試してみた

■記事の対象ユーザ
1.VOICEVOXより感情豊かな音声合成(TTS)ツールを探している
2.音声モデルを学習させたらどんな感じになるのか気になる
3.GitやPythonの環境構築などの基本的な操作がちょっと分かる
■ようするに?
Style-BERT-VITS2の概要説明と使ってみた結果・学習してみた感想を書いた記事になるよ。公式チュートリアル動画がめちゃくちゃ親切なのでハウツーというよりは結果がメインになるよ。
0.はじめに
Twitter(現X)のTLで、より感情表現が豊かでオリジナル音声も作れる。
ということで「Style-Bert-VITS2」と「ElevenLab」の2つは大分前から認識はしていたのですがLoRA沼に浸かってたり配信アシスタントAI実装してたりして全然追えてなかったので、今回ようやく環境構築に踏み切りました。

AITuberシロハナちゃんでお馴染みのyukiさんが主要なTTSの紹介してくれているのでまずはこちらをご覧ください。とても丁寧に解説してくれています。
VOICEVOXは既に使用しているので、他の3つについて確認した所感ですが
COEIROINK → 公式や公認キャラの品質はVOICEVOXと遜色なし。ユーザー作成の300以上のキャラが居るので同じ声はいやだなーって時に重宝しそう。感情表現はVOICEVOXとそこまで差異が無かった。
Style-BERT-VITS2 → 今回試してみて感情表現にビビりました。学習に関しても(音声素材をどうにかすれば)簡単なので多少AI関係のリポジトリをかじったことがある方なら問題なく使えると思います。
ElevenLab → Webで完結しているの点、感情表現もStyle-BERT-VITS2同様にゆたかな点は流石です。ただ有料サービスである点と詳細な学習には上位プランが必要になるため多少はmoneyが必要。
今回は一番私のニーズに合っていそうなStyle-BERT-VITS2を導入して、試行したことについて書いていきます。
1.利用開始まで
公式が丁寧なチュートリアル動画を用意してくれているのでご覧ください。
何でこんな覚えにくい名前にしたんだろうかと前々から思ってたけど
「BERT」という文章から感情を理解するAI
「VITS2」という音声を生成するAI
を組み合わせているから、こんな名前になっているのね。はわく。

チュートリアルではインストールbatを使ってるけど、普通にgitからやる方法もいつも通りなので、普段からリポジトリとvenv触っている人なら問題なく構築できます。かんたん!
インストールしたい任意のディレクトリ(※)でPowerShellを開いて以下を実行
※日本語の入ったパスはNGとのこと
# Gitでリポジトリ取得
git clone https://github.com/litagin02/Style-Bert-VITS2.git
# 取得したディレクトリへ
cd Style-Bert-VITS2
# 仮想環境の作成
python -m venv venv
# 仮想環境の有効化
.\venv\Scripts\activate
# 必要なpythonパッケージの取得
pip install "torch<2.4" "torchaudio<2.4" --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
# Style-Bert-VITS2のデフォルトモデルの取得
python initialize.py準備が完了したら「Editor.bat」を起動します。

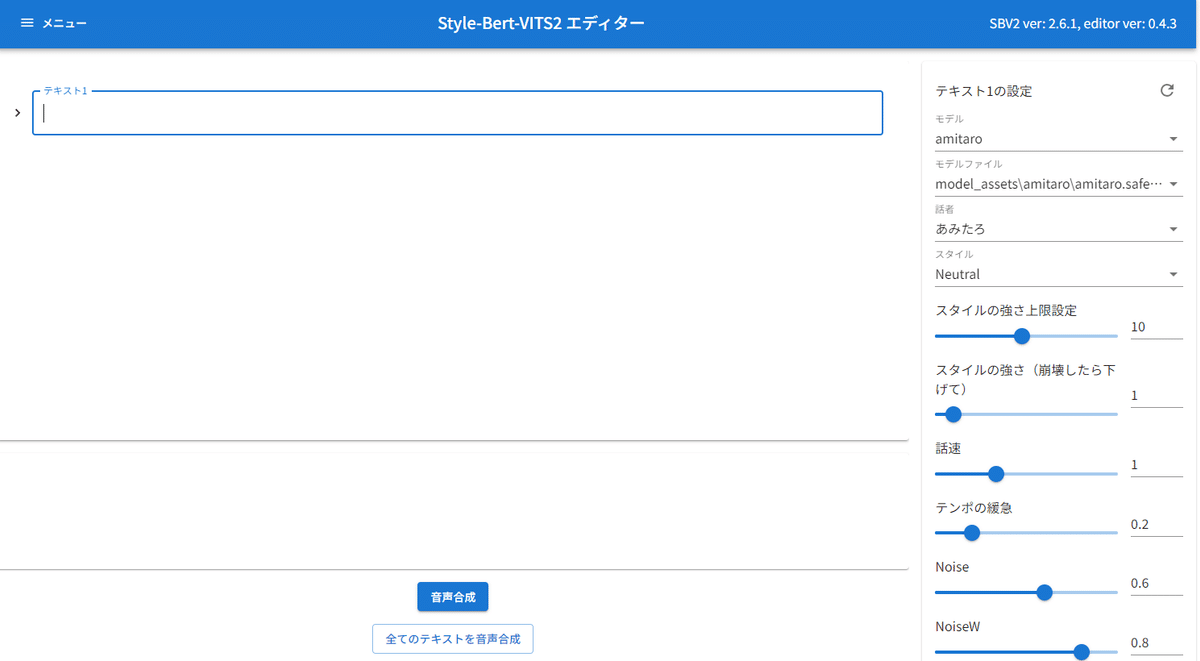
試しにデフォルトモデルとしてダウンロードされている、あみたろさんの声で自分がずんだもんだと信じさせられる様子を演じて貰いました。

2.学習の仕方
Style-BERT-VITS2では新たな音声モデルの学習も同じツール群の中で出るようです。チュートリアル動画に沿ってやっていきます。
まず学習素材となる音声データですが、30分相当は必要だとのこと。
幸いにも私は自分のゲーム実況動画から音声だけを取り出せるので、これを利用することにします。

取り出した音声をwav形式で保存し、Style-BERT-VITS2の展開先フォルダ内の「inputs」フォルダに配置しておきます。(フォーマットはwavじゃなきゃだめらしいです。)
データセット作成ツール
Style-BERT-VITS2の展開先フォルダから「dataset.bat」を起動します。
①スライス
モデル名を適当に入力したら、初期設定のままで「スライスを実行」。
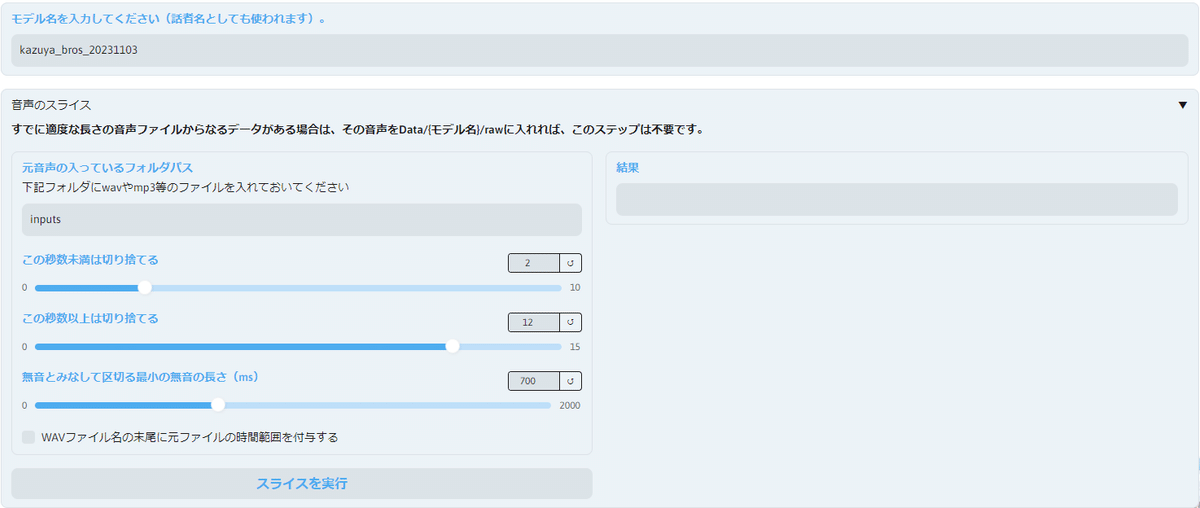
1時間ほど動画でしたが、約30秒ほどで分割が完了。40分432ファイルくらいになりました。

分割後のファイルはStyle-BERT-VITS2の展開先フォルダから
「Data」→「入力したモデル名(上ではkazuya_bros_20231103)」→「raw」に保存されています。
②文字起こし
OpenAIの文字起こしのOSSであるWhisperを使って文字起こししてますね。
「HuggingFaceのWhisperを使う」に✅が入っていると、裏側でモデルをダウンロードしているような挙動をしており中々進まなかったのでチェックを外してチュートリアル動画と同じ設定でスタート。
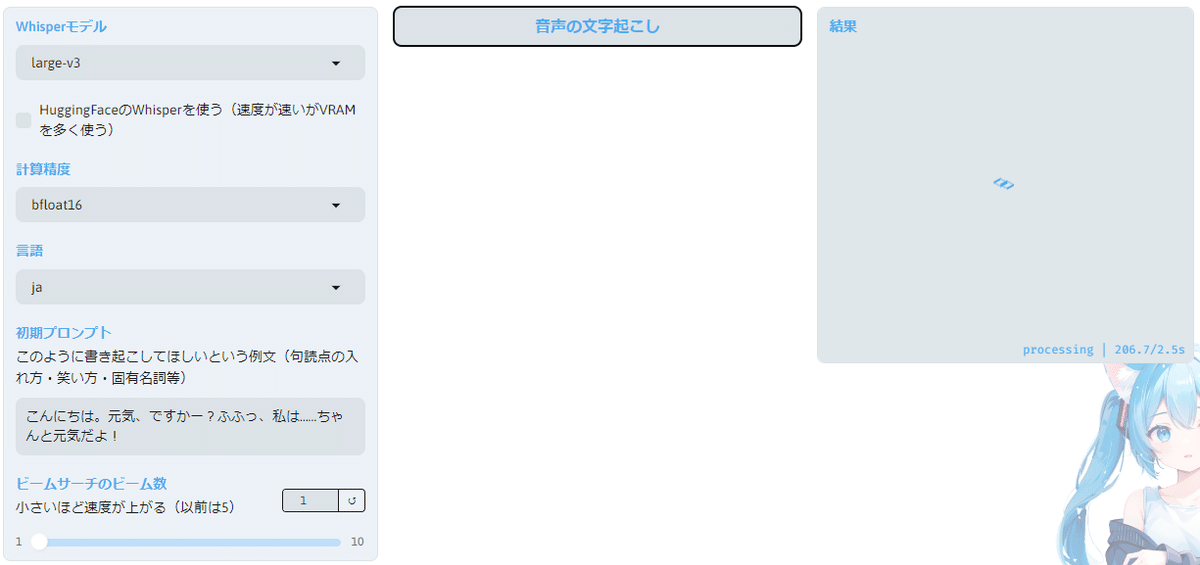
実行するとエラーが・・・

libiomp5md.dllが既に初期化されているとか何とか出ています。インターネットで調べると重複してdllファイルがあると出るっぽいので
Style-BERT-VITS2のディレクトリで「libiomp5md.dll」ファイルを検索
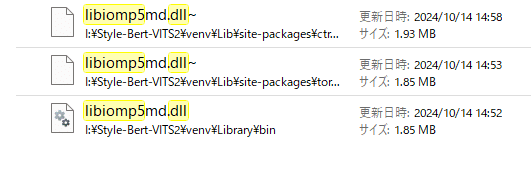
本体っぽい一番下を残してリネーム(削除は怖いので)して再試行

本当にこれで良いのかはともかく、432ファイルが4分ほどで完了しました。
「Data」→「入力したモデル名(上ではkazuya_bros_20231103)」に
「esd.list」が出来上がっているので確認すると、ちゃんとWhisperで文字起こしした結果が格納されていました。

ここまできたら「dataset.bat」は用済みなのでプロンプトを閉じます。
③学習
学習用ツールも別にあるらしいので
Style-BERT-VITS2の展開先フォルダから「Train.bat」を起動します。

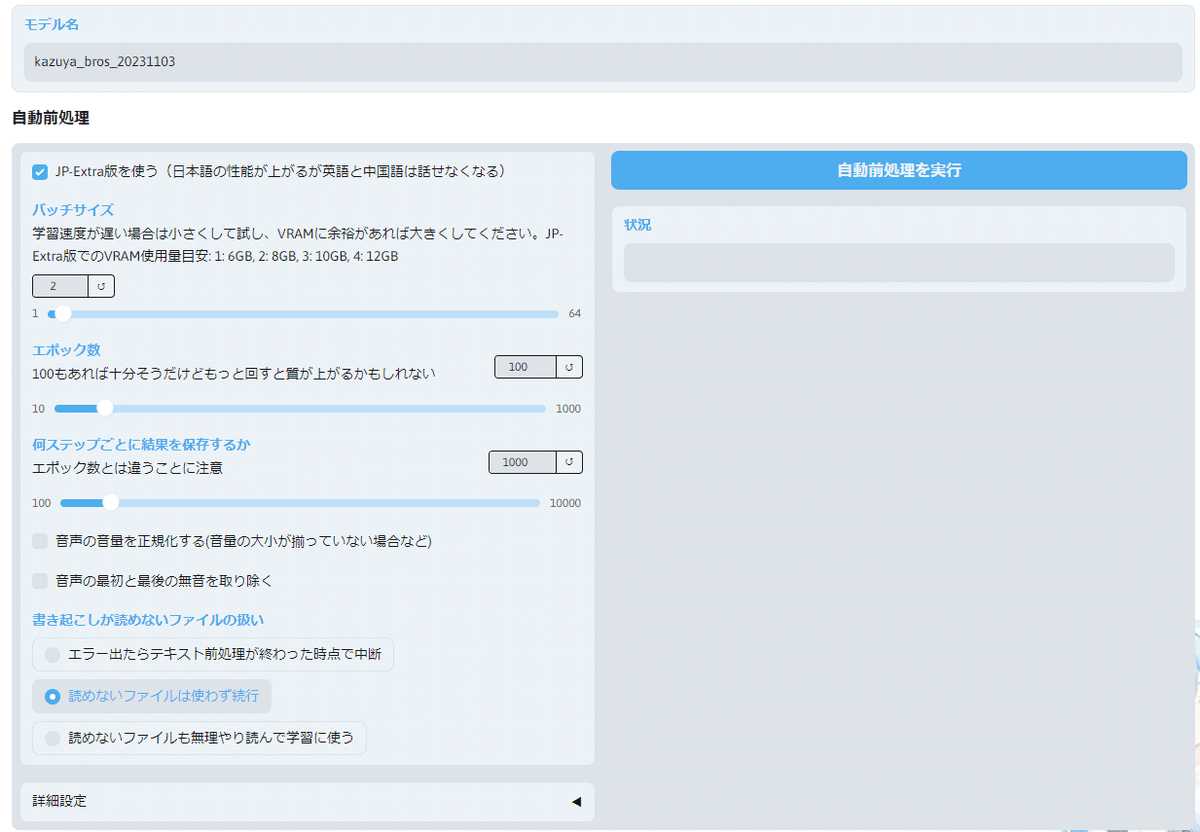
新しくブラウザで画面が立ち上がってくるので
モデル名:②で入れたモデル名(今回はkazuya_bros_20231103)
バッチサイズ:目安の通りに2を選択(私の環境がRTX3080 VRAM10GBなので)
それ以外:まずはデフォルトで試してみる。
設定したら「自動前処理を実行」。数分で終わりました。


事前処理が成功で帰ってきたら下の方にある「学習を開始する」でスタート
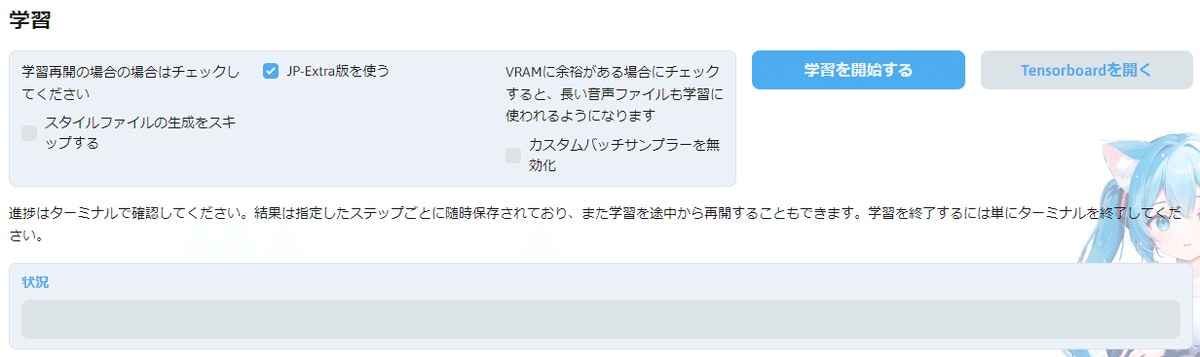
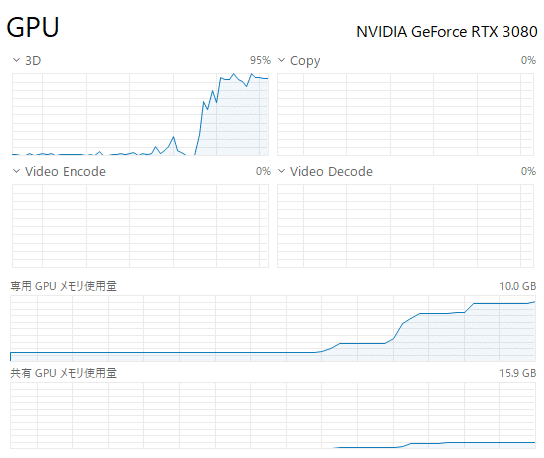
コマンドプロンプト側で見てみると、21000ステップで3時間半ほど。
※ここは学習するVRAM環境で全然違うので参考まで

④試行
学習が完了すると「Editor.bat」で学習したモデルが選べるようになっているので、モデルを選択し試行することができます。
「音声学習できたけど、案の定全部実況声だからスタイルをわけようがどうしようが、同じ声にしかならないのだ!」
自分のゲーム実況の音声から抽出した音声素材で学習したので、喜怒哀楽がなく、一本調子なモデルが出来上がってしまいました。

よりよい学習のために
雑談配信のデータのような普通にしゃべっている音声だけでは音声モデルの学習には適していないようで、研究用途で公開されているITAコーパスと呼ばれる学習に適した文章群が公開されています。

内容を見てみるとわかるんだけど、普通に話すだけじゃ中々出てこないようなアクセントの文章が結構含まれています。
「015:ホルロ・アラ・ティタルッフォという特別なお料理も出ました。」
「136:マリー・ロジェはパヴェサンタンの家を出た。」
「190:名をツァウォツキイといった。」
かっみかみですわ。
学習で使えるデータを配布してくださっているプロジェクト
つくよみちゃん
東北ずん子プロジェクト
他にもITAコーパスのリポジトリに例が掲載されています。

試しに東北ずん子プロジェクトから四国めたんさんのITAコーパス読み上げ音源をお借りして学習してみたものと、VOICEVOXの四国めたんさんを比較してみました。
公式チュートリアルでも書いてありますが、これらの学習した音声モデルをマージして新たなモデルを作ることも出来るので、自分のキモい声しか素材がないという方も安心(?)できますね!
3.API経由でプログラムから呼び出す方法
VOICEVOX以外の3つもAPIを使って外部から呼び出すことができるということで、サンプルプログラムを書いて動かしてみます。
サーバーの起動
Style-BERT-VITS2の展開先フォルダから「Server.bat」を起動します。
起動後に「http://127.0.0.1:5000/docs」にブラウザでアクセスすると
APIのドキュメントが表示されます。
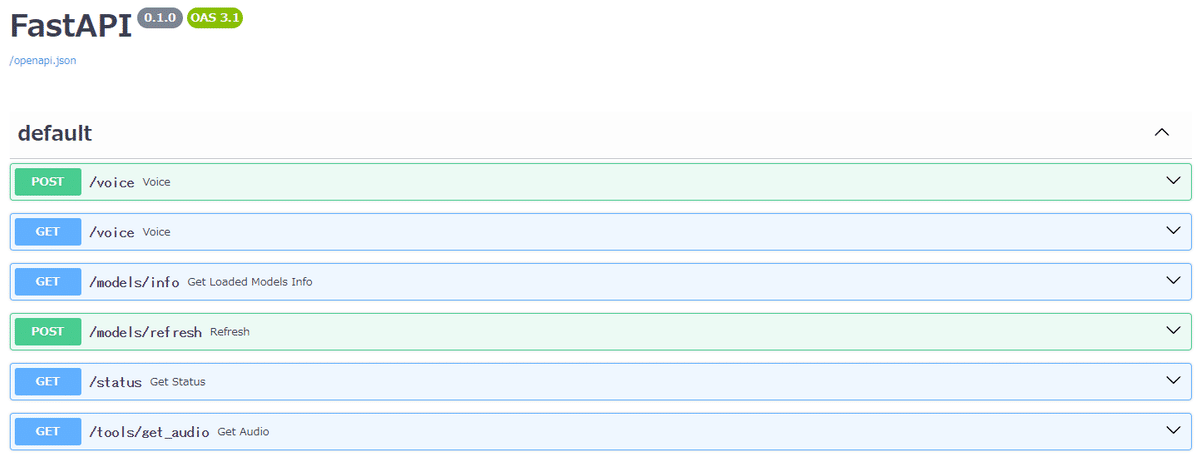
このAPIドキュメントなんですが、このページ上でAPIを実行することも出来て、例えばモデル情報を表示する[GET] /models/infoを見てみると右側に「Try it out」(試してみる)ボタンが表示されています。

ボタンを押すと、下の方にパラメータの入力欄と「Execute」ボタンが出てくるので押してみます。
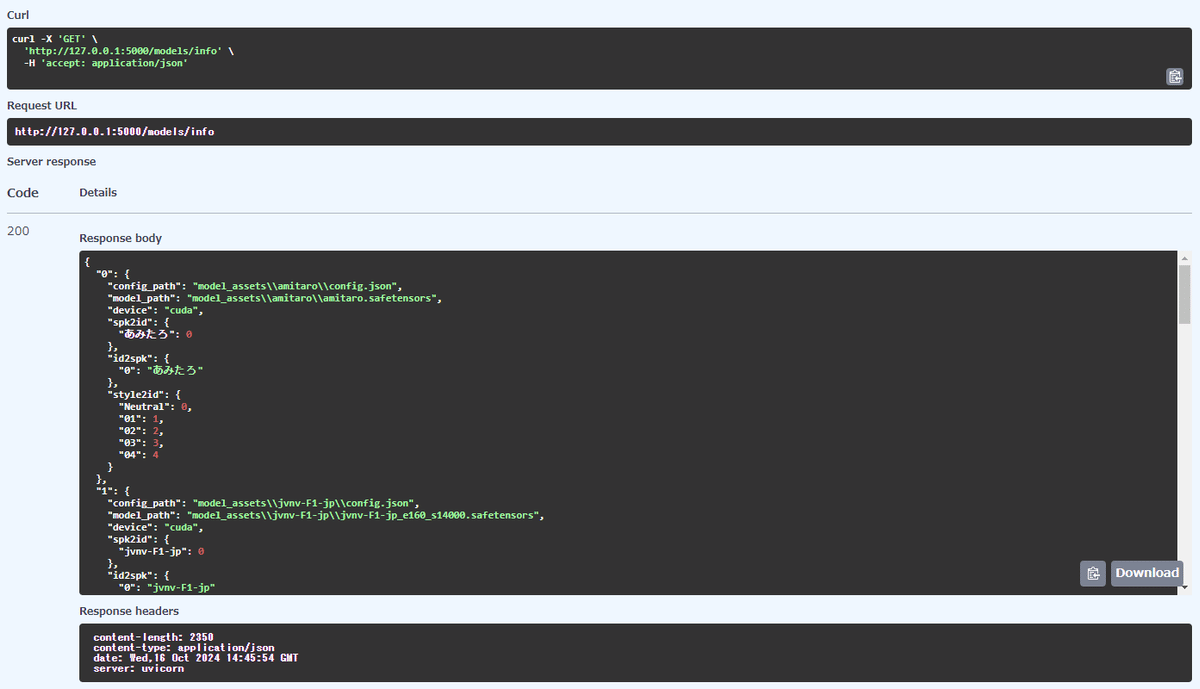
APIを叩いた結果(現在のモデル情報)が返ってきました。なにこれ便利。
APIを叩くコードの作成
このAPIのリファレンスをCursorのComposerさんに読み込ませて、
AIにサンプルコードを生成してもらいます。
出来上がったコードがこちら
import requests
import wave
import pyaudio
# APIのエンドポイント
API_URL = "http://127.0.0.1:5000/voice"
# パラメータの設定
params = {
"text": "ぼくはずんだもんじゃないのだ!",
"id": 0, # スピーカーID(適切な値に変更してください)
"format": "wav",
"language": "JP",
"length": 1.0,
"noise": 0.667,
"noisew": 0.8,
"sdp_ratio": 0.2,
"seed": -1
}
# APIリクエストの送信
response = requests.get(API_URL, params=params)
if response.status_code == 200:
# 音声データの取得
audio_data = response.content
# WAVファイルとして保存
with wave.open("output.wav", "wb") as wav_file:
wav_file.setnchannels(1)
wav_file.setsampwidth(2)
wav_file.setframerate(24000)
wav_file.writeframes(audio_data)
# 音声の再生
p = pyaudio.PyAudio()
stream = p.open(format=p.get_format_from_width(2),
channels=1,
rate=44100,
output=True)
stream.write(audio_data)
stream.stop_stream()
stream.close()
p.terminate()
print("音声の再生が完了しました。")
else:
print(f"エラーが発生しました。ステータスコード: {response.status_code}")
print(response.text)
コードを実行してみます。
py .\test_bert_vits2.py実行すると「ぼくはずんだもんじゃないのだ!」の音声が再生されて、
output.wav形式でも保存されます。ちゃんと喋れているのが判りますね!

4.おわりに
最近、自作していたゲーム実況の配信サポート用AIとして作っていたプログラムを大幅にアップデートして、音声だけでやり取りできるように改修したんですが、やはり声にもこだわりたいということで今回はStyle-BERT-VITS2の環境構築と学習テストをやってみました。
近いうちに幾つかの音声モデルをマージしてKhaulaちゃんにあててあげられるように頑張りたいと思います!

本家Bert-VITS2をこんなに分かりやすくしてくれたlitagin02さん
紹介記事を展開してくれたyukiさんに感謝を込めて!
この記事が気に入ったらサポートをしてみませんか?