ランダムファイルからISAMへ - ファイルあれこれ

ファイルというと大体において、中身が文字などで長さが自由なテキストファイルと、バイト単位で用途が決まっているようなデータファイルに分類されます。これに限らずファイルの種類はいろいろな分類がありますが、結局のところディスクとメモリのやり取りはディスクのセクタ単位でしかできないので、どのように「扱う」かに違いがあるだけです。
テキストファイルを書き込むには、先頭から文字列を追加していくことが出来て、それに従いファイルの長さも自動的に長くなります。これを読むときや、さらに書き込んでいくのに、その位置をバイト単位で(先頭から、または相対的に)指定することができますが、他に何らかの構造はもっていません。C言語で例を上げるとfopen/fclodeで扱うようなファイルです。
これに対してデータファイルは、メモリの中をそのままディスクとやり取りするような使い方で、配列の中身をそのまま仕舞ったり、持ってきたりするようなことをします。もちろんすべてのデータをメモリに持ってくる必要はなくて、何番目のデータだけ読み込み、変更後に持ってきた場所に書き込むようなことをするので、何バイトごとのデータのうち、何番目を読み書きするといった構造を持っている使い方が普通です。こちらはC言語だとopen/closeを使うようなファイルが相当します。
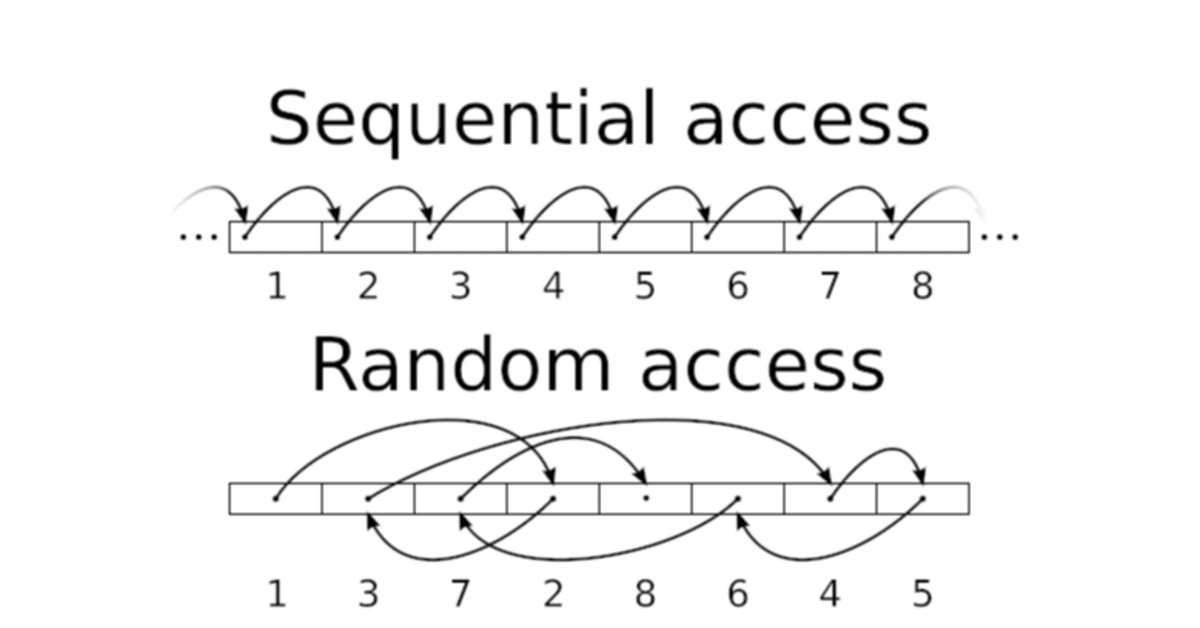
ランダムアクセス
このあたりはAppleDOSの頃から変わっていなくて、ファイルを開く時に何も指定しなければテキストファイルとして扱いますが、OPENの際にLオプションを付ければ、そのバイト数を単位として、RオプションをつけたREAD/WRITEによって、何番目かを指定して読み書きができるようになっていました。”OPEN F,L16”の後に”READ F,R2”とすれば単に先頭から32バイト目から読むだけですが、これで逐一、読み書きの位置をPOSITIONで指定しなくて良いわけです。
シーケンシャルかランダムか
これがいわゆるDISK BASICになった時には、もう少し進化していて、読み書きする変数が固定長の文字列変数になっているのですが、このような使い方をするファイルのことを「ランダムファイル」と呼ぶようになりました。
元々ファイルというのは、こちらの使い方のほうが一般的でFORTRANのFORMAT文を見ても、バイト単位でどのように解釈するデータがいくつ並んでいるのかを指定して読み書きするのが一般的です。ポイントは型と長さをきちんと決めてあることで、何番目のデータなのかを指定することで、中身を確認しなくてもファイル上の位置が計算できるので、途中を読み書きしないで済むことが大事なわけです。まあ、データを表示したり印刷したりすることを考えても長さが決まっているのは大前提です。
そういう訳で、今でも少しは長さが決まっていることもありますが、昔はどんなデータであってもいちいち長さは決められていて、京都市の住所をしまうことができなくてという話がよく聞かれました。ここで充分な余裕が取れれば良いのですが、大部分のデータはそんなに長くならないので、あまり余裕を取るとファイルは「スカスカ」なのにディスクは一杯になってしまうので、涙を飲んでデータを切り捨てるか、天才プログラマが例外的な処理を書いて、他の隙間に押し込んだりして逃げ切ったりするわけですね。
データベースという考え方が出てくると、このひとつのデータの単位を「レコード」と呼ぶようになり、レコードの中のそれぞれの値を「フィールド」と呼ぶようにもなりました。これで7番目のレコードの3番めのフィールドにある値を更新する、などという処理を説明することがやりやすくなったわけです。
8ビットの時代はディスクも高々100K~300Kバイトしか入らないので、フィールドの長さとして、ほとんどが短いのに稀に長くなるようなデータを、単純に最大の長さでランダムファイルを作るのは、厳しいものがありました。そこで気がつくわけです。長さが大幅に変わるフィールドを別のファイルに追い出して、そのファイルの中で、どの位置から始まるのかの値を元のファイルのフィールドに記録しておくのです。これでランダムファイルに無駄な隙間はできません。もちろん、その別のファイルの中身をメンテンスするのが面倒といえば面倒なのですが、ファイル容量を節約しなければディスクに収まらないので背に腹は代えられません。
この別のファイルの方にも参照しているランダムファイルのレコード番号をつけることで、使われなくなったフィールドのデータを削除したりすることもできるようになりました。こうしてデータベース的プログラミングの道が始まったのです。当時は便利なデータベースソフトなんて、まだパソコンにはなかったので、こうしてひとつずつ作っていく必要がありました。
データベースとしてファイルを使うようになると、いちいちファイル全体を舐める処理はとても時間がかかるので、先の「別のファイル」テクニックの延長で、一部のフィールドを取り出して、ここにランダムファイルの何番目のレコードにあるのかを記録することで、舐めるのを一部のフィールドだけにできることがわかります。これがいわゆる「インデックスファイル」と呼ばれるファイルにあたるということは、作ってみてから知りました。こういう方法は一般的なもので、やり方が整理されてISAMと呼ばれる形式が普通に使われるようになっていきました。
Indexed Sequential Access Method (ISAM)
この頃にはデータベースソフトというのも登場しつつあったのですが、何かのソフトに組み込まれるような場合には、別に独立したソフトを使うのは難しく、MS-BASICやVBでゴリゴリとデータベースを書く羽目になることが、かなり長く続きました。
パソコンで扱うデータはどんどん量も多くなり、構造も複雑になっていき、リレーショナル・データベースというものがパソコンの世界にもやってきて、SQLという問い合わせ言語も使われるようになりました。さんざん自力でデータベースを書いていたので、言いたいことは良くわかったので、スムーズに覚えることは出来たのですが、データベースの処理は、他のソフトと脳みその使う場所が違うようで、何だか楽しくはありません。好きではないのですが適性はあったようで、その手のお仕事も随分としましたが、一番向いていたのは、プログラムの設定を管理するデータベース(レジストリみたいなもの)だったような気がします。
リレーショナル・データベースの話はまだいろいろあるので、そちらはまたの機会に。
ヘッダ画像は以下から使わせていただきました。
https://commons.wikimedia.org/wiki/File:Random_vs_sequential_access.svg
この記事が気に入ったらサポートをしてみませんか?