
データ分析を学び始めて3ヶ月でkaggleのコンペに挑戦してみた。

はじめに
こんにちは。最近pythonを用いたデータ分析を学んでいるだはーです。
学生時代に集団の塾講師でのアルバイトをする中で、「データをもっと活用すればもっとうまくいくんじゃね?」と思うことが増え、学んでみようと思いました。
今回はその内容を生かして、kaggleのtitnicコンペに挑戦したいと思います。
データの読み込み
まずは
train_df = pd.read_csv('/kaggle/input/titanic/train.csv')
test_df = pd.read_csv('/kaggle/input/titanic/test.csv')pd.read_csvで読み込みたいデータ名をパス指定します。今回はkaggleに事前に訓練データとテストデータが存在するため、train.csvをtrain_df、test.csvをtest_dfとして読み込みます。
また、pandasは事前にインポートしています。
データの確認(形状、型、先頭5つの可視化)
読み込んだデータがどのようなデータなのか、概要を簡単に確認します。
データの形状
print(f'Train_df_shape : {train_df.shape}\n')train_df(訓練データ)の形状をshapeを用いて表示します。結果は、Train_df_shape : (891, 12)と表示されたので、891行と12列で構成されたデータベースであることがわかります。もっと具体的な中身を見ていきましょう。
データの型
print(f'{train_df.dtypes} \n')train_df(訓練データ)の各columnのデータ型を、dtypesを用いて表示します。

上記のとおり、object型とint64、float64の数値データが混ざっていることがわかる。さらに中身を見ていきます。
データベースの先頭5つを表示
display(train_df.head())train_df(訓練データ)の中身を、先頭の5つのみheadを用いて表示します。

先頭5行と12列のカラムが確認できました。kaggleではデータセットがほぼ英語になるため、列の意味が曖昧な場合は確認する必要があります。
ちなみに今回の場合は、「Survived:1が生存、0がそうでない」「Pclass:チケットのクラス、1st=1、2nd=2、3rd=3」「Name:名前」「Sex:男性(male)、女性(female)」「Age:年齢」「SibSp:兄弟、配偶者の数」「Parch:両親、子どもの数」「Ticket:チケットの番号」「Fare:乗船料金」「Cabin:部屋番号」「Embarked:乗船した港、S=Southampton、C=Cherbourg、Q=Queenstown」となります。
また、同様の手順でテストデータの確認も行います。
基礎統計量の確認
続いて、データの基礎統計量を見ていきます。データのおおまかな形をつかむための大事な作業になります。
まずは、訓練データの数値データの統計量をみていきます。
# 数値データの統計量を表示
display(train_df.describe())train _dfの統計量をdescribeを使用して確認します。

上記のような結果となりました。ここから訓練データの数値データには、Ageにおいて欠損値があることが確認できます。
数値データにおける基礎統計量では、count(データ数)、mean(平均値)、std(標準偏差)、min(最小値)、max(最大値)を確認し、欠損値があるカラムはないか、外れ値が含まれているカラムはどれか、データの偏りなどをみていきます。
続いて、訓練データのカテゴリカルデータの統計量をみていきます。
# カテゴリカルデータの統計量を表示
display(train_df.describe(exclude='number'))数値データのときと同じように、describeを使用し統計量をみていきます。exclude='number'の記述と記述することで、数値以外のカラムを指定することができます。

上記のような結果となりました。ここから訓練データにおけるカテゴリカルデータには、SexとEmbarkedにおいて欠損値があることがわかります。
また、今回の統計量の確認から下記のような仮説が考えられます。
・0か1で表されるSurvivedの平均が0.5より小さい→今回の目的変数は偏りがあるので可視化を行い、確認しておく必要がある。
・AgeやFareの最大値が平均値や中央値と比べて大きい→外れ値が含まれている可能性がある。
・SibSpやParchの半分以上は0である→同乗していた家族の人数には偏りがありそう。
また、テストデータに関しても同様の手順で基礎統計量の確認を行います。その際に意識しておくこととして、訓練データとテストデータとの統計量の値が極端に乖離していないことをみておきます。
基礎統計量での仮説をもとにデータの可視化
基礎統計量で立てた仮説を、データを可視化することで確認していきます。
まずは、目的変数であるSurvivedのデータの偏りをみていきたいと思います。
import seaborn as sns
sns.countplot(x=‘Survived’, data=train_df)データ可視化ライブラリであるseabornをインポートし、ヒストグラムで表示します。
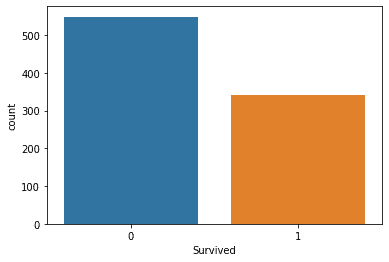
結果は上記のようになりました。1よりも0の方が数が多いため、生存者数よりも死亡者数の方が多いことがわかります。
次に、訓練データとテストデータの双方におけるAgeとFareの外れ値の確認を行います。そのために、双方のデータの結合を行います。
# All
# 訓練データとテストデータを結合しall_dfを作成
all_df = pd.concat([train_df,test_df],axis=0).reset_index(drop=True)
# 訓練データとテストデータを判定するためのカラムを作成
all_df['Test_Flag'] = 0
all_df.loc[train_df.shape[0]: , 'Test_Flag'] = 1pandasのconcatでtrain_df(訓練データ)とtest_df(テストデータ)の結合を行います。
正しく結合ができているかどうか、all_dfの統計量を確認してみます。
# データ全体における、数値データの統計量を表示
display(
all_df.describe()
)
# データ全体における、カテゴリカルデータの統計量を表示
display(
all_df.describe(exclude='number')
)

正しく結合できているようなので、AgeとFareのデータの可視化を行います。
# Ageについて可視化
fig = sns.FacetGrid(all_df, col='Test_Flag', hue='Test_Flag', height=4)
fig.map(sns.histplot, 'Age', bins=30, kde=False)
#Fareについて可視化
fig = sns.FacetGrid(all_df, col='Test_Flag', hue='Test_Flag', height=4)
fig.map(sns.histplot, 'Fare', bins=30, kde=False)
この結果、train_df(訓練データ)とtest_df(テストデータ)の双方において、Fare(料金)に外れ値があることが確認できた。
データの可視化ー相関編
続いて、目的変数の予測のヒントになる説明変数を見つけるために、各カラム同士の相関係数をheatmapで表示します。
sns.heatmap(
train_df[['Survived','Age','SibSp','Parch','Fare']].corr(),
vmax=1,vmin=-1,annot=True
)
上記の通り、SibSp(兄弟、配偶者の数)とParch(両親、子どもの数)に正の弱い相関(0.41)がみられます。また、SibSp(兄弟、配偶者の数)とAge(年齢)に負の弱い相関(-0.31)がみられます。
ちなみに、相関係数の大きさの大小を正確に判断する方法は存在せず、長年の感覚で判断することが多いようです。今回の場合は、相対的にみて大小の判断を行いました。
カテゴリカル変数と目的変数(Survived)の関係の可視化
数値データは相関関係をみることで目的変数との関係性を確認することができますが、カテゴリカル変数は相関関係を使用することができません。
そのため、ヒストグラムを用いてカテゴリカル変数と目的変数との関係を可視化していきます。
# Sexについて可視化
sns.countplot(x='Sex', hue='Survived', data=train_df)
plt.show()
# Pclassについて可視化
sns.countplot(x='Pclass', hue='Survived', data=train_df)
plt.show()
# Embarkedについて可視化
sns.countplot(x='Embarked', hue='Survived', data=train_df)
plt.show()
# Ageについて可視化
fig = sns.FacetGrid(train_df, col='Survived', hue='Survived', height=4)
fig.map(sns.histplot, 'Age', bins=30, kde=False)
#Fareについて可視化
fig = sns.FacetGrid(train_df, col='Survived', hue='Survived', height=4)
fig.map(sns.histplot, 'Fare', bins=25, kde=False)
# SibSpについて可視化
sns.countplot(x='SibSp', hue='Survived', data=train_df)
plt.show()
# Parchについて可視化
sns.countplot(x='Parch', hue='Survived', data=train_df)
plt.show()
性別によって生存率に差があることがわかる

チケットのクラスが大きくなるにつれて生存者が小さくなっていることがわかる

乗船した港によって生存率に差がある
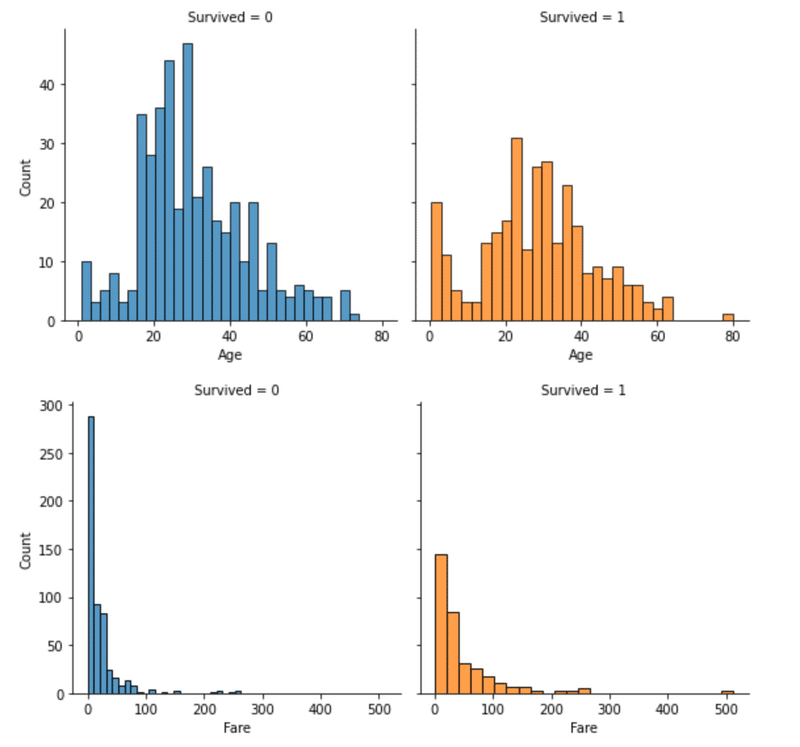
下図が死亡者数、生存者数におけるFareの分布の可視化


これらの可視化からわかることをまとめます。
性別によって差がある
チケットのクラスが大きくなるにつれて、生存率が小さくなっている
乗船した港によって生存率に差がある
若い年齢(特に幼児)の人の生存率が高く、20〜30代の生存率が低くなっている
運賃が低い乗客ほど、生存率が低くなっている
兄弟・配偶者の数や両親・子どもの数は0人よりも複数人いる方が生存率が高くなっている
これまでの分析の整理
これまでの分析で得られた知見をまとめてみます。
数値データであるAge(年齢)、SibSp(兄弟・配偶者の数)、Parch(両親・子どもの数)、Fare(料金)と、目的変数であるSurvived(生存者)の値の間に、相関などの関係性が確認できた。
Sex(性別)やEmbarked(乗船した港)、Pclass(チケットのクラス)などのカテゴリカル変数の間にも予測に役立ちそうな関係性を確認できた。
AgeやFare、Cabin(部屋番号)、Embarkedには欠損値が、Fareには外れ値が存在する。
これらの知見を元に特徴量を作成し、予測モデルを作成していきます。
今回は、以下のような方針で特徴量作成を行います。
Sibsp、Parchは前処理を施さず、そのまま特徴量に採用する。
Age、Embarked、Fareの欠損値を補完する。Cabinは欠損値が多いので、今回は特徴量に採用しない(Cabin(部屋番号)は予測に役立ちそうにもないと判断)。
Fareの外れ値に対する対策として、4つの区間に分類し数値データをカテゴリカル変数に変換する。
カテゴリカル変数はSex、Embarked、Pclassを採用し、それぞれに対してOne-Hot Encodingを行う。
それぞれの処理を順に行います。
欠損値の補完
欠損値は、平均値や中央値で補完するのが一般的ですが、その他にも、欠損の有無をカテゴリカル変数化する、外れ値を代入し欠損を表すなどの対処方法もある。
これは、「欠損にも何かしらの情報が含まれている」という考えが背景にあります。
Age、Embarked、Fareの欠損値を以下のコードで補完を行います。
# Ageの欠損を中央値で補完
all_df['Age'] = all_df['Age'].fillna( all_df['Age'].median())
# Fareの欠損を中央値で補完
all_df['Fare'] = all_df['Fare'].fillna( all_df['Fare'].median())
# Embarkedの欠損を「'NaN'」で補完
all_df['Embarked'] = all_df['Embarked'].fillna('NaN')fillnaを使用し、欠損値に指定の値を代入します。
カテゴリカル変数化
続いて、特徴量の外れ値に対する対策を行います。
特徴量に用いるFareの外れ値が存在するため、4つの区間に分類し数値データをカテゴリカル変数に変換する処理を行います。
# Fareを4つの区間に分類し、カテゴリカル変数に変換
all_df['FareBand'] = pd.qcut(all_df['Fare'], 4)カテゴリカル変数化の手法として、qcutを用いてビニング処理(ビン分割)を行います。ビニング処理とは連続値を任意の境界値で区切りカテゴリ分けして離散値に変換する処理のことです。
今回は4つの区分に分けています。
カテゴリカル変数のOne-Hot Encording
One-Hot Encordingとは、各カテゴリ変数に対して該当するカテゴリかどうかを0、1で表現したベクトルに変換する処理です。カテゴリカル変数であるSex、Embarked、Pclassにこの処理を実行します。
この手法は、カテゴリーの1つ1つに対し特徴量を作成するため、含まれるカテゴリが多いと特徴量が膨大になってしまいます。これにより、モデルがうまく学習できなくなる場合があるため、使用時は注意が必要です。
# Sex、PclassをOne-Hot_Encodingで変換
all_df = pd.get_dummies(all_df, columns= ["Sex", "Pclass"])
# EmbarkedをOne-Hot Encodingで変換
all_df = pd.get_dummies(all_df, columns=['AgeBand','FareBand','Embarked'])変換された変数をダミー変数という呼び方をするため、One-Hot Encordingはget_dummiesにて実行します。
検証データの作成
特徴量の作成が完了したので、次は予測モデルに学習させるための訓練データと検証データを作成します。
検証データを作成し、モデルを評価する手法はいくつかあるのですが、今回はホールドアウト法を用います。ホールドアウト法のイメージ図は下記のようなものです。

元々の訓練データを、訓練データと検証データに分割し、訓練データで予測モデルを作成し、その性能を検証データで確認します。以下のコードで実施します。
from sklearn.model_selection import train_test_split
# 前処理を施したall_dfを訓練データとテストデータに分割
train = all_df[all_df['Test_Flag']==0]
test = all_df[all_df['Test_Flag']==1].reset_index(drop=True)
# 訓練データのSurvivedをtargetにする
target = train['Survived']
# 今回学習に用いないカラムを削除
drop_col = [
'PassengerId','Age',
'Ticket', 'Fare','Cabin',
'Test_Flag','Name','Survived'
]
train = train.drop(drop_col, axis=1)
test = test.drop(drop_col, axis=1)
# 訓練データの一部を分割し検証データを作成
# 注意 :
# shuffleをTrueにするとランダムに分割されます。
# この時、random_stateを定義していないとモデルの再現性が取れなくなるので、設定するよう心がけてください。
# test_size=0.2とすることで訓練データの2割を検証データにしている
X_train ,X_val ,y_train ,y_val = train_test_split(
train, target,
test_size=0.2, shuffle=False,random_state=0
)ホールドアウト法はscikit-learnのtrain_test_splitを用いて行います。
ここまでで前処理を施した、all_dfを訓練データ、テストデータに分割しなおし、今回の目的変数であるSurvivedをtargetと指定します。なお、学習に用いないカラムは事前に訓練データ、テストデータから削除します。
この状態でtrain_test_splitを利用し、訓練データの2割(test_size=0.2)を検証データに設定します。また、random_stateに任意のint型の値を指定することで(例えば0など)分割結果が固定されます。この指定を行わないとモデルの再現性が取れなくなるので、設定するようにします(random_stateの初期値はNone)。
予測モデルの構築
学習に用いるデータの準備ができたので、予測モデルを構築していきます。ここでどのようなモデルを採用するかですが、今回はSurvivedの生存したか、していないかを判断する二値分類問題なので、ロジスティック回帰を用います。
from sklearn.linear_model import LogisticRegression
# モデルを定義し学習
model = LogisticRegression()
model.fit(X_train, y_train)LogisticRegressionをインポートし、訓練データをfitを用いて学習させます。
予測モデルの評価
下記のコードで正答率の算出を行います。
# 訓練データに対しての予測を行い、正答率を算出
y_pred = model.predict(X_train)
print(accuracy_score(y_train, y_pred))結果は0.7991573033707865でした。
この値が大きいほど、精度の高い予測モデルができていることを意味します。
テストデータの予測の評価
# 評価用データを予測
y_pred_val = model.predict(X_val)
# 予測結果を正答率で評価
print(accuracy_score(y_val, y_pred_val))結果は0.8268156424581006でした。
正答率だけだとなんか不安なので、予測結果を実際に確認してみようと思います。
print(y_pred_val)
確認できました。
まとめ
今回の予測モデルの作成では、それぞれの手順における基本的な内容を実施したものでした。
そのため、まだまだ予測モデルに組み込むことができていない特徴量もあります。
今後も予測精度がさらに高くなるよう、データの前処理や特徴量の検討、データの予測モデルの選定を工夫してみようと思います。
この記事が気に入ったらサポートをしてみませんか?