「信頼できないデータ」をいかに可視化するか

新型コロナウイルス感染症(COVID-19)のデータをビジュアライズするにあたっては、信頼できないデータの扱いに頭を悩まされている。
ここで信頼できないデータとは改竄とか隠蔽という意味ではなく、定義が頻繁に変わったり、事象の発生と公表日にタイムラグがあったり、時系列での継続性が担保できないデータを指す。
そもそも厚生労働省から発表されるCOVID-19のデータは、基本的に時系列ではなくその日時点で判明している累計数字だけだ。
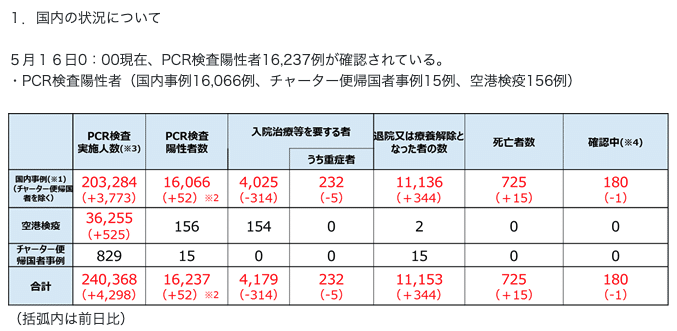
(厚生労働省「新型コロナウイルス感染症の現在の状況と厚生労働省の対応について(令和2年5月16日版)」より)
過去分の訂正は行われず、新たに判明した追加や訂正があると最新の数字だけが変更される(いちおう注記にはその旨が書かれるが、結局いつ・どのくらい訂正されたかが書いていないので過去データの修正ができない)。したがって、時系列で見るとマイナスになるはずのない項目がマイナスになったりする。
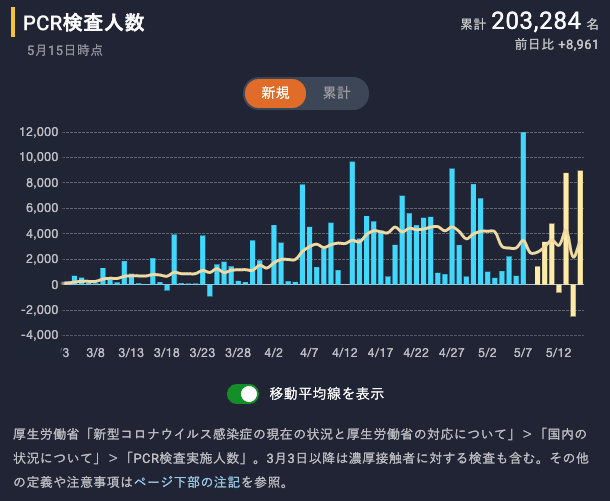
これはPCR検査人数の推移だが、もちろん検査人数はマイナスになりえない。日々行われているはずだ。「その日の締め時点で最も正しいデータ」を積み上げていくとこのようになってしまう。検査の時点も当然ながら日付とは関連しない(検査を行う → 結果判明 → 保健所など検査施設から自治体に報告 → 自治体から厚生労働省に報告、とタイムラグがあるため、数日の遅れがあるだろう)。
検査陽性者の情報も同じで、日付は感染した日でも発症した日でも検査を受けた日でも陽性反応が出た日でもなく、厚生労働省まで報告が届いて公表された日となる。
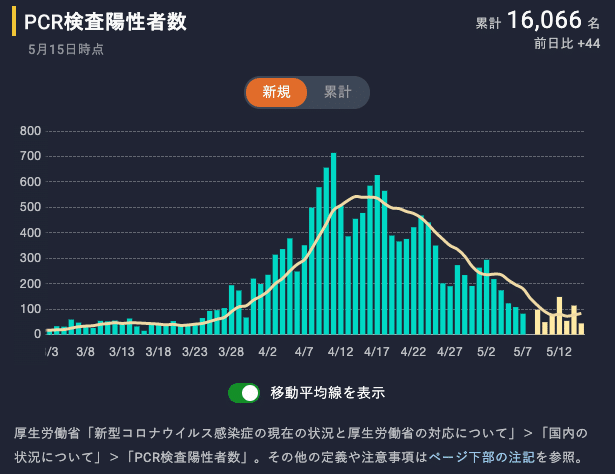
この他にも「都道府県からの過去分訂正が最新日に積み上げられる」「PCR検査実施人数に濃厚接触者調査が加わる」「『突合作業中』というよくわからないステータスの数字が項目に加わる」「発表のベースが感染症法に基づく報告からプレスリリースの転記ベースに切り替わる」など、色々なイベントがあってそれはもうエキサイティングな毎日である。
このようなデータにどう対応するか。僕が意識していることはいくつかある。
誤解なく伝えられる自信がないデータは可視化しない
まずはこれ。定義が判然としなかったり、データそのものの信頼性に疑義が呈されている時は不用意に可視化しない。新聞や雑誌記者の「裏の取れない発言は記事にしない」と似ているかもしれない。
たとえば陽性率。日別の新規陽性者数が減少するにつれて話題にのぼるようになった指標だが、そもそも分子と分母に何を取るかもコンセンサスが取れているとはいいがたい。たとえば東京都の発表では陽性率の分母が「検査数」になったり「検査人数」になったりする。また、厚生労働省の発表には累計の検査陽性者数/検査実施人数で計算される指標が掲載されているが「陽性者数の検査人数に対する比率」と慎重な言い回しがされている。
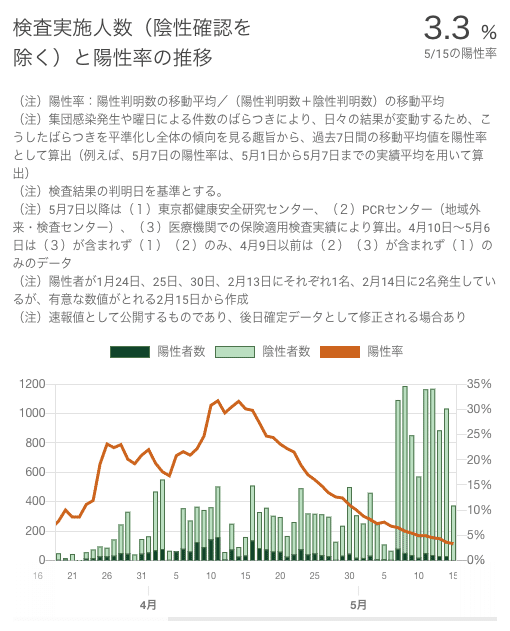
(東京都の新型コロナウイルス感染症対策サイトより)
加えて、上で述べたように日別に区切ると検査陽性者数と検査実施人数/件数はリンクしない。検査をした日と陽性が判明した日が異なる可能性があるためだ。中には「陽性率を計算したよ!」と新規陽性者数と新規PCR検査人数を無邪気に割り算している人もいて「お、おう」となる。
似た例には人口あたりの数字がある。都道府県のデータを追加したあたりから「人口あたりの陽性者数や検査人数を掲載してほしい」という要望が来たが、今のところ(5月中旬)人口あたりの数字は掲載していない。
なぜか。COVID-19の感染拡大にはクラスターの影響が大きいためだ。大規模なクラスターが発生すると、一挙に数十人の陽性者が出ることがある。現在の東京や大阪といった大都市圏では影響が少ないかもしれないが、特に陽性者数が少ない感染初期のフェーズにおいて、人口が少ない県では人口あたりの数字を大きく増加させる可能性がある。そうすると「◯◯県は全国で最も感染率が高い!」というスティグマが拡散されることになりかねない。
経路不明の市中感染がほとんどになったり、感染者数がさらに増えたら掲載を検討しようと考えていたが、幸いなことに新規陽性者などの数字は減少傾向にあるので、状況が大きく変わらない限りは実装の必要はないかな、とは思っている。データもGitHubで公開しているので、興味がある人は自分で好きなように計算してみるのがよいと思う。
注記だけではなくビジュアルで注意喚起する
次は、どうしても継続性のないデータや注意が必要なデータを載せる必要に迫られたときにどうするか。文章で説明することはもちろんだが、出来る限りビジュアルでもわかるようにしている。たとえば下のグラフでは2回の定義変更を行っているのが感覚的にわかると思う。
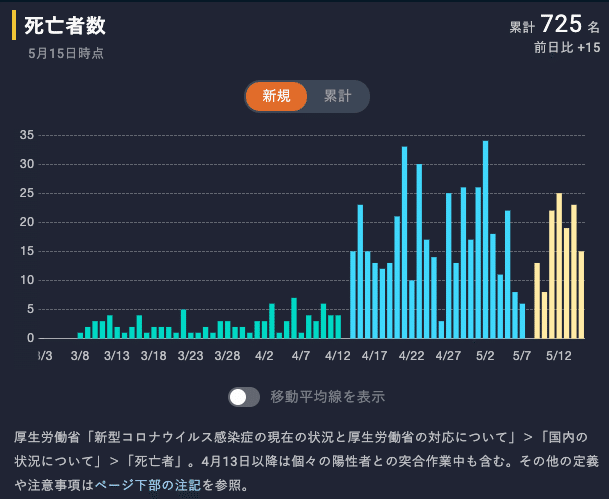
4月13日からは「突合作業中」とされる未確認の数字が参考情報として加わり、さらに5月8日からはデータソースが変更された。したがってグラフの色を変え、継続性が担保できない期間は差分を計算せず新規の数を「0」としている。
もちろん「注記で書いたから問題ない」というスタンスで普通にグラフを描画してもよいかもしれないが、残念なことにグラフがバズって拡散されるときに注記までシェアしてくれる人は少ない。
最初はグラフをスクリーンショットで拡散するとき一緒に注記も入れてほしいと思って注記を省略せず全文グラフ直下に入れていたけど、厚生労働省の基準変更があるたびに注記が長くなっていったのであきらめた。
余談だけど「PCR検査人数」を「件数」に誤読する人もびっくりするくらい多かった。本質的に意味があるのは検査件数よりも人数だろうと考えて最初は検査人数だけ掲載し、注記にもしつこいくらい「これは『件数』ではなく1人に複数回検査しても1人とカウント…」と書いていたけど、あまりにも「件数」と読む人が多かったので後に検査件数も追加した。
数字は一人歩きする
とはいえ、現在進行形の事象を統計化するのはすさまじく難易度の高いタスクだし、基準変更や訂正があるのは仕方ない。僕もTwitterでは基準変更があるたびにぶつくさ言ってるけど、「統計はこうあるべきだ」みたいな正論をもって厚生労働省をぶったたく気はない。
ただ厚生労働省の報道発表ページを開くたびに「今日からガラッと構成を変えてきてデータベースから何からすべてやり直しになったらどうしよう」とドキドキしている(実際に何度かあった)。
そんなわけでデータ収集の自動化なんて夢のまた夢である。おまけによく知らない人からは「荻原くんデータ更新しかしてないから最近ヒマでしょ」とか言われたりする。踏んだり蹴ったりである。
数字は一人歩きする。その事実は変えられない。であれば、それを前提としてどのようにデータを伝えられるかを考える必要がある。

一人歩きする数字のイラスト。数字が一人歩きしてるときに使ってください。
データビジュアライゼーションは、決して「そこにあるデータを何でもかんでも機械的に可視化する」ことではない。データビジュアライゼーション作品を公開する際は、せめて「そのデータを公開したらどうなるか」という想像力は持っていたい。
この記事が気に入ったらサポートをしてみませんか?