データエンジニアリングの未来像を考える - Google Cloud Next '23 参加レポート(セッション紹介〜Recapディスカッション編)

風音屋(@Kazaneya_PR)のデータエンジニア 濱田(@hrkhjp) 、森岡、妹尾です。前回に引き続き、Google Cloud Next '23 の参加レポートをお送りします。
サンフランシスコの雰囲気などについては、前回の「Google Cloud Next '23 参加レポート(渡航準備〜現地報告編)」でご紹介しています。ご興味のある方はぜひこちらもご覧ください!
本記事の前半では「セッション編」として、各自が参加したセッションから一部をピックアップしてご紹介します。後半では「Recapディスカッション編」として、Google Cloud Innovators Champion の1人 “ゆずたそ”(@yuzutas0)がプライベート勉強会で話した内容をお届けします。
【セッションピックアップ】
<Day 1>
What's new with BigQuery
[1人目] "What's new with BigQuery"
— 株式会社風音屋 (@Kazaneya_PR) August 30, 2023
BigQueryの新機能に関するセッションでは、Opening Keynoteでも多く取り上げられていたDuet AIの導入やBigQueryStudioなどの新機能が取り上げられ、生産性向上やオープンソースフォーマットの強化など幅広い追加機能が紹介されました。#GoogleCloudNext pic.twitter.com/QqNUKRJ11u
BigQuery Studioを利用すれば、SQLワークスペース内でPythonやSparkなどを使用して分析ができます。BigQueryのコンソール上で実現できる分析方法の選択肢が増え、ノートブック上で分析結果を保存、共有できるのでデータマネジメントの観点でもかなり嬉しいアップデートです。
BigQueryのDuetAI導入により、自然言語によるデータ分析も可能になるようです。BigQuery Studioは現時点でプレビュー段階なようなので、気になる方はぜひサインアップしてみてはいかがでしょうか
Leverage sensitive data intelligence to protect your structured and unstructured data
[2人目] タイトル省略
— 株式会社風音屋 (@Kazaneya_PR) August 30, 2023
Sensitive Data Protection(Cloud DLPを包含するサービス)の解説です。収集したデータプロファイルをDataplexに連携することで、BQにポリシータグを付与できるようになりました。機密データを含む列の検知から保護までの流れを自動化できて便利そうです!#GoogleCloudNext pic.twitter.com/6QzCGKDvzU
Sensitive Data Protectionでは、BigQuery内のデータをスキャンし、リスクのありそうな列を検知することができます。もちろん、データ連携時に気が付いて対処できるのが一番よいですが、見逃してしまったり、定期連携を開始した後にデータの性質が変わってしまったりすることはあると思いますので、後からでも検知できるのは役に立ちそうです。
検知した情報をDataplexに連携することで、クエリ実行時に特定のカラムを動的にマスキングすることができます。誤って個人情報にアクセスしてしまうリスクを減らすことができるので、ぜひ活用していきたいですね。
Optimize your BigQuery data platform for performance and cost
[3人目] "Optimize your BigQuery data platform for performance and cost"
— 株式会社風音屋 (@Kazaneya_PR) August 30, 2023
BQの最適化Tipsの紹介セッションです。clusteringするカラムはINFORMATION_SCHEMAでWHEREやGROUP BYなどで使われているカラムを探せというメッセージが印象的でした。単純かつ明確な指針でよいですね。#GoogleCloudNext pic.twitter.com/Oxz6fEx8ZX
BigQueryの最適化Tipsを紹介しているセッションです。網羅的かつ構造化されているので、チューニングをしたい人は、まず初めにこのセッションの資料を見ると良さそうです。
「clusteringするカラムはINFORMATION_SCHEMAでWHEREやGROUP BYなどで使われているカラムを探せ」など、単純かつ明確な指針を示してくれます。
BigQuery上でのコンピューティングにかかるコストを削減するため、ELTではなくETLを採用し、BigQueryに取り込む前にRDB(たとえばCloud SQL)でデータ変換を行うとよい、というお話がありました。小規模なデータであればBigQueryで処理してもそんなにコストはかからないですし、大規模なデータであればRDBに高いスペックが要求されるので、これについてはあまりメリットはなさそうだなと感じました。
<Day 2>
What's new in data governance
[1人目] "What's new in data governance"
— 株式会社風音屋 (@Kazaneya_PR) August 31, 2023
Dataplexに関するセッションでは、VertexAIのメタデータの自動カタログ化のプレビュー公開や、Data ProfileやData Qualityなどの機能が紹介しました。さらに、Duet AIのDataplex導入が近く予定されていることも発表されました。 #GoogleCloudNext pic.twitter.com/RDxRztHIz1
データの仕様をキャッチアップする上でData ProfileやData Lineageは有用な機能かと思います。BigQuery、 BigQuery Omni、BigLake、Data Fusion、Composerに続いて、Dataprocで実行されるSparkジョブについてもリネージ対象になったことが発表されました。
Duet AIがDataplexに導入されることも発表されました。AIと対話しながらデータを探せるようになるだけでなく、データの利用傾向やメタデータから質問リストを生成してくれるので、「何がわからないのかわからない」状態を打破する強力なツールになりそうです。今後はメタデータの管理がより重要視されるようになっていくのでしょうか。
Share securely with data clean room
[2人目] "Securely share with data clean room"
— 株式会社風音屋 (@Kazaneya_PR) August 31, 2023
data clean roomsプレビューが本日公開。データ提供者はデータとクエリ結果を持ち出せないように設定できます。また、利用状況のモニタリング画面も提供されるようです。一方、データ品質の提供は今後実装予定とのことでした。#GoogleCloudNext pic.twitter.com/4pSBTjsXLv
data clean roomsプレビューが公開されました。データとクエリ結果を持ち出せないように設定できるなど、複数の組織間でデータを共有・利用するための機能です。
data clean roomsに提供しているテーブルの利用状況をモニタリングする機能も実装されており、だれがどのくらい利用しているかがパッと分かるようになるようです。
一方、質疑応答で質問されていましたが、データ品質の提供できるようになるとますます便利になりそうだなと思いました。
What's new in Serverless Spark
[3人目] "What's new in Serverless Spark"
— 株式会社風音屋 (@Kazaneya_PR) August 31, 2023
Serverless Spark (Dataproc) のNotebookやData lineage対応がまもなくGA!
また、こっそりと紹介されていましたが、なんとServerless ComposerがPreviewに!インフラを意識せずにAirflowを使えそう?ということで、期待したいですね! #GoogleCloudNext pic.twitter.com/lBg9WmP1Mo
データガバナンスのセッションでもお話があったようですが、Sparkジョブによるデータ変換についてもリネージの対象になるため、複雑な加工を行うためにSparkを使った場合でも、BigQueryでSQLによる加工を行った場合と同じようにデータの依存関係を追跡できるようになり便利そうです。
これはSparkとはあまり関係ないですが、Serverless Composerがちらっと紹介されていました。他で情報があまり出ていないので詳細は不明ですが、これがCloud Composerのサーバレス版ということであれば、Airflowをサーバレスで動かす、ということになるので結構衝撃的です。今後にぜひ期待したいですね!
<Day 3>
Next-generation data analytics with BigQuery and PaLM
[1人目] "Next-generation data analytics with BigQuery and PaLM"
— 株式会社風音屋 (@Kazaneya_PR) September 1, 2023
PandasやScikit-learnを元にしたBigFramesや、PaLMによるテキスト生成をSQLで実行できる機能が紹介されました。今後ますますBigQueryのみで完結できる処理が増えていきそうなので、非常に楽しみですね!#GoogleCloudNext pic.twitter.com/xavcMPHAfc
BigQuery Studioの登場により、SQLやノートブックなど、様々な方法でのデータアクセスが単一のワークスペースで提供されるとともに、Pandasとscikit-learnを基にしたPythonライブラリBigQuery DataFramesも発表されました。データ分析がBigQueryだけで完結できるシーンがさらに増えるのではないでしょうか。
BigQueryからVertex AIの基盤モデルが利用可能になりました。SQLだけでLLMを使えるということなので、生成AI活用の幅が広がりそうです。Embeddingの機能もプレビューになっているので、類似検索など役に立つ場面は多そうです。
Data monetization through embedded analytics
[2人目] "Data monetization through embedded analytics"
— 株式会社風音屋 (@Kazaneya_PR) September 1, 2023
組み込み分析やデータ自体をマネタイズする方法・事例について紹介していました。若干Lookerをごり押ししている感はあるのですが、様々なユースケースに対応するためにAPIファーストなツールを採用するのは良さそうです。#GoogleCloudNext pic.twitter.com/9s9bqJqao3
組み込み分析やデータ自体をマネタイズする方法・事例について紹介していました。「生データではなく、洞察を売れ」や「データプロダクトには名前をつけよ(ただし、〇〇ダッシュボードや▲▲レポートは使うな)」など具体的なアプローチを提案してくれます。
かなり体系的に説明されていますので、データプロダクトに興味がある方にはおすすめのセッションです。
若干Lookerをごり押ししている感はあるのですが、様々なユースケースに対応するためにAPIファーストなツールを採用するのは良さそうです。
Use Looker to empower cloud financial decisions and FinOps
[3人目] "Use Looker to empower cloud financial decisions and FinOps"
— 株式会社風音屋 (@Kazaneya_PR) September 1, 2023
Cloud Billingのエクスポート機能とLookerでGCPのコスト可視化、削減をした事例が紹介されました。必ずしもLookerを使う必要はないですが、全員がモニタリングしてコストを意識できるしくみ作りは大切ですね #GoogleCloudNext pic.twitter.com/99OLHfkuHH
財務部門と開発部門が協力して、Lookerを使用したコストの可視化、最適化に取り組んだお話を聞きました。現状の可視化、そこから共通の問題意識を生みだし、問題解決に進み出すというステップは、データ活用のお手本の流れだと思います。
本セッションでは、BigQueryのストレージの料金モデルを論理ストレージ(Logical Storage)の課金から物理ストレージ(Physical Storage)の課金へ切り替えたことで大幅にコスト削減できたと発表されており、こういったクラウドサービスのコスト最適化は、データ活用の成功体験を積む上で取り組みやすい課題だと思うので、是非挑戦していきたいですね。
【Recapでのディスカッション by @yuzutas0】
海外カンファレンスに現地参加した人が、帰国後に「Recap」と呼ばれる勉強会を開き、日本の技術コミュニティに情報発信を行うという文化があります。風音屋では、プライベート勉強会で(正確にはクライアント各社との定例ミーティングの時間を使って)同様の情報発信を行いました。
風音屋のRecapでは主に「Google Cloud Next ’23 のセッション解説」と「セッション内容を踏まえたディスカッション」を行いました。本エントリーの後半パートでは、風音屋のRecapでディスカッションした内容を、簡単に紹介できればと思います。
<BIツール:ダッシュボードの自動生成>
データエンジニアリング領域において、DuetAIの登場でインパクトが最も大きいのは、おそらくBIツールだろうと思います。
「10秒でダッシュボードを作る」というのは新しいユーザー体験です。現地参加での温度感としては「デモとは分かっているがそれでも感動した」というのが率直なコメントとなります。
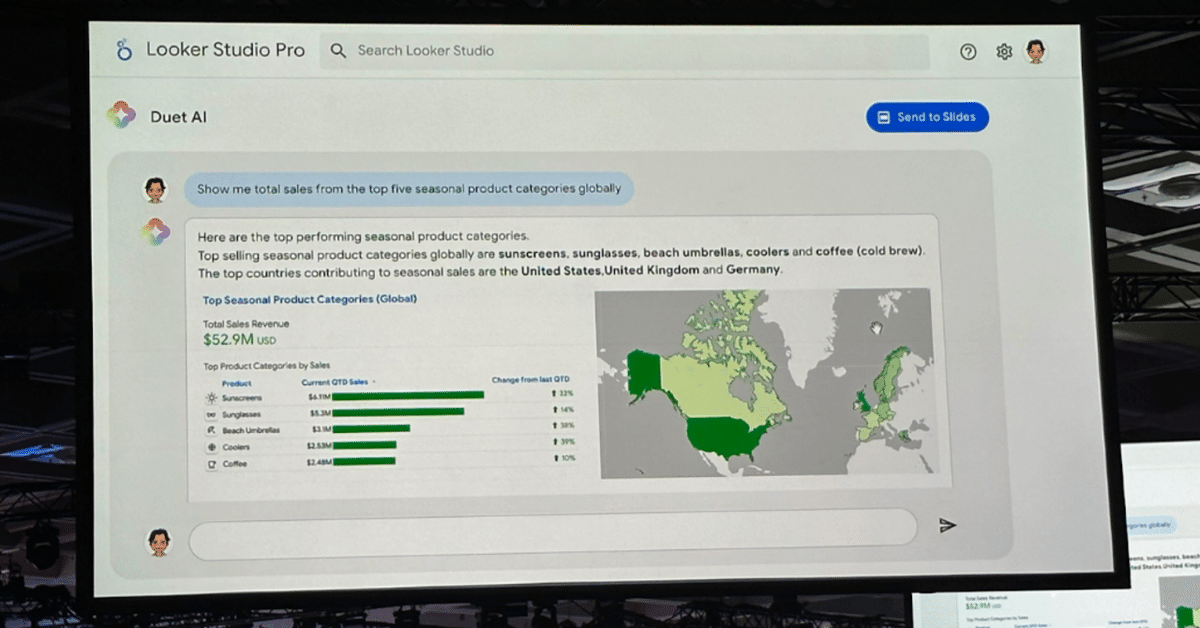
■ Looker Studio / Looker
自然言語で「売上トップの商品カテゴリを教えて」と質問すると、複数のグラフが自動生成されます。キーノートセッションではLookerStudio Proのデモが紹介されました。スコアボード形式で売上総額を、テーブル形式でカテゴリランキングと四半期の上昇率を、マップ形式で国別の売上を表示しています。

個別セッションでは、Lookerを活用した自動生成のデモが紹介されました。念のためですが、LookerとLookerStudio(旧Googleデータポータル)は違う製品ですので、ご注意ください。チャットの中にLookerの画面が組み込まれており、タイル状に複数のグラフを組み合わせて表示しています。

従来から自然言語でグラフを自動生成できるBIツールは存在しました。特に有名なのがAmazon QuickSight Qでしょう。ただ、従来のツールはあくまで1つのグラフを作るだけでした。DuetAIでは複数のグラフを組み合わせたダッシュボードを作成しており、アウトプットのボリュームが大幅に向上しています。
QuickSightに言及したついでに「LookerやLookerStudioに切り替えるべきか」にもお答えしておきましょう。実際にクライアントから受けた質問です。「無理に切り替える必要はないだろう」とお伝えしました。他の主要なBIツールベンダーの動きを見ていると、DuetAIに限らずどのツールもLLMに言及・投資しており、おそらくは似たような進化を遂げていくかと思います。上記デモのような機能・体験が、今後のBIツールのスタンダードになっていくかもしれません。
最後に代表 @yuzutas0 の感想コメントです。
— 株式会社風音屋 (@Kazaneya_PR) September 1, 2023
"対話型BIツールのデモが衝撃的でした。3行サマリーや1つのグラフの生成なら過去にもありましたが、自動でダッシュボードが丸々作られたときのインパクトは想像以上です。DWH&BIの次の3年について社内Slackで議論が盛り上がりました。" #GoogleCloudNext
■ データアナリストの働き方
データアナリストにとっては、おそらくChatGPTよりもStable Diffusion(いわゆるイラストAI)を想像してもらったほうが感覚が掴めると思います。
チャットに対してダッシュボードを作ってくれるやつのデモ、思ってた以上にカジュアルな聞き方で、思ってた以上にリッチなダッシュボードが作り込まれて「マジ!?」となってる。データ分析業務にとってのChatGPTやStableDiffusion的な。これが普通になるなら働き方は変わりそう。 #GoogleCloudNext
— ゆずたそ / Sho Yokoyama (風音屋) (@yuzutas0) August 31, 2023
イラストAIは、既にイラストを書ける人からすると「痒いところに手が届かない」「手直しで余計に時間がかかる」といったフラストレーションもあるでしょう。人気ゲームのパッケージイラストであれば描き下ろしのほうがマッチするはずです。反対に、自力でイラストを書けない人が、個人ブログの見出し画像を作ったり、LINEやSlackのアイコン画像を作る分には、これ以上なく便利なツールです。好みのテイストにあったモデルを選び、プロンプトを調整しながら画像を生成しまくって、最後にベストショットを選別すれば終了です。
おそらくダッシュボード生成AIも同じような位置付けになるのではないでしょうか。一流データアナリストの100点を再現するツールではないはずです。せいぜい50点しか取れないのではないでしょうか。コアとなる経営指標の設計、グロース戦略に関わる根幹のモニタリング、IRで開示するデータの抽出といったクリティカルな業務では、引き続きハイスキルなデータアナリストをアサインすべきでしょう(もはや職種名はデータアナリストではないかもしれませんが)。
一方で「10秒で50点のダッシュボードが作れる」というのは革命です。データアナリストに5人日で仕事をお願いするよりも、圧倒的に素早く、格安でPDCAサイクルを回せることになります。ちょっとした施策のモニタリング程度であれば50点のダッシュボードでも問題ないはずです。というかハイスキル人材に100点のクオリティで仕上げられても「そこまでしなくていいですよ」と言いたくなるでしょう。ダッシュボード生成AIを駆使して、業務を担当する人が自分でデータを見ることで、データ分析&業務改善が一気に進むのが理想です。
<DWH:データサイエンス連携の強化>
GoogleCloudにおけるデータ活用の中心にあるのがBigQueryです。BigQueryのアップデートとしては、データサイエンスの敷居を下げるようなものが多かったように思います。前半のセッション紹介と重なる内容が多いので、最低限の記載に留めておきます。
■ LLM / GenAI
ML.GENERATE_TEXTと呼ばれる関数が追加され、SQLでテキスト生成ができるようになりました。商品タイトルだけで商品カテゴリーのデータがない場合に、SQLでテキスト分類を行うといったことが可能になります。
風音屋では以前、Google Cloud Day '23 Tour in TOKYO や 風音屋TechTalk #4 といったイベントにて、BigQueryとChatGPTの連携事例を紹介しました。こうした取り組みがSQLで手軽に実現できるようになります。本エントリーの公開時点で、既にクライアントでの利用実績も出ています。
■ Feature Store(FS)
Vertex AI Feature Store との連携もアナウンスされています。FSは機械学習の特徴量を管理するためのシステムです。BigQueryのテーブルをそのままFSとして使えるので、BigQueryベースで商品レコメンドAPIを構築できることになります。専任の機械学習エンジニアが不在で、ML Opsの仕組みが弱いところにとっては、1つの選択肢になるかもしれません。
■ Pandas / sklearn
PythonをBigQueryエンジンで動かすためのライブラリ「BigQuery DataFrames」がアナウンスされました。通常のPythonライブラリと同様に「pip install --upgrade bigframes」でインストールし、「bigframes.pandas」でPandas互換、「bigframes.ml」でscikit-learn互換のソースコードを実行できます。
SQLで表現できない(または表現しにくい)データ加工や機械学習の処理が必要になった場合、従来だとBigQueryからデータを取り出して、別のPython実行環境に移す必要がありました。BigQuery DataFramesを使うと、Pythonで書いた処理をBigQueryに受け渡し、BigQuery上でデータが集計されます。
■ Jupyter Notebook
「BigQuery Studio」と銘打ってBigQueryのコンソールが大幅アップデートされています。1つ目のアップデートは「Jupyter Notebook」です。
PythonでBigQuery DataFramesを使うとしても、Python自体を実行する環境が必要となります。これまではGKEやCloud Functionsがその役目を担ってきました。BigQueryのコンソールで完結するのであれば、それに越したことはありません。
類似サービスとしてはGoogle Colabが挙げられます。Google Colabでも十分便利ですが、利用規約の観点で商用利用に懸念が残ります。BigQueryのコンソールで完結するのは何かと安心です。利用者視点でも1つのサービスで完結したほうがラクになります。
他の類似サービスとしては、Vertex AI WorkbenchやAmazon SageMaker Studio Labが挙げられます。データサイエンス部門が既に存在して、これらのツールを採用している場合は、周辺機能も活用したいでしょうから、無理にBigQuery Studioを使う必要はないかと思います。
なお、Google Cloud の各コミュニティではあまり言及されていませんでしたが、Amazon Redshit には既に類似機能があります。複数クラウドでデータ分析を経験している人間としては「BiqQueryが新しい体験を提供してくれた」というよりは「これまでBigQueryで不便だった点が解消された」と捉えるほうが自然かと思います。
■ グラフ表示
BigQuery Studioの2つ目のアップデートは「グラフ表示」です。SQLで集計する→グラフを可視化する→スクリーンショットを取る→スライドやレポートに貼り付ける、といった使い方であればBigQueryコンソールで完結します。
RedashやMetabaseのようなOSSのBIツールを使っているのであれば、この機会に除却を検討しても良いでしょう。アドホック分析やデータ抽出の用途だけであれば、もはや無理にBIツールを運用保守する必要はありません。GoogleグループにBigQueryの権限を紐づけるだけで済むので、BIツールの権限管理作業も不要になります。
現時点では「アドホック分析であればコンソールでSQL&グラフ作成」「継続してモニタリングするデータはLookerStudioでダッシュボード化」といった使い分けが良さそうです。将来的にDuet AIによってLookerStudioの探索力が上がるようであれば、ツールの位置付けは変わってしまいそうですが……。
ちなみに「グラフ表示」もRedshiftやSnowflakeでは既に類似機能があり、これらのツールのほうが表示できるグラフの種類も多いので、BigQueryは競合劣位を解消しているフェーズと言えそうです。
<メタデータ:指標管理の中心はどこか>
データエンジニアリング領域で Duet AI を使っていくにあたって、Googleメンバーとperson-to-personで会話した限りでは、メタデータの拡充が重要になってくるだろうとのことでした。メタデータ整備の観点だと、Dataplex、Looker、dataformに言及せざるを得ないでしょう。
■ メタデータ管理
まず、Dataplexには明らかに力を入れているように見えます。Duet AIにダッシュボードを自動で作ってもらうにしても、Dataplexにメタデータが登録されているほうが精度が上がるのだろうと私は解釈しています。Google Cloudの他サービスとBigQueryの連携は今後も強化されていくでしょうし、その際にはDataplexが参照されるはずです。少なくともテクニカルメタデータやデータ品質系の情報については、OSSやサードパーティーのデータカタログをわざわざ導入するくらいであれば、Dataplexに寄せてしまったほうが何かとお得かと思われます。
■ セマンティックレイヤー
次に、Lookerについても同様で、各セッションや公式アナウンスを拝見すると、Lookerをエコシステムの中心地にしようとしているように見えます。Lookerで指標を定義して、指標の説明文をメタデータとして管理し、Dataplexに連携できると、たしかに快適になりそうです。もともとLookerを導入している企業はこれもアリだと思います。
ただ、Lookerや周辺サービス(特にLooker Modeler)がエコシステムの中心地になるかは、やや懐疑的に見ています。最初のハードルは価格面です。BigQuery、LookerStudio、dataform、Connected Sheetは無料で使えるからこそ普及している側面もあるはずです。Lookerや派生ツールに費用がかかるのであれば、導入を見送りする企業は一定数いるのではないでしょうか。
また、公式アナウンスでは「セマンティックレイヤー」という言葉が何度か出ています。しかし「顧客が本当にほしかったもの」は「セマンティックレイヤーと呼ばれる単体のツール」ではないように思います。長くなりますので割愛しますが、機会があれば「セマンティックレイヤーの幻想と現実」という記事を別で書きたいところです。
■ ELTパイプライン
最後に、dataformです。Lookerと反対で、むしろdataformのほうが注目に値すると考えています。Google Cloud Next '23 ではdataformをテーマにした単独セッションはありませんでした。そのわりには、事例セッションのシステム構成図を見ると、dataformが頻繁に登場していました。無料ツールということもあり「Google Cloud 公式としてはそこまで推していない」「ユーザーは世界中で使っている」という状態なのかもしれません。
類似サービスであるdbtは世界中で注目されており、本エントリー執筆時点においては、ELTパイプラインツールこそがデータプラットフォームの中心地だと言えるでしょう。dbtにMetricFlowと呼ばれるLookMLライクな指標管理機能(セマンティックレイヤー)があるように、dataformで同様の指標管理が簡単にできて、そのメタデータをdataplexに連携できるのが理想です。Lookerをメインにするより、dataformをメインにして、dataformから指標管理に発展させるビジョンのほうが、喜ぶ人は多いのではないでしょうか。
なお、dbtとの比較で言うと、事例セッションでdataformが多々言及されていたこともあり、GoogleCloud(特にBigQuery)を使っていて、今からデータパイプラインを構築する分には、特別な事情がなければdbtではなくdataformを使うほうが筋が良さそうかな、という印象は受けました。既にdbtを使っているのであれば、dbtのほうが現時点では高機能ですので、無理にdataformに置き換える必要はないと思います。利用数はそのうち逆転してdataformのほうが主流になっていきそうだなとは感じました。
<Recapまとめ:データエンジニアリングの未来像>
上記のような内容を、クライアントと風音屋のRecapでディスカッションしていました。
今回は特に大規模言語モデル(LLM)が存在感を発揮しており「Google Cloudにおけるデータエンジニアリングの未来像」を議論せずにはいられませんでした。
風音屋に関わってくださっている皆様に対して、こうしたディスカッションの機会は今後も積極的に提供していきたいと思っています。
最後に代表 @yuzutas0 の感想コメントです。
— 株式会社風音屋 (@Kazaneya_PR) August 30, 2023
"新しいテクノロジーの紹介を聞いたりデモを見て、風音屋の今の仕事の範囲だけでも、まだまだ新しいプラクティスを探索できると感じました。まさにメンバー1人につき1冊の専門書を書けそうだ、むしろ開拓余地だらけだ、と思っています。" #GoogleCloudNext pic.twitter.com/A815JtYwpy
おわりに
合計3日にわたって開催された本イベントですが、セッションやKeynoteの動画は Google Cloud Next公式サイト より、オンラインで視聴可能です(※一部セッションについては、動画が公開されていない場合もあります)。今回ご紹介した以外にも様々なセッションがありますので、ご興味がある方はぜひご確認ください。
今回のGoogle Cloud Next '23の話題の中心はやはり生成AIや対話型AIでした。データ領域を強みとする弊社にとって関係の深いセッションが多く、非常に充実した3日間を過ごすことができました。
カンファレンスに現地参加することの醍醐味の一つは、熱気を肌で感じられることだと思います。セッションやブース以外でもカンファレンス参加者の交流のためのイベントも企画されているので、たくさんの人と繋がることができます。
また、普段使用しているGoogle Cloud Platformのツールのプロダクトオーナーやデベロッパーが登壇されており、関係者に直接質問できる機会はとても貴重です。セッション終了後の質問コーナーが盛り上がることもあり、この質問コーナーは動画では見ることができません。
現地に行くことでしか得られない経験もたくさんあるので、ぜひ次回のGoogle Cloud Nextの参加を検討されてみてはいかがでしょうか!
Google Cloud Next '24は 2024/04/09〜2024/04/11にアメリカ・ラスベガスで開催予定とのことです。ご興味のある方は、Google Cloud Next 公式サイトでメールアドレスを登録し、最新情報を受け取ることをおすすめします!
カジュアル面談&採用のご案内
シニア・ジュニアを問わず、データ領域を中心に各ポジションを絶賛採用中です。「いつかは海外で登壇したい」「新機能を踏まえたベストプラクティスを開拓したい&発信したい」という方は、ぜひご応募ください。
この記事が気に入ったらサポートをしてみませんか?