Tableauを利用してKaggleに挑戦

こんにちは。Tableauの勉強をしており、Kaggleの特徴量の可視化に利用すると便利なのではと思いました。
そこで、実際にKaggleのチュートリアルコンペに利用してみようと思います。
住宅価格を予測する以下のコンペに挑戦します。
学習環境の設定
機械学習にはLightGBMを利用します。
学習パラメータは最低限のみ設定し、特にチューニングなどは行いません。
また、テストデータは30%とし、クロスバリデーションは特に行いません。
Tableauで読み込み
とりあえずどのような特徴データがあるかをTableauで表示してみました。
特徴データが80列と多く全てを一つずつ見ていくことは難しそうですが、半分ほどのカラムが文字列となっていました。Lightgbmで学習させるためにはラベルエンコーディングを行う必要があるということが分かります。
一度ラベルエンコーディングを行った段階でテストデータを予測してみたところ、スコアは0.14034でした。
スコアが低ければ低いほど予測との誤差が少ないため、更にスコアを小さくすることを目指します。
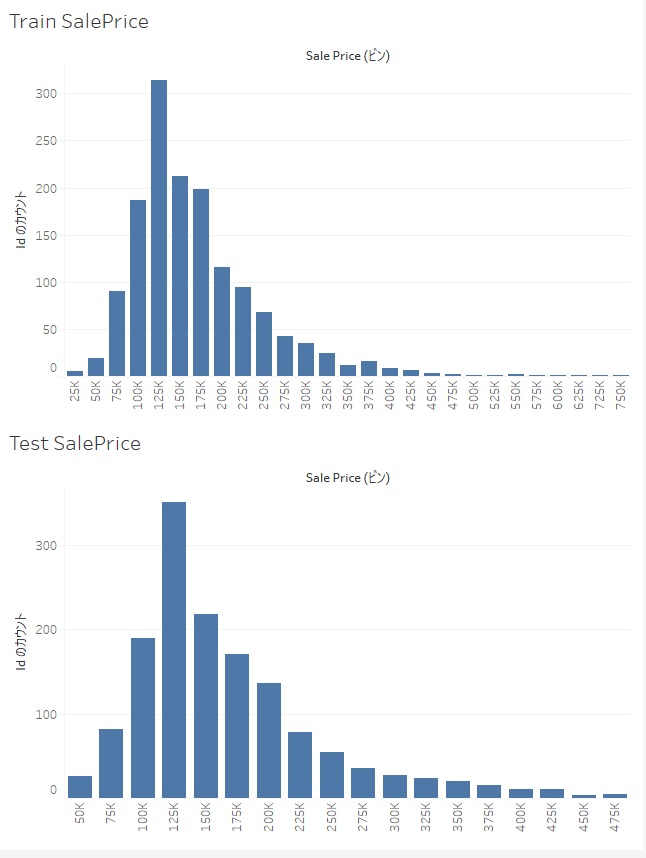
住宅価格の分布の確認
予測対象である住宅価格がどのような分布になっているか確認してみます。
学習データとテストデータから予測した住宅価格を見たところ、ボリュームゾーンである75K ~ 175Kあたりはほぼ同じような分布になっています。
一方で、高額な住宅価格帯である350K以上に注目すると学習データでは750Kまで住宅価格が存在していますが、予測した住宅価格では475Kまでしか存在していません。
テストデータにも同様に750Kまでの価格が含まれていると考えると高額な住宅価格の予測ができていない可能性がありそうです。
相関が高い特徴の改善
すでに相関が高い特徴の相関がより高くなる方法を検討します。
相関係数が0.7以上の特徴を可視化してみました。

数値データのTotalBsmtSF / GarageArea / GrLiveAreaは一部にデータが集まっているため標準化したほうがよさそうですね。
更に改善する方法を考えるのであれば離散化しても効果があるかもしれません。
相関が無い特徴の改善
相関が無い特徴を見てみます。
今回は相関係数が±0.1以下のカラムをTableauで可視化し、本当に相関が無い
特徴なのかを見ていこうと思います。
もし相関がないことが明確であれば、学習から排除したほうが良いです。
不要な特徴を学習データに加えてしまうと精度を落とす可能性があるためです。
'Heating': -0.0988120759975764,
'BldgType': -0.08559060818352954,
'MSSubClass': -0.08428413512659509,
'OverallCond': -0.07785589404867797,
'LotConfig': -0.06739602315941755,
'SaleType': -0.05491147712871197,
'YrSold': -0.028922585168736813,
'LowQualFinSF': -0.02560613000067955,
'Id': -0.021916719443430967,
'MiscVal': -0.021189579640303213,
'BsmtHalfBath': -0.01684415429735895,
'Utilities': -0.01431429614724878,
'BsmtFinSF2': -0.011378121450215146,
'GarageQual': 0.00686116741839528,
'Condition2': 0.0075127340363331,
'BsmtFinType2': 0.008040995809556058,
'BsmtCond': 0.015058006077546142,
'LandContour': 0.015453241660960324,
'GarageCond': 0.025149248099587577,
'MasVnrType': 0.029658392546351983,
'Street': 0.041035535500049444,
'3SsnPorch': 0.04458366533574838,
'MoSold': 0.046432245223819446,
'LandSlope': 0.0511522481794664,
'MiscFeature': 0.0736088198872433,
'Condition1': 0.09115491154092803,
'PoolArea': 0.09240354949187318,二値分類に変換するカラム
可視化したところ、MiscVal / BsmtFinSF2 / 3SsnPorch / PoolArea / LowQualFinSFは数値データですが、ほとんどのデータが0となっており、かなりデータが偏っています。
Heating / BsmtHalfBath / Condition2はラベルデータですが、1つのラベルに値が偏ってします。
偏りがあるデータは少数のデータが学習に反映されない可能性があります。そこで今回は 0 or 1 の二値分類に変換します。
削除するカラム
以下のカラムは相関係数通り全く相関がなさそうな特徴です。
YrSold / MoSold
また、以下のカラムは2つしかないラベルデータかつ片方にデータが偏っている特徴です。
Street / Utilities
これらの特徴は学習には利用できなさそうなため学習データから削除します。
修正後の住宅価格の分布
上記の特徴の加工を実施後、住宅価格の予測を再度可視化します。

高額な住宅価格の予測は改善できませんでしたが、25K台の予測が増えています。学習データの分布に近づけることができました。
さて、気になるスコアの方ですが、残念ながら0.14097と増加してしまいました。
どうやら今回改善した内容ではあまり効果がなかったようです。
まとめ
Pythonで書き捨てのコードを作成するようなイメージでTableauを使ってみましたが、非常に使いやすかったです。
特に簡単な可視化であればドラッグ&ドロップで行えるため、わざわざPythonでグラフを作成するコードを書いていた時に比べるとかなり楽になりました。
今回作成したVizはこちらにあります。
この記事が気に入ったらサポートをしてみませんか?