
4章アルファ-ファクター研究: 第一節: 特徴量エンジニアリング

こちらでは、特徴量のデータセットを作っていきます。様々な手法が紹介されているので参考になるかと思います。
本記事のnotebookで実行するためにはいくつか必要なモジュールとデータセットがございますので、もしデータセットで行き詰った場合は、こちらのノート(データセット準備編)をご参考くださいませ。
まずは普通にimportします。pyfinance等のモジュールは各自インストールをお願いいたします。
インポート
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
from datetime import datetime
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import pandas_datareader.data as web
from pyfinance.ols import PandasRollingOLS
#plotのスタイルsns.set_style('whitegrid')
idx = pd.IndexSliceデータ取得
#データの位置
DATA_STORE = '../data/assets.h5'
#期間指定
START = 2000
END = 2018
#データ取得
with pd.HDFStore(DATA_STORE) as store:
prices = (store['quandl/wiki/prices']
.loc[idx[str(START):str(END), :], 'adj_close']
.unstack('ticker'))
stocks = store['us_equities/stocks'].loc[:, ['marketcap', 'ipoyear', 'sector']]
pricesは2412銘柄で4706営業日あります。

stocksは2412銘柄の時価総額、IPO時期、セクターの情報です。
データの整理とフォーマット
stocksから重複しているインデックスを削除して、stocksとpricesの共通部分だけを取得します。今回のデータセットはちゃんとしていたが、他のデータセットを使うときには役に立ちます。
#重複を削除
stocks = stocks[~stocks.index.duplicated()]
stocks.index.name = 'ticker'
#共通部分のみを取得
shared = prices.columns.intersection(stocks.index)
stocks = stocks.loc[shared, :]
prices = prices.loc[:, shared]本データセットは日次データとなっており、計算量の削減と戦略の保有時間を伸ばすために、日次を月次データに変換する。
monthly_prices = prices.resample('M').last()ここから特徴量生成を行うが、たとえば、モメンタムのパターンをダイナミクスに反映させたい場合は.pct_change(n_periods)メソッドを使用して過去のリターンを計算します。つまり、ラグによって識別される月ごとのさまざまな期間のリターンを計算します。
次に、.stack()メソッドを使用してワイド結果をロングフォーマットに変換し、.pipe()を使用して.clip()メソッドを結果のDataFrameに適用し、[1%、99%]レベルでリターンをウィンソライズ(取り除く)します。つまり、これらのパーセンタイルで外れ値を除きます。
最後に、幾何平均を使用してリターンを正規化します。 .swaplevel()を使用してMultiIndexレベルの順序を変更した後、1か月から12か月の範囲の6つの期間の複合月次リターンを取得します。
outlier_cutoff = 0.01
data = pd.DataFrame()
lags = [1, 2, 3, 6, 9, 12]
for lag in lags:
data[f'return_{lag}m'] = (monthly_prices
.pct_change(lag)
.stack()
.pipe(lambda x: x.clip(lower=x.quantile(outlier_cutoff),
upper=x.quantile(1-outlier_cutoff)))
.add(1)
.pow(1/lag)
.sub(1)
)
data = data.swaplevel().dropna()
data.info()上場10年未満の株式を取り除きます。
min_obs = 120
nobs = data.groupby(level='ticker').size()
keep = nobs[nobs>min_obs].index
data = data.loc[idx[keep,:], :]リターンの相関関係を見る。
sns.clustermap(data.corr('spearman'), annot=True, center=0, cmap='Blues');
概ね相関性は高い。株はやはりモメンタムがありそうだ。ここからは、様々な特徴量を作成し、本データセットに入れていく。
※相関が高いからと言って、モメンタムがあるとは限りません。こちらは私のミスです。失礼いたしました。こちらでは、クラスタリングを目的としており、そういった解釈はnotebookの方にも記載されておりません。
ローリングファクターベータ(Fama-French)
ここでFama-French法を紹介する。この手法は、一般的なリスク要因への資産のエクスポージャーを推定するためにある。詳しくは8章参照(Time Series Models.)
5つのFama-Frenchファクター、つまり市場リスク、サイズ、バリュー、営業収益性、および投資は、資産のリターンを説明するために経験的に示され、ポートフォリオのリスク/リターンのプロファイルを評価するために一般的に使用されます。したがって、将来のリターンを予測することを目的としたモデルに、過去の要因のエクスポージャーを財務上の特徴として含めるのは当然です。
次のように、pandas-datareaderを使用して履歴因子のリターンにアクセスし、pyfinanceライブラリのPandasRollingOLSローリング線形回帰機能を使用して履歴の露出を推定できます。
Fama-Frenchリサーチファクターを使用して、市場リスク、サイズ、バリュー、営業収益性、投資の5つのファクターに対するデータセット内の株式のファクターエクスポージャーを推定します。
factors = ['Mkt-RF', 'SMB', 'HML', 'RMW', 'CMA']
factor_data = web.DataReader('F-F_Research_Data_5_Factors_2x3', 'famafrench', start='2000')[0].drop('RF', axis=1)
factor_data.index = factor_data.index.to_timestamp()
factor_data = factor_data.resample('M').last().div(100)
factor_data.index.name = 'date'
factor_data = factor_data.join(data['return_1m']).sort_index()次にこのモデルからベータを計算する。
T = 24
betas = (factor_data
.groupby(level='ticker', group_keys=False)
.apply(lambda x: PandasRollingOLS(window=min(T, x.shape[0]-1), y=x.return_1m, x=x.drop('return_1m', axis=1)).beta))
cmap = sns.diverging_palette(10, 220, as_cmap=True)
sns.clustermap(betas.corr(), annot=True, cmap=cmap, center=0);24-window期間でローリングしてbetaの相関行列を見る。
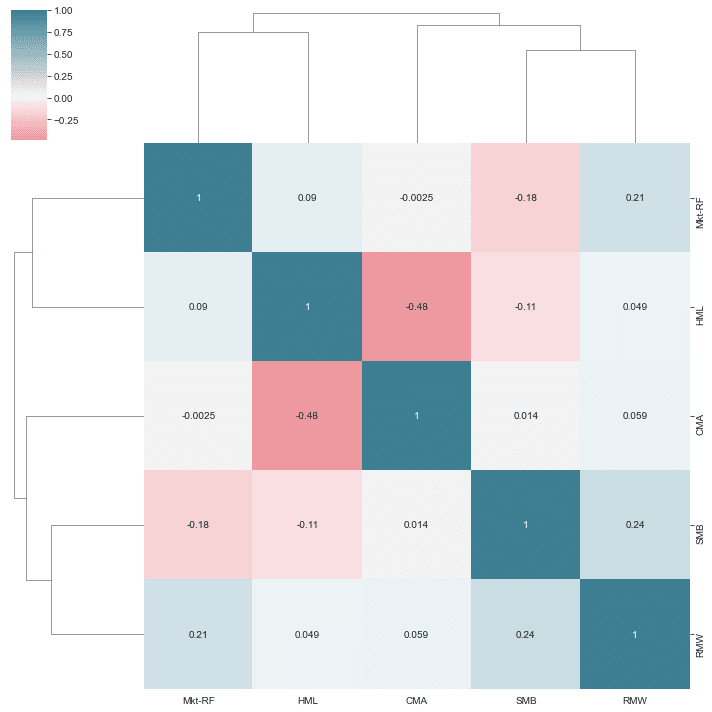
次にbetaを特徴量に入れます。
data = (data
.join(betas
.groupby(level='ticker')
.shift()))
#欠陥データを平均補完する。
data.loc[:, factors] = data.groupby('ticker')[factors].apply(lambda x: x.fillna(x.mean()))モメンタムファクター
for lag in [2,3,6,9,12]:
data[f'momentum_{lag}'] = data[f'return_{lag}m'].sub(data.return_1m)
data[f'momentum_3_12'] = data[f'return_12m'].sub(data.return_3m)時間インジケーター
dates = data.index.get_level_values('date')
data['year'] = dates.year
data['month'] = dates.monthラグリターン
for t in range(1, 7):
data[f'return_1m_t-{t}'] = data.groupby(level='ticker').return_1m.shift(t)
data.info()保有期間リターン
for t in [1,2,3,6,12]:
data[f'target_{t}m'] = data.groupby(level='ticker')[f'return_{t}m'].shift(-t)上場年数
data = (data
.join(pd.qcut(stocks.ipoyear, q=5, labels=list(range(1, 6)))
.astype(float)
.fillna(0)
.astype(int)
.to_frame('age')))
data.age = data.age.fillna(-1)時価総額
NASDAQティッカー情報からの時価総額情報を使用して、企業の大きさを作成します。
size_factor = (monthly_prices
.loc[data.index.get_level_values('date').unique(),
data.index.get_level_values('ticker').unique()]
.sort_index(ascending=False)
.pct_change()
.fillna(0)
.add(1)
.cumprod())msize = (size_factor
.mul(stocks
.loc[size_factor.columns, 'marketcap'])).dropna(axis=1, how='all')サイズのインジケーターとしてそれぞれの期間の十分位を作成
data['msize'] = (msize
.apply(lambda x: pd.qcut(x, q=10, labels=list(range(1, 11)))
.astype(int), axis=1)
.stack()
.swaplevel())
data.msize = data.msize.fillna(-1)データの結合
data = data.join(stocks[['sector']])
data.sector = data.sector.fillna('Unknown')データの保存
with pd.HDFStore(DATA_STORE) as store:
store.put('engineered_features', data.sort_index().loc[idx[:, :datetime(2018, 3, 1)], :])
print(store.info())ダミー変数の作成
dummy_data = pd.get_dummies(data,
columns=['year','month', 'msize', 'age', 'sector'],
prefix=['year','month', 'msize', 'age', ''],
prefix_sep=['_', '_', '_', '_', ''])
dummy_data = dummy_data.rename(columns={c:c.replace('.0', '') for c in dummy_data.columns})
dummy_data.info()まとめ
特徴量エンジニアリングは、オルタナティブデータやマーケットデータを色々と弄ります。集計スキルはとても大事です。集計が出来れば、特徴量エンジニアリングはグッと楽になると思います。特徴量データセットを作成したら、やっと本格的にモデリングの話に入ることが出来ます。