
反AIって何?|週刊かもめ研

「面白くない議論だな」
以前から議論が起きていることは知っていたし、関心の範囲の話題でもあった。しかし、調べ始めた段階でも、あまり興味が湧かなかった。それは、あまりにも議論が単純すぎるからで、「合法」の一言で片付くことだと思っていたからだ。興味が湧きだしたのは、いくつかの資料を読んで、反AI派(正確にはAI自体に反対しているのではなく、主に生成AIの無断学習に反対する人達)の主張を読み、さらに、クリエイターのアンケートを読んだ辺りのことだった。「なんか酷いことになってる」と思い始めた。
AI の拡散に対し世界の創作者と実演家はクリエイティブライツを求めるhttps://www.jasrac.or.jp/information/topics/pdf/Open_Letter_JP.pdf
全クリエイター実態調査アンケート10 AIリテラシー(集計結果)
https://artsworkers.jp/wp-content/uploads/2023/06/2023_0608.pdf
議論の内容が分かったからといって、ただの「にわか」だが、
これは、書かずにはいられない話題なので記事にしている。
「何に反対しているのか」分かりづらい
AI論争は、いきなり入り口から理解に苦しむ。
当然、「生成AIの無断学習に反対する」のは分かる、しかし
「なぜそこなの?」という理由が分からない。
生成AIの開発過程で、学習前の処理過程に、データを整える作業がある。
この工程でデータが改変されることを非難しているのか。しかし、改変データが公開されるわけではないから、解析を目的としていれば、著作権法上は合法である。(脱法的手段ではある)
学習後の生成AIのモデルは抽象的なデータであり、それ自体が特定の作品と一致することはないし、作品のコピーを大量に保有するシステムでもない。
反AI派は、生成AIの学習過程も著作権法も理解しているが、それでもなお
反対しなければならない理由があるのかもしれない。
生成AIの登場によって、何が起きているのか
「いきなり価値が変わった」
生産性の向上によって、物の価値が変わり、人の関わり方が変わり、
人の認識が変わり、人の価値基準(相場観)が変わりつつある。
価値基準を物に反映する過程と「逆の順序」で、生成AIが現実を変えている。人が価値判断をするとき、価値基準を元に、物事を認識し、関与し、物の価値を図る。
相場の変化があまりにも急速すぎて、相場観の設定が追い付かないと
大きな損失を招くことがよくある。
生成AIを利用するまで「望み通りの絵や文章を入手する」という
経験が、ほとんどの人は初めてだったのではないか。
その時に、生成AIの圧倒的な生産性に、驚きと衝撃を
ほとんどの人が感じただろう。
その経験を経て、生成AIの存在価値の否定など考えつくだろうか。
生成AIと生成物の価値を冷静に評価できるだろうか。
この議論では直感的には、価値の置き方が重要な点になると思ったが、
様々な意見を読むうちに、価値の喪失が問題であるように思えてきた。
その経済的価値が不明確なものが奪われることが問題となる。
なんで怒ってんの?
創作に携わる人が過敏に反応している理由について考える。
これらの人々が得意なことは
「ある仮の状況において、何が起こるかを考える」
既存の課題設定から論理的に考えれば、議論にならない問題であっても、
クリエイターは、仮の状況を設定して具象化していけば、
その先にある事態に気づいてしまう。
反AIに関して言えば、ただの想像だろうと切り捨てられない。なぜなら、
多くのクリエイターが同じ「最悪の状況」を見据えて声を上げている。
つまり、彼らの主張が妥当な推論と一致する将来像についての懸案であれば、将来の状況に対応していない現行法で否定したところで、論破したことにはならない。
AI と著作権に関する議論の論点整理のため、文化庁から
「AIと著作権に関する考え方について(素案)」が公表され、
それに対して意見募集が行われた。
著作権管理といえば、JASRACが有名。
強力な主張だと思うが、どう反論されたのかを中心に読んでいく。
クリエイターによって具体的な表現(歌詞・楽曲)が異なるのは、アイデアを表現へと昇華させる際に大きな役割を果たす個性が異なるからであり、具体的な表現の特徴を決定付ける個性こそが作風の本質です。したがって、作風はアイデアに属するものではなく、アイデアと表現との中間領域に位置するもの捉えるべきです(「アイデア→作風→具体的な表現」というイメージ)。
JASRAC(一般社団法人日本音楽著作権協会)による具体的主張内容

主張されている意見から考えられる状況は、
・作品のオリジナリティに関わる「作風」が保護されない。
類似作品が大量に安価に生成され、即座に陳腐化する。
・作品制作のコンセプトワークやプロデュース業務が、タダ働きになる。
人が集まって協議しながら、時間をかけて作品を制作していくような
プロセスが成立しなくなる可能性がある。
文化庁の見解
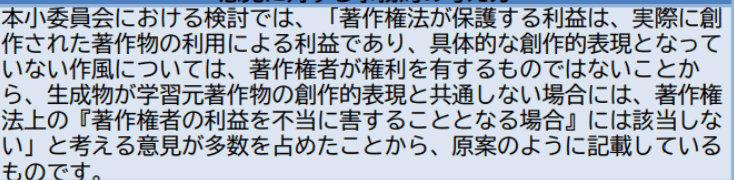
「盗用」に関する議論
生成AIの無断学習による著作物の「盗用」は、脱税に似ている。
本来、納めるべき税を納めないことは、逆説的に
国民全員から少しずつ金を盗んでいる。
多くのクリエイターが築いたアーカイブから、
少しずつノウハウとテクニックを盗んでいる。
それも、アイデア、演出、効果、パターン、構成、表現様式という
クリエイターのオリジナリティに、直接かかわる発明でありながら、
法的に保護されていない作品の構成要素を盗用している。
しかし、「盗用」という言い方にも矛盾がある。
脱税に例えた通り、納税の義務があれば、盗みになるが、
法的に保護されていない現状では、「無断借用」とも言える。
長い闘いの歴史
アイディア・表現二分論の概念は、19世紀には成立していたという。
この話題がこじれる原因は、伝統的な揉め事の「ど真ん中」に嵌るからだろう。
先人が同じ論点で散々対立して、解決のための判断を積み上げている。
しかし、どちらの立場をとってもモヤっとする。
想定に基づく議論
1.「生産性を軸に考えると、多様性とトレードオフになる?」
クリエイターも時間労働のような働き方になるのかもしれない。
ごく少数の制作会社が寡占市場を形成して、クリエイターが
ノルマと時間制限が課せられて、AIを駆使して作品を量産し、
市場のほとんどの需要を満たすような状況になる。
2.「低品質の模倣作品が氾濫すると、市場が汚染される?」
個人作家のファンコミュニティが破壊されるかもしれない。
作者の意図しない模倣品によって、作品のイメージが毀損されたり、
消費者が被害を受ける事態が生じる可能性がある。
作品を求めている顧客と作者が分断される。
なぜ、このような想定を持ち出すのかというと、
議論のための想定、議論のための議論を避けるためだ。※1
このような兆しがあるせよ、現実味があるのか、現時点ではわからない。
作品を作り続ける限り、その周辺で様々なことは起こりえるが、
社会における「創作と生成AI」の位置づけを議論しても、
なかなか結論が出づらい。
個別具体的な社会問題の解決を優先すべきなのか。
「考え方」を定めるための議論をすべき時なのか。
議論の中心は、社会における権利の位置づけであり、
本気で「権利を守るつもりがあるのか」が問われている。
双方の主張の濃淡を列挙して示すと、
1.著作権者の権利拡大によって、学習を制限する。
2.学習データの利用許諾を簡便にする環境を整える。
3.既存の著作物の類似物を生成することを防止する手段を講じる。
4.現行法と現状の解釈で問題がない。
5.意図的でない限り利用者の生成物に対する依拠性を認めるべきでない。
ここまでの議論を踏まえると、3と4が、現実的な妥協点のように思われる。
ちょっと待てよ
意見を整理していたら、違和感を感じた。
アイディア・表現二分論に意見が集中する状態は、議論が偏っていないか?
今回の議論を持ち出した文化庁も「想定」を置いているのではないか?
文化庁の考え方において、想定されている「生成AI」とは、
AI の主な用途には、画像識別や、自然言語処理、文章や画像の生成等があるが、昨 今、特に大きな話題となっているのが、人間の自然言語や画像などによる指示を受け、 文章や画像等の様々なコンテンツを生成する AI であり、これがいわゆる生成 AI8と言 われるものである。
stable diffusionやchatGPTといった特定の製品を念頭においた議論になるように対象の範囲を限定している。説明のために「特に大きな話題となっている」は必要ない。これは意図的なミスリードで、論点が一点に集中するように議論を誘導したのだろうか?
生成AIが、これだけに限らないことは知られているし、実用化もされている。そちらについても同様に議論されるべきだ。
議論から除外されているAI
議論に上がっていない生成AIは、著作権との相性は最悪ではないか?
「著作物に表現された思想又は感情の享受を目的としない利用」という
断わりが通用するのだろうか。
拡張範囲の議論を切り捨てて、後で悲惨な状況に陥らないか。
マルチモーダル型:
・「マルチモーダル学習」
二つ以上の学習要素(たとえば音声と映像)を同時に学習させる手法
・「マルチモーダル生成」
二つ以上の命令要素をプロンプトに入力し、コンテンツを生成するAI
→現状の認識を遥かに超える能力を持つ。
現時点では性能が限定されているが、将来的に能力が強化されたとき、
漫画と声優の声を入力して、アニメーションを生成するとか、
やがて、動画を入力して、再編集を行い、別バージョンを生成するなど
コンテンツの視聴環境を劇的に変化させる可能性がある。
様々な面で破壊的な能力を持つのではないか。
パーソナルカスタマイズ型:
ユーザーの過去の行動履歴や嗜好を分析して、個別の設定を生成する。※2
→特定のジャンルやテーマ、キャラクターの属性などが厳密に指定された場合、生成されるコンテンツは指定に沿った内容となり、特定の作品と類似した要素を含む可能性が高くなり、後天的に、特定の作品を追加学習したような設定にならないか。
著作権を侵害する可能性があるタイプのAIは、他にも存在し得るだろう。
(「生成 AI に関する新たな技術」の項目で、検索拡張生成「RAG」と「ファインチューニング」は指摘されている)
現時点での問題は、ユーザが安易に著作権侵害を犯すことを前提として
サービスが設計される懸念があり、事業者側は、著作物を学習だけでなく、
フィードバックとして受け取り、リソースとして利用する場合もある。
生成AIは開発だけでなく、運用面にも多くの問題を内包している。
ビジネススキームを明確にしてから、どこに問題があるのか
指摘しないと議論が混乱するし、理解が深まらない。
(Image to Imageで、既存の著作物そのものを入力する場合は著作権侵害が成立するといった事例は示されていた)
パブリックコメントへの文化庁の回答を見るに、
議論の先送りを画策したのだろうか。
すでに認知され、実用化されている技術が大規模な権利侵害を前提として
成立しているので、権利についての再定義が必要であることは明白である。
生成AIは、まるで、著作権を無効化させるかのような性質を持つことが
一般に問題視されていないことが不思議だ。
未来の話だと議論を先送りにしていいのだろうか。
対策に生成AIと同等の技術は必要ない
いま求められているのは、著作権を管理するための社会システムだろう。
包括的な著作権管理システムというのは、実現が難しいのか。
適切な監督、指導を行うための日本版dmcaの法整備と連携して
情報を集約する著作権管理組織を設けるという方向性も、
検討すべきではないか。
具体的な対策については、政府、文化庁、総務省、経済産業省の方針発表を
確認していく必要がありそうだ。
「著作権侵害と誹謗中傷は似ている」
権利侵害が起きても加害側に有利な状況があるため、泣き寝入りが最も妥当な判断となる場合もあり、被害者は具体的な対応を取ることが困難である。
予防と監視が、重要な取り組みだが、対するコストのバランスが悪い。
対策を執るには、大掛かりな改革が必要となりそうだ。
分かりやすい論点に目を向けさせて議論を回避したい理由もわかる。
AIに関する議論で、論点がずれてずれて反転した例を紹介したい。
論点ずらしの例
国立情報学研究所に所属し、AIや教育についてメディアで発信する
新井紀子氏は、オールドメディアからは引く手あまたの人気者だ。
発信内容がオールドメディアの学歴信仰に刺さることが人気の秘訣だろうか。新井紀子氏が率いたAIの開発プロジェクトが、
「ロボットは東大に入れるか」
このロボットを使えば、誰でも東京大学に入学できてしまう。
教育格差を是正し、学歴社会に変革をもたらす夢のロボットではなく、
受験という分かりやすい共通の話題をネタにしたイベントだった。
プロジェクトの概要説明にある通り、「若い人たちに夢を与えるプロジェクト」として、AIに関する話題作りには、絶大な効果を発揮した。
プロジェクトの掲げる目標と課題を調べてみた。
・東京大学入学試験問題に対し合格レベルの得点を獲得する。
・細分化された人工知能分野を再統合する。
・新たな知的処理課題の発見・解決。
・「機械による人間の知的活動の模倣」に対する達成度を測る。
・人間の思考に関する包括的な理解を得る。
調べてみると、疑問だらけのプロジェクトだった。
webページの「連携基盤」を参照すると、人工知能分野を再統合するというのは、統合的な作業環境を提供することに留まっていて、結局、
縦割りの分業体制をとっている。
コラボレーションによる「統合的な技術」の創出を目指していないのか。
基盤グループでは、モジュール(コンポーネント)ごとに並列に研究を進め、かつ、多様な研究グループがそれぞれ得意なコンポーネントについて研究し、相互に成果を活用できるようにすることを目指し、ツールやデータの共有・組み合わせ・実行を容易にする統合研究基盤を構築しています。
知的処理課題の発見については、試験問題の「解き方」をプログラムとして記述しても人間の知的活動が分かるわけではない。当然、「解き方」が分かるだけだろう。
著者の読解力が追い付かないのだが、知的処理とは、
機械が行えば、情報処理で、人間が行えば、知的処理という言い換えなのか。
科目間で共通する知的処理について、どれだけ議論がなされ、発見があったのか。
成果として公表されいるもののどれが人間の思考に関する論文だろうか。
この研究における「知性」の定義が不明確である。※3
知性について考える場面というのは、
問題を作る側が解答者の知性を推し量って、考えるといった場合で
このくらいの内容ならば解けるだろうとか難易度を調整する。
試験問題を解くときには、自身の知性を自覚しない。
問題を解くために知能を使うが、それがどういったものか
考えるだろうか。また、
問題を解く過程という「思考の結果」を記述することは、
根本にある知性を理解することと関係があるのだろうか。
そして、このプロジェクトで東大合格を断念して導き出した結論が、
「AIは文章の意味を理解できない」
言ってる意味が分からない。
AIに限らず、人間も「意味」を定義できていない。
哲学の意味論は、解釈があるだけで、解決されるような問題でもない。
AIを開発しなければ、気づけないようなことだったのか。
意味解釈の技術的な方法を議論すべきであり、結論にするのはおかしい。
意味解釈を「暗黙的な指示関係を類推する過程」とみなした時の方法論的解決は、以下のような手法がある。
コーパスベースの手法:
大規模なテキストデータを用いて、言語の使用パターンや文脈を学習し、単語の共起頻度や文の類似性を計算することで、特定の単語やフレーズが特定の文脈でどのように使用されるかを理解することができます。
機械学習:
教師あり学習や教師なし学習を用いて、文脈情報や単語の関係を特徴として入力し、関連性や指示関係を予測するためのモデルをトレーニングすることができます。
照応解析:
特定の語句が以前の文脈や文で言及された対象を指しているかを判断するタスクです。代名詞や指示詞などの語句が何を指しているかを特定し、暗黙的な指示関係を解決します。
共参照解析:
文章中の代名詞や名詞句が何を指しているかを特定し、それらの間の関係性を解決します。
東ロボくんプロジェクトでも、これらの技術を用いて問題を解いている。
それがなぜ、「意味を理解できない」になるのか分からないが、
そもそも、外形的な事実として正解していれば意味を理解しているとみなす。試験とはそうゆうものではないのか。それに、
AIに意味を理解させることは当初の目的にない。
この結論における「意味」の定義が不明確である。
問題の解き方が研究対象だから、そのための自然言語処理の課題が解決されなかったと結論すればいいし、動作するシステムを完成させ、一定の成果もあげたのだから、そのように結論して非難されることもないだろう。
ところで、人間の思考に関する理解はどこにいったのか。
「教科書の読解力がなければ、AIに職を奪われる」
集合知であるAIに、一人の読解力で挑むらしい。
AI研究者が、「AI vs 人間」という、ガチの反AIを打ち出しているのである。
この発言もなかなかに雑で、学力と職能を混同している。
仕事においても暗黙知が存在し、コツ、要領、経験則などが必要となる。
それに、読解力の低さとAIで代替される職業との相関関係はあるのか?
読解力の低下が統計データで示しているのは分かるが、
職を失う過程は推論によって示され、一部では生産性の低下に置き換わっている。ちょっと危険な匂いもする発言である。
この発言における「職」の定義が不明確である。
個別的な課題の研究を行っていた研究者に、実用化の機会を与える
というプロジェクトの趣旨と東ロボくんの研究で得た知的処理のプロセスを読解力教育に利用することは理解できる。しかし、研究者は、
社会的な課題を解決するために研究を行い、成果である技術の実用化によって社会に影響を与え、社会的評価を得るというのが筋だと思う。
長々と書いてきたが、東ロボくんを例にとった理由は、
社会に広報するための建前とプロジェクトの内容が乖離していて、
広報内容がおかしな経緯を辿っていたからだ。
生成AIが絡み発生する社会問題については、AIや情報工学の関係者から
積極的に発信を行い、議論することで技術的な可能性と社会への影響を明らかにした方が、課題の発見と状況改善の手掛かりになるはずだ。大規模な社会システムが求められている時に、介入しない理由はないと思う。
技術的な側面(実用化された際のビジネススキーム)と権利侵害に関わる社会問題が整理されないまま、現行の制度の元、無批判に推進の立場をとった場合、同じような論点ずらしの経緯をたどって、軋轢が表面化した後で、全体として立場を反転しても遅い。
※1
起点となる出来事から将来の状況を想像したり、
条件を置いた試行から、想定ができる。しかし、
局所的に起きた事象や事実関係から、特定の範囲に起こる現象を予想したり、一般的に起こる現象、最終的な結果を予測することは非常に難しい。
対して、議論の内容を想定することは簡単だ。
現時点で判明した事実と現在の知識に限定して回答できることだけ、
将来に渡る事柄は考慮に入れなければ、何も動かさず検討せずに済む。
双方が共通の認識、論点を模索して議論が成立する。
推進にしても、反対にしても、それぞれの選択肢を取った場合、
日本全体としての損得が見積もられているのだろうか。
とにかく、疑問が尽きない話題である。
※2
カスタマイズのために生成とは別のモデルが存在し、
複数の指示を要約して生成モデルに指示を送っている?
とすれば、内部ではプロンプトへ入力した指示内容と異なる
指示が生成モデルに与えられていると考えられる。
構成について情報が少ない。
※3
「知性と知能の違い」
実を言うと、著者も論点をずらしている。
AIとは「人工知能」とよばれ、人間の知能を模倣したものである。
しかし、知的活動における知能の在り様を調べるには、
より広範な知性についての検討が必要となるという意味で用いた。
言語処理における「知性」と「知能」の違いを考えると、
知性はより高度な理解や意味解釈に関連しており、
知能は具体的な言語スキルや処理能力を指します。
知性:
知性は、文章の文脈や言葉の持つ様々な指示関係を理解する能力に関連しています。文脈や意味を理解し、それに基づいて適切な応答や行動を生成するための推論、洞察力を指します。
知能:
知能は、言語のルールや構造を適用して情報を処理するようなタスクにおける技術的な能力を示します。文法や構文の正確性、語彙の知識、作文スキルなどが含まれます。
参考資料:
・対策技術
・生成AIの規制の動向
総務省 EUのAI規制法案の概要
https://www.soumu.go.jp/main_content/000826707.pdf
・生成AI開発における学習に関する動き
・新井紀子氏に関する資料
この記事が気に入ったらサポートをしてみませんか?