
DifyでRAGを爆速で構築する

こんにちは、スクーティー代表のかけやと申します。
弊社は生成AIを強みとするベトナムオフショア開発・ラボ型開発や、生成AIコンサルティングなどのサービスを提供しており、最近はありがたいことに生成AIと連携したシステム開発のご依頼を数多く頂いています。
Dify愛が止まりません。何でしょう。この思い。
DifyはノーコードのLLMプラットフォームのように言われることが多いですが、様々な言語モデルや、何なら外部サービスなどを組み合わせていろんなことができます。アイデア次第でいろんなことができてしまうので、知的好奇心がくすぐられます。今回はDifyでRAG(文書検索)をサクッと作ってみました。
Difyの環境を準備する
今回はMacOSのローカルPC上で動作することを前提とします。
ローカルPC上にDifyを立ち上げる方法は、「DifyでSEO記事作成を試してみる」に詳しく記載していますので、そちらをご覧ください。
また、DifyはかなりアクティブなOSSで頻繁に更新されるため、最新のソースコードに更新しておく必要があります。その方法は「ローカル環境上のDifyでGPT-4oを使えるようにする」をご覧ください。
DifyでRAGを構築する
Knowledgeを作成する
Difyでは、検索対象とする文書は「Knowledge」という単位で管理します。
したがって、まずは準備としてKnowledgeを登録します。

上部メニューから「Knowledge」を選択し、「Create Knowledge」をクリックします。こちらから新規にKnowledgeを登録できます。

次の画面で、RAGの検索対象にしたいドキュメントをアップロードします。
ここですべてのドキュメントをアップロードしておく必要はなく、ある程度まとまったカテゴリ毎にドキュメントをアップロードしておくのが管理しやすいです。
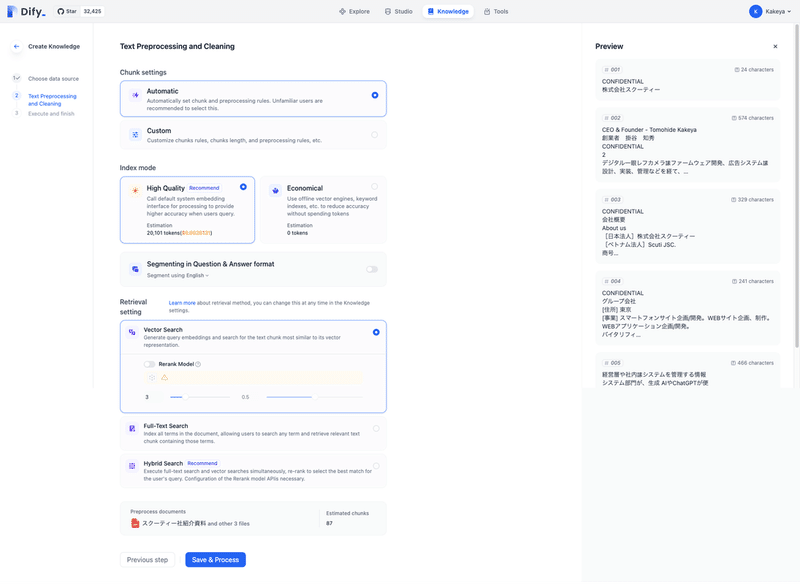
ドキュメントをアップロードしたら、そのドキュメントをどのような方法で検索するかという設定を行います。各設定の詳細は後ほど説明しますので、ここではとりあえず「Recommend」と書かれているものを選んでおきます。

ただし、「Hybrid Search」を設定するためには「Rerank」というものができる必要があり、Rerankができるモデルを予めインストールしておく必要がありました。
モデルの追加は右上の設定から画像のようなポップアップが開きますので、「Model Provider」を選択します。
どのモデルでRerankができるかは、ラベル表示されているので、ラベルから判断できます。今回はCohereのモデルを選びました。

再度、先程のKnowledge追加画面に戻ると、Hybrid Searchの設定でRerankのモデルを選択できるようになっています。
先ほど追加したCohereのモデルのうち、multilingual-v3.0を選択します。
これでSaveすればKnowledgeが登録され、準備は完了です。
チャットボットを作成する

では、簡易的なRAGとして、先程作成したKnowledgeのドキュメントを参照して、質問に回答してくれるチャットボットを作っていきます。
上部メニューのStudioから「Create from Blank」を選択します。
テンプレートを使用せずに、0から作成するということです。

Chatbotを選択します。

すると、まっさらの状態からチャットボットを作成する画面が開きます。
「Context」というのが、チャットボットに与える前提知識になります。ここで、チャットボットに検索させるドキュメントを登録します。
画像内の「Add」ボタンを押します。

すると、登録済みのKnowledge一覧が表示されますので、検索させたいドキュメントを登録しているKnowledgeを選択します。ちなみに、複数のKnowledgeを選択可能です。

もう一つ設定しておきます。
画面下部の「ADD FEATURE」をクリックします。

するとポップアップからいくつかの追加機能を選択できます。
ここでは、「Citations and Attributions」を選択します。これをONにしておくと、チャットボットの回答に参照したドキュメントが表示されるようになって便利です。
これですべての準備完了です!簡単!

では早速、適当な質問をしてみましょう。
今回は、弊社の営業資料をKnowledgeにアップロードし、弊社が提供するサービスについて質問してみました。適当な質問をしてもほしい回答を返してくれました。また、参照元のドキュメントも正しいものを表示してくれました。
全くコードを書かずにRAGができてしまいます。すごすぎですね!
文書検索の設定について

さて、先ほどKnowledgeを登録する際に適当に設定した部分ですが、実際はどういう意味なのでしょうか?画面上の説明だと分かりづらいので、公式ドキュメントで調べてみました。
Index modeについて
公式ページのこちらのページを参考にしました。
High QualityとEconomical
High Qualityを選ぶと文書検索精度があがるので、高精度の検索を実現したい場合は、High Qualityを選択刷ることになります。
説明が少なくてイマイチ不明確なのですが、High QualityのほうはOpenAIのAPIを使用し、Economicalの方はローカルでインデックス化やベクトル検索の処理を完結するため、Economicalを選択するとOpenAIのAPIにかかるトークン費用がかかりません、ということのようです。
Segmenting in Question & Answer format
こちらも公式ページの情報が少ないので非常に理解が難しかったです。結論としてはこちらもONにしたほうが検索精度が向上するようです。
すこし前のバージョンでは英語と中国語にしか対応していませんでしたが、最新バージョンでは日本語にも対応していたので、ONにしておくのが良さそうです。
で、何が違うのかですが、、、下記の処理内容の違いがあるようです。
◉Offの場合(Question to Paragraph)
文書内の文章を複数のParagraph(いわゆる段落ではなく、おそらく意味をなすくらいの長さのひとかたまりの文章単位と思われます)に分割し、ユーザーからの質問と類似性の高いParagraphを抽出するという方法。
◉Onの場合(Question to Question)
文書内の文章を複数のParagraphに分割するところまでは同様ですが、同時に、各Paragraphに関するQ&Aのペアも作るそうです。ユーザーから入力された質問と類似性の高い「質問」を検索し、その質問に対応する回答を返すという方法。

Retrieval Settingについて
以下の3つから選択できますが、結論としてHybrid Searchが精度が高いようなので、それを選ぶのが良さそうです。以下の説明には、こちらの公式ページの内容を参照しました。
Vector Search
テキストをベクトル(多次元の数値)に変換し、意味的な類似性を基に検索する方法。文脈を理解し、類似した意味を持つ文書を高精度で検索できます。意味的な類似性を重視するため、ユーザーの意図をより深く理解した結果が返されます。ただし、正確な単語一致が必要な場合は適さないことがあります。
Full-Text Search
文書内のすべての単語をインデックス化し、ユーザーのクエリと一致するテキストを検索する方法。単語の正確な一致に基づいて検索を行うため、特定のキーワードに対する精度が高いです。クエリと正確に一致する単語が含まれる文書を見つけやすいですが、文脈や意味的な類似性を考慮しないため、類似表現に対応できないことがあります。
文脈や意味合いの類似度で検索結果を出してもらいたい場合はVector Search、特定の単語の類似度で検索結果を出してもらいたい場合はFull-Text Searchを選択するのがいいということです。
ただ、実際のユースケースでは、文脈で検索したい場合もあるでしょうし、単語で検索したい場合もあるのが一般的でしょうから、どちらかを選ぶというのが難しそうです。そこで、両方の長所を活かす検索方法として、Hybrid Searchという手法が挙げられています。

Hybrid Search
Hybrid Searchは、Vector SearchとFull-Text Searchを組み合わせることで、双方の長所を活かします。
具体的な組み合わせ方(上記図参照):
Vector Search:まず、ユーザーのクエリをベクトルに変換し、意味的な類似性に基づいて関連する文書を検索します。
Full-Text Search:同時に、クエリのキーワードをインデックス化された文書から検索し、キーワード一致に基づいて関連する文書を検索します。
結果の統合:ベクトル検索とフルテキスト検索の結果を統合し、両方の結果から最適なものを選び出します。
Rerank
これら3つの検索方法でオプションとしてRerankというものを選択できます。検索精度向上のためには、これも有効にしたほうが良さそうです。
Rerankはまず、初期検索結果をセマンティックに評価します。これには、文脈の理解や意味的な関連性の評価が含まれます。初期検索結果を評価し、セマンティックスコアに基づいて順位を再配置します。これにより、ユーザーの意図に最も近い結果が上位に表示されるようになります。
Rerankにより、意味的に関連性の高い文書が上位に表示されるため、ユーザーの意図により適した結果が得られます。逆に、初期検索結果に含まれる関連性の低い文書が下位に配置されるため、ノイズが減り、精度が向上します。
最後に
最後までお読みいただき、ありがとうございます!
弊社では、LLM(大規模言語モデル)やアーキテクチャの選定、技術検証、生成AIを使用したプロトタイピングやシステム開発、お客様社内での啓蒙活動等を対応させていただく「生成AIコンサルティング」サービスを提供しています。
また、業務利用できるChatGPTのような仕組みである「セキュアGAI」も提供しています。
この記事は私が経営する株式会社スクーティーのコーポレートブログの下記記事を焼き直したものです。
この記事が気に入ったらサポートをしてみませんか?