
RPAアシロボでWeb巡回をしよう!

みなさん、こんにちは。株式会社カイラススタイルです。
▼RPAアシロボでWeb巡回をしよう!
最近、Webを巡回しながらデータを取得していくことが多かったので
やり方をここに書いていこうと思います。
サンプルシナリオはこちら
↓ ↓ ↓
【Web巡回サンプルシナリオ】
細かい部分はシナリオを見ていただくとして、重要なポイントを下に書いていきます!
▼1.Xpathの法則性を見つける!
今回は例として、Yahoo!ニュースのトピックスの見出しタイトルを
順番に巡回して取得していく場合を解説していきます。
https://news.yahoo.co.jp/topics/top-picks
重要なのは「Xpathの法則性」を見つけることです。
例えばニューストピックスのひとつめのタイトルのXpathは
/html/body/div[1]/main/div/div[1]/div/div/div[3]/ul/li[1]/a/div[2]/div[1]
ふたつめのタイトルのXpathは
/html/body/div[1]/main/div/div[1]/div/div/div[3]/ul/li[2]/a/div[2]/div[1]
みっつめのタイトルのXpathは
/html/body/div[1]/main/div/div[1]/div/div/div[3]/ul/li[3]/a/div[2]/div[1]
となっています。(2021年4月現在)
このXpathをよーく見比べてみると後ろから3番目の数字が
ひとつずつ増えているのがわかります。
まずこれが1つめのポイントです!
▼2.Xpathの中に変数を設定!
次に「記憶」のなかにある「文字」を選択して、数字の「0」を入れます。
データ参照IDは「巡回用」という名前に設定します。

次に見出しタイトルを取得するための「HTML文字列抽出」を設定します。
先ほどのXpathで数字が増えていた部分に代わりに変数を入れます。
/html/body/div[1]/main/div/div[1]/div/div/div[3]/ul/li[${巡回用}]/a/div[2]/div[1]
そしてそれをHTMLターゲットに設定!
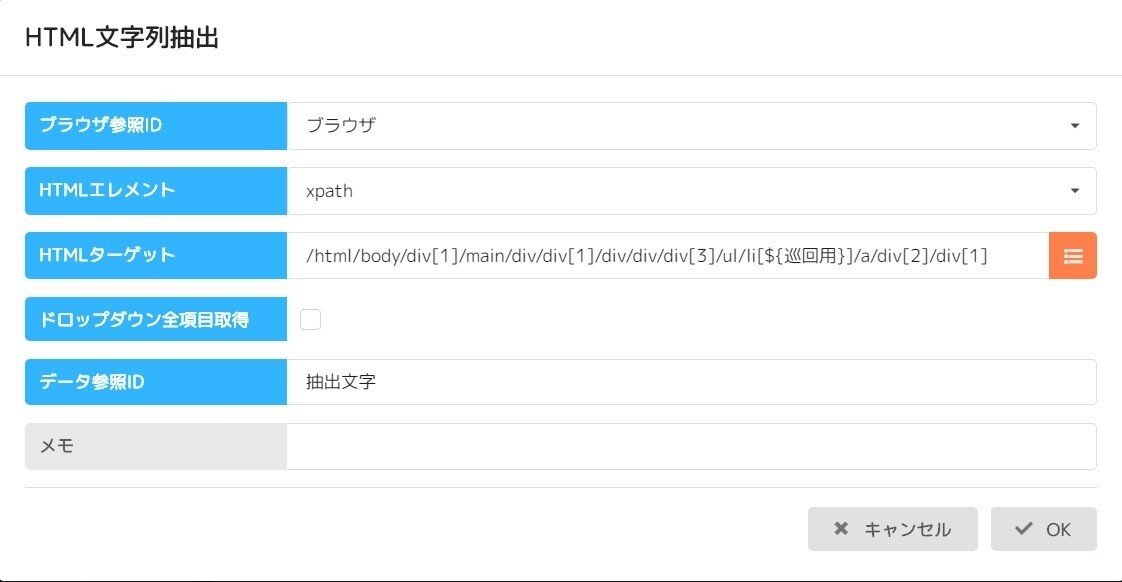
これが2つめのポイントです!
▼3.「計算」と「繰り返し」でXpathの中の数字を増やす!
最後に「巡回用」の数字をひとつずつ増やしていく設定をします。
「記憶」→「計算」で、数値1は先ほど設定したデータ参照ID「巡回用」を選択。
演算子は「+」、数値2は「1」を設定し、データ参照IDを同じ名前の「巡回用」に設定します。

これを繰り返しの中に入れることで、Xpathの中に設定した変数が1ずつ増えて行きます。
これが3つめのポイントです。
「Xpathの規則性を見つけて、それにあわせて計算と繰り返しを設定する」
巡回の基本的な設定方法はほとんどこれです。
サンプルシナリオではメモ帳にトピックスのタイトルを貼り付けるだけでしたが
これを参考に、Excelにデータを順番に貼り付けていくということも可能です。
注意点として、Xpathは変更されることがあるということです。
Xpathが変更された場合は設定をし直す必要があるので、ご注意ください。
それでは!
RPAアシロボ、一か月無料体験はこちらから!
一か月無料体験版お申込み
この記事が気に入ったらサポートをしてみませんか?