dbtを使って特徴量の生成からBigQuery MLで学習までをやってみた

dbtは大雑把に言えばjinja+SQLでデータのモデリングをするためのツールです。
ETLのTransformの部分の機能を担い、SQL+Jinja Templateで簡単にSQLの機能を拡張してくれる優れものです。
また、FROM句で{{ref(“filename”)}}のようにファイル名を指定することで、自動で依存関係を把握してくれて実行してくれることが一番の注目ポイントかなと思います。
この、DBTの機能を使ってGoogle Cloud shell上でBigQueryのPublic DatasetからBQMLでモデルを学習するところまでを試して見ました。
作成には以下のような手順でやっています。
0. dbtをインストールしてBQへアクセスするためのプロファイル情報(profile.yml)を作成
1. DBTのプロジェクト情報(dbt_project.yml)を作成
2. データをモデリングして、訓練に使う特徴量のデータセットを作成
3. BQMLを訓練するSQLを用意
0. dbtをインストールしてBQへアクセスするためのプロファイル情報(profile.yml)を作成
基本的にはpipを実行するだけで、インストールできます
pip install dbtインストールページより、自身環境に合わせてインストールしてください(cloud shellで実行するときはsudo pip install -I dbtで実行しないとdbtコマンドを認識してもらえませんでした)
Mac
Ubuntu
インストールが完了したら、以下のコマンドでプロジェクトを作りましょう。
dbt init dbt_bqmlコマンドを実行すると、実行したディレクトリ以下にdbt_bqml, ホームディレクトリ以下に .dbtディレクトリが作成されています。
dbt_bqml
├ analysis
├ data
├ macros
├ models
├ snapshots
├ tests
└ dbt_project.yml
~/.dbt
└ profile.ymldbtからBigQueryにアクセスするためには.dbt/profile.ymlを編集して設定する必要があります。
詳細な設定値はConfigure Your Profile を参考にしてもらうとして、私は以下のように設定しました。
default: # profile-name
target: dev
outputs:
dev:
type: bigquery
method: oauth
project: "{{ env_var('GOOGLE_CLOUD_PROJECT') }}" # 環境変数で設定されているプロジェクト名を利用する
dataset: iowa_liquor_sales
threads: 2
timeout_seconds: 600
location: US
priority: interactive
retries: 3ここで、GCPのプロジェクト名はdbtの機能として環境変数に設定されている値を使っています。”{{ env_var(‘変数名’)}}”で宣言することで利用することができます。
1. DBTのプロジェクト情報(dbt_project.yml)を作成
dbtにはデータをモデリングしてくれるだけでなく、スキーマごとのテストを作成してくれる”test”, 分析のような重たい処理に対して実行はせずにクエリのみを生成してくれる”analysis”, プロジェクト内にわたって共通処理を保存できる”macro”などの様々な機能があります。
これらの機能についてSQLで実装をするのですが、そのSQLを格納しているディレクトリのパスを指定することで利用することができます(defaultの設定値もあります)。BQMLの訓練をするために2つの工夫をしています。
1. データセットの作成時に、BigQueryのパブリックデータからテーブルをコピーしてくる。
2. データセットの作成後に、BQMLのクエリを動かす
この2つの前処理・後処理をするためにマクロ機能を利用してるのですが、どのマクロを定義するかをdbt_project.ymlに記載します。
“on-run-start”で前処理のマクロを指定し、”on-run-end”でBQMLの訓練のマクロを指定します。
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models
name: 'liquor_sample'
version: '1.0.0'
config-version: 2
# This setting configures which "profile" dbt uses for this project.
profile: 'default'
# These configurations specify where dbt should look for different types of files.
# The `source-paths` config, for example, states that models in this project can be
# found in the "models/" directory. You probably won't need to change these!
source-paths: ["models"]
analysis-paths: ["analysis"]
test-paths: ["tests"]
data-paths: ["data"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
target-path: "target" # directory which will store compiled SQL files
clean-targets: # directories to be removed by `dbt clean`
- "target"
- "dbt_modules"
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
on-run-start:
- "{{ cp_liquor_data() }}"
on-run-end:
- "{{ train_dnn() }}"
# In this example config, we tell dbt to build all models in the example/ directory
# as tables. These s ettings can be overridden in the individual model files
# using the `{{ config(...) }}` macro.
models:
liquor_sample:
+materialized: table
store_aggregation:
max_price_sales:
- description: 店舗x商品で最高価格のものを集計する
vars:
bq_public_path: bigquery-public-data.iowa_liquor_sales.sales基本的にはデフォルト値をほとんどそのまま使っていますが、上述した前処理・後処理のマクロの他に、model内に記載したデータモデルについてテーブルを作成するように指定してます。また、Jinja Templateのレンダリングで使う定数を指定しています。
2. データをモデリングして、訓練に使う特徴量のデータセットを作成
ここでは、SQLを記載します。SQLはある程度のまとまりになるようにファイルやモジュール単位で分割することで読みやすいデータモデルを作ることができます。今回はこんな感じで分けています。
集計作業とBQMLのデータセットの2つに分けています。集計作業は、もうちょいと細かい単位で作成しています
model
├ ml_datasets
│ └ datasets.sql
├ store_aggregation
│ ├ category_ranks.sql
│ ├ store_monthly_revenues.sql
│ ├ last_year_revenue.sql
│ └ vendor_ranks.sql
└ monthly_revenue.sqlここでは、datasets.sqlについて取り上げます。
以下がそのSQLになります。
SELECT
store_number,
sales_year,
sales_month,
top_vendor,
top_category,
last_year_revenues,
monthly_revenues,
FROM {{ref("store_monthly_revenues")}}
LEFT JOIN {{ref("last_year_revenue")}}
USING (store_number, sales_year, sales_month)
LEFT JOIN {{ref("category_ranks")}}
USING (store_number, sales_year, sales_month)
LEFT JOIN {{ref("vendor_ranks")}}
USING (store_number, sales_year, sales_month)注目すべきポイントはFROM句の{{ref(“file_name”)}}という記載になっているところです。FROMで指定するテーブル名についてはエイリアスを指定することができます。各SQLの実行結果に対してエイリアスがつき、デフォルトのエイリアス名ではファイル名が指定されます。
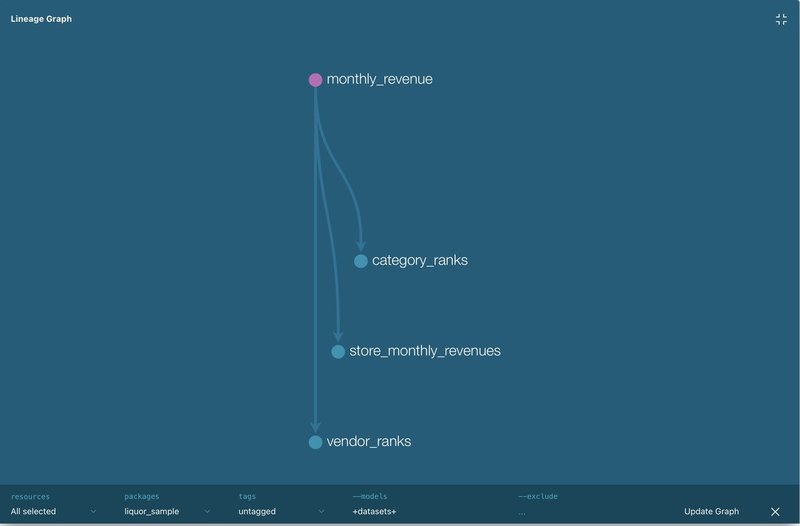
それぞれのエイリアスの参照関係を自動で解析してくれるので、実行時に自動的に順番で実行してくれます。こんな感じで依存関係を可視化することもできます。
3. BQMLを訓練するSQLを用意
macroディレクトリの中に、train.sqlを用意します。
{%macro macro_name() %} ... {% endmacro %}のブロックを作ることで、他のモデルで利用できるmacroを作成することができます。作ったmacroはモデルの中だけではなく、前処理や後処理としても利用することができます。なので、データセットを作成した後処理のマクロとして、BQMLを訓練するSQLを用意してあげることで、データセット作成後に自動で訓練を回すことができます。
{% macro train_dnn() %}
CREATE MODEL IF NOT EXISTS{{target.schema}}.dnn_regressor
OPTIONS(
MODEL_TYPE = "DNN_REGRESSOR",
BATCH_SIZE=128,
ACTIVATION_FN="SELU",
DROPOUT=0.1,
HIDDEN_UNITS = [128, 64, 32, 16],
EARLY_STOP=TRUE,
INPUT_LABEL_COLS=["monthly_revenues"]
)
AS
SELECT *
FROM {{ref("datasets")}}
{% endmacro %}macrosの中のsqlでもmodelsの中のsqlと同じようにFROM句にエイリアスを用いることができます。{{target.schema}}はprofile.ymlに記載されているtargetの中のschema情報を指しています。BigQueryで実行される場合には、ここはデータセット名になります。
4. 実行する
dbt_project.ymlと同じ階層内でdbt runを実行することで、models内のsqlが自動で実行され全てのsqlの実行完了後にマクロで指定したBQMLのtrainが実行されます。こんな感じでログが出ると思います(iPad+cloud shellで実行しているのでうまくコピペできず、表記が崩れています)
$ dbt run
Running with dbt=0.17.2
Found 6 models, 3 tests, 0 snapshots, 0 analyses, 150 macros, 2 operations, 0 seed files, 0 sources
20:18:01 |
20:18:01 | Running 1 on-run-start hook
20:18:01 | 1 of 1 START hook: liquor_sample.on-run-start.0...................... [RUN]
20:18:02 | 1 of 1 OK hook: liquor_sample.on-run-start.0......................... [[32mCREATE TABLE (19008336)[0m in 1.33s]
20:18:02 |
20:18:02 | Concurrency: 2 threads (target='dev')
20:18:02 |
20:18:02 | 1 of 6 START table model iowa_liquor_sales.monthly_revenue........... [RUN]
20:18:41 | 1 of 6 OK created table model iowa_liquor_sales.monthly_revenue...... [[32mCREATE TABLE (6766687)[0m in 38.25s]
20:18:41 | 2 of 6 START table model iowa_liquor_sales.store_monthly_revenues.... [RUN]
20:18:41 | 3 of 6 START table model iowa_liquor_sales.category_ranks............ [RUN]
20:18:49 | 2 of 6 OK created table model iowa_liquor_sales.store_monthly_revenues [[32mCREATE TABLE (131648)[0m in 8.41s]
20:18:49 | 4 of 6 START table model iowa_liquor_sales.vendor_ranks.............. [RUN]
20:19:06 | 3 of 6 OK created table model iowa_liquor_sales.category_ranks....... [[32mCREATE TABLE (2950856)[0m in 25.00s]
20:19:06 | 5 of 6 START table model iowa_liquor_sales.last_year_revenue......... [RUN]
20:19:10 | 5 of 6 OK created table model iowa_liquor_sales.last_year_revenue.... [[32mCREATE TABLE (131648)[0m in 4.21s]
20:19:15 | 4 of 6 OK created table model iowa_liquor_sales.vendor_ranks......... [[32mCREATE TABLE (2485895)[0m in 26.18s]
20:19:15 | 6 of 6 START table model iowa_liquor_sales.datasets.................. [RUN]
20:19:52 | 6 of 6 OK created table model iowa_liquor_sales.datasets............. [[32mCREATE TABLE (68684603)[0m in 36.76s]
20:19:52 |
20:19:52 | Running 1 on-run-end hook
20:19:52 | 1 of 1 START hook: liquor_sample.on-run-end.0........................ [RUN]
20:19:53 | 1 of 1 OK hook: liquor_sample.on-run-end.0........................... [[32mOK[0m in 1.39s]
20:19:53 |
20:19:53 |
20:19:53 | Finished running 6 table models, 2 hooks in 113.08s.
[32m] Completed successfully[0m]
Done. PASS=6 WARN=0 ERROR=0 SKIP=0 TOTAL=6実行完了後にBigQueryのデータセット内にdnn_regressorという名前でモデルが出来上がっていると思います。
終わりに
今回の目的はdbtを使ってBQMLを動かすことだけなので、このMLモデルが使い物になるかどうかという点は一旦無視しています。
dbtにはデータモデルのスキーマを定義してテストをしたりドキュメント生成を行ったりする機能や、profile.ymlやdbt_project.ymlを環境ごとに指定することもできるので、これから本番環境とかにも使われてくるOSSなのではないかなと思っています。
この記事が気に入ったらサポートをしてみませんか?