【備忘録】SELECTでデータを抽出する

◆ 全てのカラム&特定のカラムを抽出する方法

・16行目では、全てのレコードが抽出されている。
* は全てのカラムを意味している。
・17行目のように、特定のカラムだけを抽出させたい場合には、
カンマ区切りで指定してあげればOK!

↑ では、id と message だけを posts から抽出している。
◆ 条件に合うレコードだけを抽出する方法

・16行目では、likes が 10 以上の条件だけ抽出している。
17行目では、message が 'Danke' じゃないレコードを抽出している。

コンパイル成功!
◆ 条件を組み合わせる方法(AND編)

・16行目では、likes が 10 以上、かつ 20 以下のレコードを抽出している。
また、〇以上、〇以下という条件の場合に限り、特殊な書き方もできる。
・17行目では、BETWEEN というキーワードを使うことで、
16行目と全く同じ意味にすることも可能!
・18行目では、BETWEEN の条件を反転して書いている。

BETWEEN の条件が反転して表示されている。
◆ 条件を組み合わせる方法(OR編)

・16行目では、likes が 4 もしくは 12 のレコードを抽出している。
また、= で判定する条件を OR で繋いだ場合、特殊な書き方もできる。
・17行目では、IN というキーワードを使うことで、
16行目と全く同じ意味にすることも可能!
・18行目では、IN の条件を反転して書いている。
◆ LIKEと%で文字列を抽出する方法(前方一致編)

・16行目では、't' から始まるメッセージだけを抽出している。
・17行目では、BINARY というキーワードを使うことで、
大文字小文字が区別されるため、小文字の 't' から始まるレコードだけが
抽出される。

コンパイル成功!
◆ LIKEと%で文字列を抽出する方法(後方&部分一致)

・16行目では、'su' で終わるレコードを抽出している。
17行目では、'i' が含まれるレコードが抽出される。

コンパイル結果
◆ LIKEと_で文字列を抽出する方法

・16行目では、massage の 3 文字目が a のレコードだけを抽出している。
17行目では、massage の 3 文字目が a 以外のレコードが抽出される。

LIKEの条件が反転して表示されている。
◆ %と_の文字自体を抽出する方法

・16行目では、真ん中の % がその文字自体を表現する場合は、
\ を % の前に付けることで、% を含むレコードだけを抽出している。
17行目では、同様に _ が入ったレコードだけが抽出される。
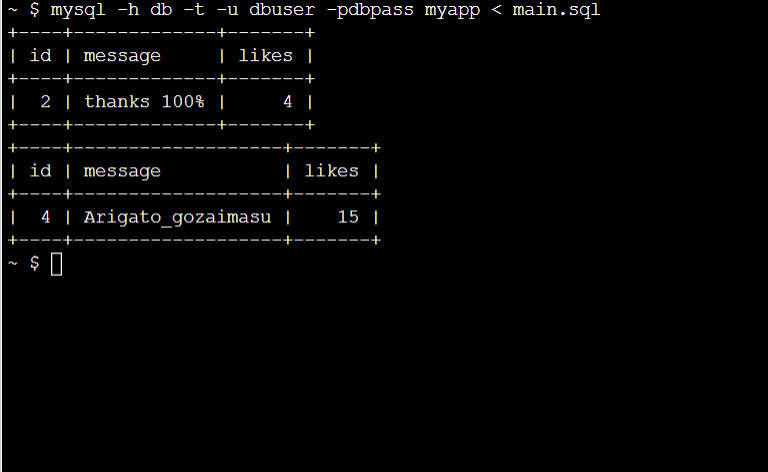
コンパイル成功!
◆ NULLのレコードを抽出する方法
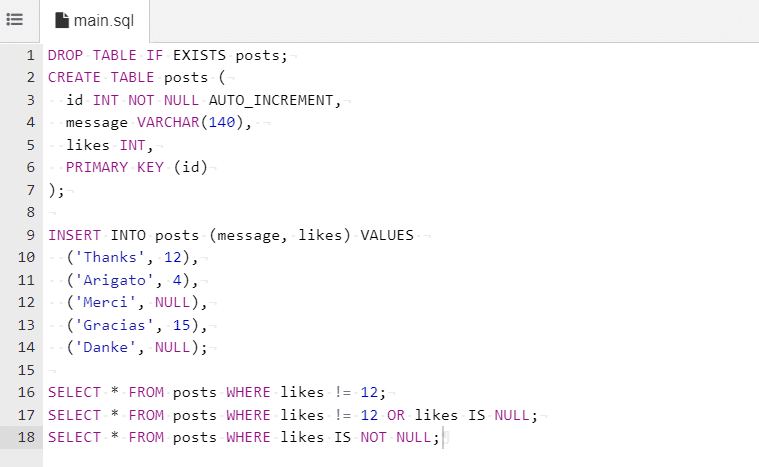
・16行目では、12 以外と NULL 以外のレコードを抽出している。
17行目では、NULL も含めて抽出される。
18行目では、NULL 以外のレコードが抽出される。

17行目の条件が反転して表示されている。
◆ 抽出結果を並び替える方法(小さい順、大きい順)

・16行目では、likes を小さい順で並び替えをしている。
17行目では、DESC というキーワードを使うことで、
likes を逆順(大きい順)で並び替えられる。

小さい順、大きい順に並び替えられている。
◆ 抽出結果を並び替える方法(アルファベット順)

・16行目では、likes をアルファベット順で並び替えをしている。

アルファベット順に並び替えられている。
◆ 特定の件数を抽出する方法(上位件数、除外件数)

・16行目では、likes の上位 3 件だけを抽出している。
17行目では、OFFSET というキーワードを使うことで、
ikes の上位 2 件を除外して、その後 3件が抽出される。

17行目での最終的に 3 件が抽出されている。
◆ 関数で文字列の一部を切り出す方法

・16行目では、massage と massage の 3 文字目以降を切り出ししている。
17行目では、massage と massage の 3 文字目から 2 文字分を
切り出ししている。
18行目では、- の値を与えることで、末尾から 2 文字分を抽出している。

それぞれ正しい結果で表示されている。
◆ 関数で文字列を連結する方法

・16行目では、連結したい値をカンマ区切りで渡すことで、
文字列を連結している。

◆ 文字数の長さを抽出する方法

・16行目では、massage と massage の文字数を抽出している。
17行目では、massage と massage の日本語の文字数も抽出している。

LENGTH()の場合に限り、日本語の文字数がおかしくなるため、
CHAR_LENGTH()というキーワードを使って、日本語の文字数を抽出する。
◆ ざっくりまとめると・・・
① 全てのカラムを抽出→ *
特定のカラムを抽出→ カンマ区切りで指定
② 条件に合うレコードだけを抽出→ WHERE
③ 条件を組み合わせる→ AND なおかつ
OR もしくは
④ 0 文字以上の任意の文字を抽出→ %
大文字小文字を区別して抽出→ BINARY
⑤ 任意の 1 文字を抽出→ _
⑥ %と_の文字自体を抽出→ \%、\_
⑦ NULL のレコードを抽出→ IS NULL
NULL 以外のレコードを抽出→ IS NOT NULL
⑧ 抽出結果を並び替える→ ORDER BY 小さい順
DESC 大きい順
カンマ区切りで指定 アルファベット順
⑨ 特定の件数を抽出→ LIMIT 上位
OFFSET 除外
⑩ 文字列の一部を切り出す→ SUBSTRING()
⑪ 文字列を連結する→ CONCAT()
⑫ 文字数の長さを抽出する→ LENGTH()
日本語の文字数の長さを抽出する→ CHAR_LENGTH()
この記事が気に入ったらサポートをしてみませんか?