
サービス立ち上げで学んだ「RDB設計で簡単にやってはいけないこと」8選

普段の業務でとあるサービスの開発を立ち上げフェーズから携わらせてもらっており、かつ最近嬉しいことに徐々に利用者が増えてきました!👏
そういった立ち上げ時期〜成長期に携わっていると(エンジニアのありがたい成長痛ですが)、
RDBの設計を変更しにくくなったり、機能追加に伴ってRDBの設計自体が複雑化するため、設計を見直したり深く考える機会も増えてきます。
そんな時期を経験しているからこそ、DB設計で学んだこともたくさんあります。
今回はたくさんの学びの中から絞って、
「サービス立ち上げで学んだ、RDB設計で簡単にやってはいけないこと8選」と題してまとめました。
※ これは必ずしも「やってはいけない」ということではありません。
「導入の際は慎重に検討した方がいいのではないか」と思っていることを書いております。
※ 私はMySQLを業務で使用しております。もし他のRDBだと違う状況になることなどありましたら教えていただけると幸いです。
RDB設計で簡単にやってはいけないこと8選
1. 過去のデータを上書いてしまう
(この項目は例で説明します)
例
代行サービスがあり、以下のDB設計だったとします。
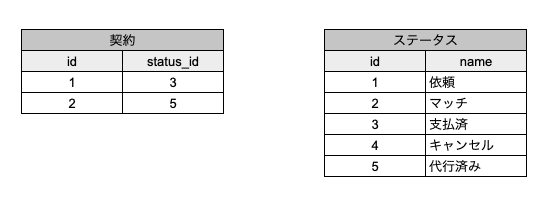
この2つのテーブルだけで管理しようとすると、以下の状況が発生してしまいます。
ステータスが「キャンセル」の契約の場合、以下の2つの可能性がある
・「マッチング」 => 「支払い済み」=>「キャンセル」
・「マッチング」 =>「キャンセル」
=> ユーザーがお金を支払ったかどうかのデータが打ち消され、事業者は返金する必要があるのか分からなくなってしまった
考察
この問題は過去のデータを安易に上書いてしまったことで発生しています。
こういったケースの場合、各契約のステータスの変更履歴を保存したり、ステータスをもっと細かく分けるなどの対応で避けられますが、
いずれにせよデータを上書きするだけでなく追加対応が必要になってきます。
過去のデータを上書きする場合は、上書き前のデータの重要性を考慮し、保存しておく必要はないか考えましょう。
また、たとえサービスの要件として必要なかったとしても、ユーザーからのお問い合わせやサービス障害などの非常時にデータが必要になる場合もあるので注意しましょう。(特に決済などの重大なデータの場合)
まとめ
・過去の事実を上書きしていいかは、サービスの要件だけでなく上書き前のデータの重要性を考慮して決める
・特に決済などの重要なデータは、履歴テーブルやログなどを残して、非常時などに確認できる仕組みも検討する
2. INDEXを正しく利用できていない
「WHERE条件で指定するから、INDEXを設置しておけばパフォーマンスを上げてくれる」と思いがちですが、INDEXを設置したからといって必ずしもパフォーマンスが向上するとは限りません。
MySQLはB Tree Indexを使っているので、その特徴を知っていることが大切です。簡単にいくつかINDEXが有効利用されないパターンを紹介します。
INDEXが利用されない例
・データの種類が少ないカラムに対してインデックスを設置している
/* 1(男性)、2(女性)のみのデータの場合、検索結果が多くなってしまい、INDEXを有効利用できない */
SELECT * FROM users where gender = 1
・検索条件にLIKE検索などを用いている
/* 前方一致: INDEXは利用される */
SELECT * FROM users where name like "iwamu%"
/* 部分一致: INDEXは利用されない */
SELECT * FROM users where name like "%iwamu%"
/* 後方一致: INDEXは利用されない */
SELECT * FROM users where name like "%iwamu"・検索条件にカラムを使っていない
/* price * 0.8 の値の結果が計算対象になるため、INDEXは利用されない */
SELECT * FROM contract where price * 0.8 > 20000
/* priceの値の結果が計算対象になるため、INDEXが利用される */
SELECT * FROM contract where price > 20000 / 0.8
また、INDEXを設置しすぎると、データの登録や更新が遅くなってしまうこともあります。
かといって設置したINDEXを削除しようと思っても、削除したことによるパフォーマンス遅延を予測しづらく実行が難しかったりします。
なので安易な予測でINDEXを設置するのではなく、パフォーマンスを定期的に監視しておき、必要になったらINDEXの設置を行う運用でもいいかもしれません。
まとめ
・INDEXを設置しても必ずパフォーマンスが上がるわけではない
・INDEXが利用されるようにSQLを組み立てる
・効果が発揮されやすいカラムにINDEXを設置する
・安易な予測でINDEXを設置するのではなく、継続的なモニタリングを通して必要と判断した場合にINDEXを設置する
3. JSON型を取り入れる
いくつかのRDBがJSONデータ型をサポートしていますが、JSON型の導入にも注意が必要です。
メリット
・JSONそのものに対応している
・スキーマレスにデータを保存できる
デメリット
・必須属性の指定やデータの整合性が取りづらい
・JSONをサポートする関数や演算子を使うことが増え、検索などのSQLが複雑化しやすい
JSON型の導入に適した用途の1つに、外部APIのレスポンスを保存しておくことが挙げられます。外部APIのレスポンス仕様は全て把握しきれない場合もあり、スキーマレスかつJSON型のまま保存できるメリットを生かすことができます。
例えば、外部の決済システムを利用する場合を考えてみます。
決済履歴を保存しておく場合、履歴のテーブルにAPIレスポンスのJSONを格納しておくカラムを作っておくことは有効的かもしれません。
まとめ
・JSON型の導入は柔軟にデータを保存できるが、デメリットも多いので導入は慎重に検討しよう
4. 柔軟性を意識しすぎる
DBの柔軟性を意識したにも関わらず、返って多くの負債を残してしまうことがあります。
今回は1つの例でEAVパターンをあげます。複数の参考書でアンチパターンとして取り上げられており、私自身も安易に設計しそうになったパターンです。
※ このパターンが必ずしも悪いというわけではありません。その設計パターンに至った背景を知っておくことが大切です。
EAV(Entity Attribute value)
先ほどの代行サービスで例えると以下のテーブル例です。
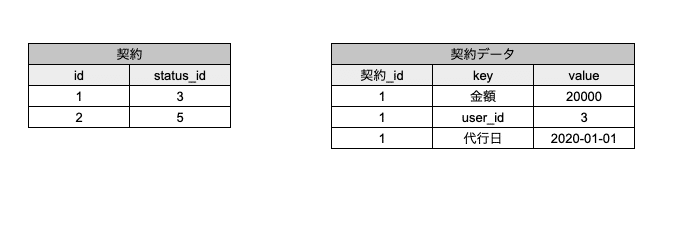
keyにデータの属性名を、valueに属性値を保存しています。
あらゆるデータをKeyValue形式のように保存できるので、柔軟性が高いメリットがありますが、逆に以下のように多くのデメリットもあるので、導入は慎重に行いましょう。
EAVのデメリット
・必須属性を設定できない
・データの型やNOT_NULLなどの制約を指定できない
・他のデータと関連づけるのが難しい
・「keyの文字列が"user_id"の行を探し、valueにある数字とユーザーテーブルを結合し..」
・データとの整合性を確認することが難しい
・「このkey、契約ID1の場合にはあって2にはないけどいいのだろうか..」
まとめ
・アンチパターンはどのようなものがあるか学習しておこう
・柔軟性を意識しすぎるのではなく、デメリットもないか考えよう
5. DBの設定周りを確認しないこと
DBの設定は、サービスを運用を始めると変更しにくい割に重要な設定項目がいくつかあるので、あらかじめ調べて反映させておくことが大切です。
私の実例になりますが、
MySQLのGROUP_CONCAT関数で取得できるデータにバイト数制限があるのを知らずに使おうとしたことがありました。その結果データが多いと途中でデータが切れてしまい、バグを生み出すことにも繋がりました。(QA環境で気づけたのが幸い)
まとめ
・DBの設定には重要な項目がいくつかあるので、設定できるパラメータを知っておこう
・サービス稼働後の設定変更は難しいので、サービス稼働前に設定を確認しておこう
6. パフォーマンスのために複雑なクエリを取り入れること
クエリが複雑になればなるほど、他のエンジニアが理解しにくいものになり、メンテナンスコストがかかってしまいます。これは、「スパゲッティコード」と考え方が似ていると思います。
解決する方法の1つですが、問題の前提部分を把握するといいかもしれません。
RDBの設計が複雑だった前提があり、設計を改善すれば済んだり、
そもそもパフォーマンスが求められている前提はなく、2~3回のクエリに分けてアプリケーション側で結合することで済む場合もあります。
まとめ
・複雑なクエリは、メンテナンスコストを大きくしてしまう
・その複雑なクエリは本当に必要か、なぜ必要なのか考え直そう
・(例) 実はそこまでパフォーマンスが求められていない
=> データをアプリケーション側で結合しても問題ないのではないか
・(例) テーブル設計が複雑だからクエリも複雑にせざるを得ない
=> テーブル設計を直すだけでクエリもシンプルにならないか
7. ビジネスロジックをDBの制約に持ち込むこと
DBの制約はデータや構造を守ってくれる大切な機能です。
しかし、ビジネスロジックは変更する可能性が高いことに対して、DBの制約の変更は容易にできるものではありません。
そのため、ビジネスロジックをDBの制約に持ち込んでしまうと、ロジックの変更に追従できず、柔軟性を失ってしまうことに繋がります。
DBの制約とビジネスロジックは以下の関係性も良いと思います。
DBの制約とビジネスロジックの関係の例
・ビジネスロジックの細かいデータ制御はアプリケーション側で行う
・DBの制約はデータ構造や不整合を防ぐための最低限の制約(外部キー制約、NOT_NULL制約、UNIQUE制約など)までに限定する
一方で、アプリケーションで不具合があってもDBの制約が最終的に防御壁になる理由から、DBの制約も細かく整えておく考えも理解できます。
しかし、それはサービスの柔軟性とのトレードオフに繋がるので、
特にまだサービスが成長フェーズで、ビジネスロジックが頻繁に変更されやすい場合は、慎重に検討した方がいいと思います。
まとめ
DBにビジネスロジックを持ち込みすぎて、柔軟性を失うことは避けよう。
8. 万が一のために論理削除すること
データを削除する際、「is_deleted」などの削除フラグを用いた論理削除を検討することもあると思います。しかし論理削除はデメリットも多く、簡単に導入すると負債が残りやすいです。
論理削除のデメリット
・クエリに「is_deleted = false」を毎回含める必要が出てくる
・削除フラグを考慮するためにカラムのunique制約が使えなくなったり、削除フラグとの複合INDEXを貼る必要がある。
・ビジネス要件の変更によって、is_deletedだけで表現できなくなる可能性がある
・(例) 記事の「公開」「下書き」「削除」
以上のようにデメリットは多いので、
「削除したデータを利用する可能性があるかもしれない」という盲目的な理由で論理削除をしておくのは控えた方がいいと思っています。
また、もしデータを残しておく必要があっても、別のテーブルに保存しておいたり、ログに残しておくなど、他の方法で実現できないかも検討しましょう。
まとめ
・論理削除のデメリットはたくさんある
・論理削除が必要と思った際は、他に要件を満たす方法はないか検討しよう
番外編. フレームワークに依存すること
これはDB設計というより、ORMとの付き合い方になります。
「マジックビーンズ」というアンチパターンがあり、ソフトウェアのアーキテクチャに悪影響をもたらします。これはRepositoryパターンやDDDと関連性がとても深いので、まとめて別の記事で紹介しようと思っています。
最後に
私はスタートアップで新規サービス開発を行っているので、
エンジニアの人員も多くかけられませんし、かといってサービス成長スピードを落とすわけにも行きません。
なので、ビジネスロジックの変更に柔軟に対応できること、メンテナンスコストを最小限にして開発に多くのコストをかけることのためにRDB設計はとても大切だと思っています。
これからもよりベターな設計を日々考えていきたいです。
読んでいただいた方にも参考になっていただければ幸いです。
PS. 参考になった本の紹介
20章の構成で多くのRDB設計アンチパターンがまとめられております。
筆者が実務で遭遇することが多かったアンチパターンを中心に書かれているそうで、実際に私が実際にRDB設計する際に陥りそうになったパターンや、経験の多いエンジニアの方からいただいたアドバイスの多くも書かれていました。
あらかじめこの本に目を通して知識として付けておくだけで、
将来自分の設計による負債を最小限に抑えたりできるかもしれないので、お勧めしておきます。
--------------------
いわむを気軽にフォローしてください♪
━━━━━━━━━━
■ブログ
https://kohei1116.hateblo.jp/
■Twitter
https://twitter.com/k_iwamu
━━━━━━━━━━
この記事が気に入ったらサポートをしてみませんか?