母集団と標本の関係性

前回記述統計学(主にグラフの見方)について紹介しました。今回の記事では推測統計学において重要な母集団と標本の関係性について深く掘り下げていきます。
0.統計学と機械学習の違い
では本題に入る前に一つ疑問に思っていたことを紹介します。統計学と機械学習の違いってなんだろう。特に推測統計学と機械学習は予測に焦点をおいているけど違いが分からない。それなら今機械学習がブームだし機械学習だけやっとけば良いんじゃない。などと一時期考えていました笑
確かにどちらもデータを予測することができますが目的が違います。これらをしっかり認識していないとやらかしてしまうかもしれません。違いについては以前簡単にまとめたので見てみて下さい。
✅統計学と機械学習の違い
— ジュキヤ@AI+英語勉強中 (@juki_DSandGM) October 1, 2020
ほぼ一緒
☑️目的
統計:データ構造明らかにして新たな知見を入手するため
機械学習:予測精度を高めたい時
✅用途
統計:ロジックが必要な場面(コンサルや提案など)
機械学習:ロジックは分からないが予測精度を高めたい場合#機械学習#統計学#DataScience
また次の記事をも参考になったので是非見てください。
Machine learning vs Statistics(こちらは英語版です)
結局、機械学習と統計学は何が違うの?(こちらの日本語版です。)
1.母集団と標本の関係について
統計調査を行う際の大きな調査方法を覚えていますか。標本調査と全数調査です。本来なら全数調査を行った方が正確なデータが取れるのでこちらの手法を取りたいところですが、母集団が非常に大きかったり、変動したりする場合は母集団全部を集めるなんてことは無理です。ここである一定の母集団から標本をサンプリングしてその標本の特徴から母集団を予測すると言うのが推測統計学です。
1-1.用語確認
・復元抽出:母集団から抽出した標本を使用したら、母集団に戻し再度サンプリングするを繰り返す方法。反対は非復元抽出法Pythonではreplace=Falseとすることで非復元抽出となる
・不偏分散:標本分散は標本のみを対象としているのに対して、不偏分散は標本の属する母集団全体を対象としている。
・大数の定理:標本の大きさが大きくなるほど、標本平均が母平均に近づく近づき方を表現した法則。
・中心極限定理:サンプルサイズが大きくなればなるほど、分布は正規分布になるという事(つまり分散が小さくなりより尖った正規分布になるという事)
1-2.標本から母集団を推測する
まず試し母集団から標本を抽出してみましょう。まず適当にarrayを作成して、これを母集団とします。抽出するためにはnumpyに含まれているrandom.choiceを使用します。母集団と、size(これはサンプルサイズのこと)を加えて実行したら抽出成功です。seedを固定していれば、7と9が出力されます。(今回は全てシード値1234で固定します。)
sample_data = np.array([3,4,7,5,3,5,7,9,5,4])
np.random.seed(1234)
np.random.choice(sample_data, size = 2, replace = False)では次に統計量について見ていきましょう。平均値と標準偏差をb集団と標本で見比べてみましょう。
np.mean(sample_data)
np.mean(np.random.choice(sample_data, size = 2, replace = False)
np.std(sample_data)
np.std(np.random.choice(sample_data, size = 2, replace = False)出力は以下の通りになります。
5.36(母平均)
8.0(標本平均)
1.8(母標準偏差)
1.0(標本標準偏差)
今回の場合サンプル数がかなり少ないので上記の統計量はあまり意味がないですが、次に実際に10万個のデータを用意してそれぞれの関係性を深めていきます。
母集団の作成はかなり簡単です。一つ目が平均値、二つ目が標準偏差です。今回は事前にランダムで平均値と標準偏差を求めたのでそれを入力します。これで平均5.36の標準偏差1.42の正規分布が完成しました。では次に描画していきましょう。
population = np.random.normal(5.36, 1.42, size = 100000)
sns.distplot(population, kde = False)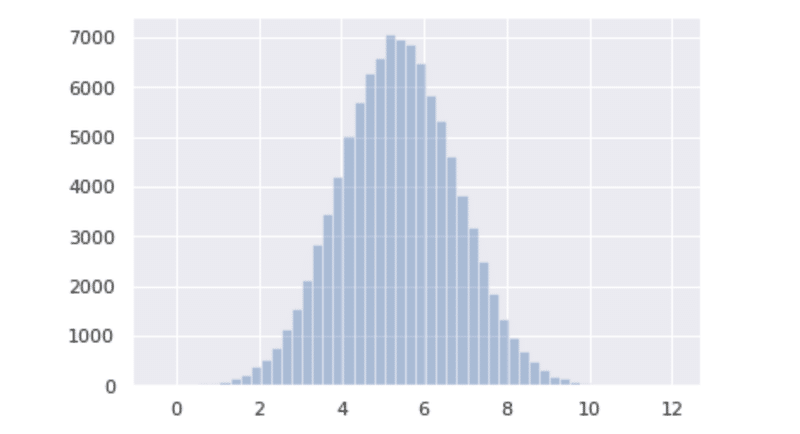
では作成した母集団からサンプリングをしてみましょう。今回はサンプルサイズを10とします。
sampling_result = np.random.choice(population, size = 10,
replace = False) では統計量を求めていきましょう。(実行画面は省きます)
5.36(母平均)
1.42(母標準偏差)
5.16(標本平均)
1.26(標本標準偏差)
標本の平均値はだいぶ母集団に近づきました。標準偏差はサンプルサイズが2でも10でも母集団よりも小さいですね。試しにサンプルサイズを大きくしてみたり、小さくしてみたりして下さい。
ここで次のような仮説が生じると思います。
・サンプルサイズを大きくすればするほど母平均に近づくのかもしれない
・標本平均は母平均よりも小さくなるのではないか。
ではこれらを検証していきましょう。
1-3.サンプルサイズが大きくなれば母平均に近づくのか
先程サンプル数を少し大きくしたことでグッと母平均に近づきました。では下記のコードを実行して検証してみます。サンプルサイズを100ずつ大きくしていきます。
size_array = np.arange(start = 10, stop = 100100, step = 100)
sample_mean_array_size = np.zeros(len(size_array))
for i in range(0, len(size_array)):
sample = population.rvs(size = size_array[i])
sample_mean_array_size[i] =np.mean(sample)
plt.plot(size_array, sample_mean_array_size, color = "blue")
plt.xlabel('sample size')
plt.ylabel("sample mean")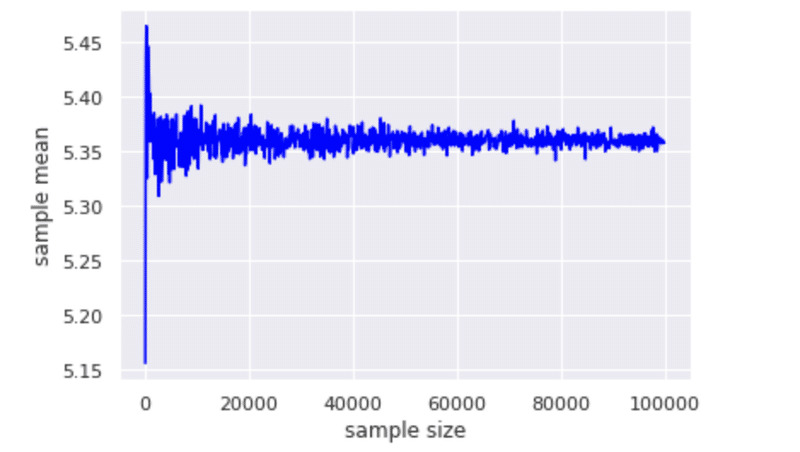
サンプルサイズが大きくなればなるほど母平均に近づいていますね。サンプルサイズが2万を超えた辺りからブレは小さくになっています。
1-4.サンプルサイズが大きくなると標本標準偏差は母標準偏差よりも小さくなるのか
次に標準偏差に注目していきましょう。2回ほどしか標準偏差を求めていないのですが、検証していきましょう。標準偏差が小さくなっていったら標本平均は信頼できる値になります。ではやっていきましょう。まず先にシミュレーションをやり易くするために関数を作っていきます。
def sample_mean(size, n_trial):
sample_mean_array = np.zeros(n_trial)
for i in range(0, n_trial):
sample = population.rvs(size = size)
sample_mean_array[i] = sp.mean(sample)
return sample_mean_arrayでは次にこの関数を使用してシミュレーションにかけていきましょう。
sample_mean_std_array = np.zeros(len(size_array))
np.random.seed(1234)
for i in range(0, len(size_array)):
sample_mean = sample_mean(size = size_array[i],
n_trial = 100)
sample_mean_std_array[i] = sp.std(sample_mean, ddof = 1)
plt.plot(size_array, sample_mean_std_array, color = "blue")
plt.xlabel("sample size")
plt.ylabel("mean_std value")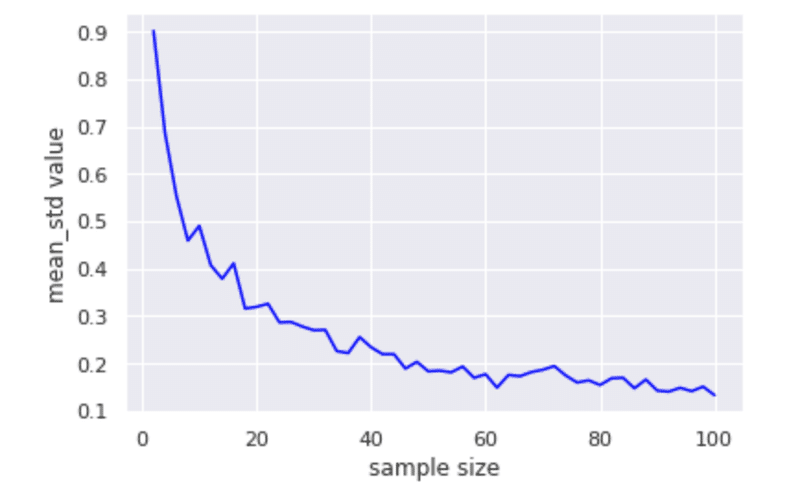
サンプルサイズが大きくなればなるほど標本標準偏差は小さくなっていますね。
1-5.サンプルサイズが大きいならば不偏分散は母分散に近い
まず母集団の分散を求めてみましょう。標準偏差が1.42だったので大体2.02位になります。では次に標本分散を求めてみましょう。
sample_var_array = np.zeros(10000)
np.random.seed(1234)
for i in range(0, 10000):
sample = population.rvs(size = 10)
sample_var_array[i] = np.var(sample, ddof = 0)
np.mean(sample_var_array)10000回繰り返して平均を求めて見ると、1.82となり本来の母分散よりずれていることがわかります。
ここで不偏分散という母集団に対して力を発揮する手法を使って再度求めてみましょう。
unbias_var_array = np.zeros(10000)
np.random.seed(1234)
for i in range(0, 10000):
sample = population.rvs(size = 10)
unbias_var_array[i] = np.var(sample, ddof = 1)
np.mean(unbias_var_array)同じように10000回繰り返して平均を求めてみた結果、2.018となり、ほぼ母分散と同じ値になりました。サンプルサイズ10でこれくらい近づいたのでサンプルサイズをさらに多くすれば、母分散に近くなると思います。では早速実行していきましょう。
size_array = np.arange(start = 10, stop = 100100, step = 100)
unbias_var_array_size = np.zeros(len(size_array))
np.random.seed(1234)
for i in range(0, len(size_array)):
sample = population.rvs(size = size_array[i])
unbias_var_array_size[i] = np.var(sample, ddof = 1)
plt.plot(size_array, unbias_var_array_size, color = "blue")
plt.xlabel("sample size")
plt.ylabel("unbias var")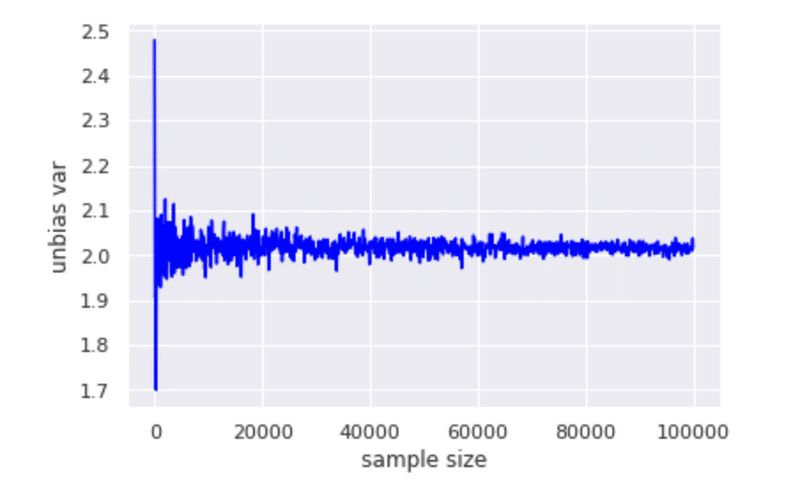
割と早めに母分散に近づいているのが確認できると思います。
以上で標本と母集団の関係性は終わりです。最後にまとめます。
2.まとめ
サンプルサイズが大きくなればなるほど....
・標本平均は母平均に近づく
・標本分散は小さくなり、つまりばらつきが小さくなる
・不偏分散は母分散に近づく
この記事が気に入ったらサポートをしてみませんか?