統計モデリングについて

1.統計モデルとは何か。
さて前回で統計学の基礎が終わった所で次に分析をしていきたい所ですが、一つとても重要な概念があります。それが統計モデリングです。これは現実を近似するために、単純化し、数学的に形式化された方法。なぜこの概念が必要なのでしょうか。それは世界が複雑な要因で構成されているからです。モデルの種類にもたくさんあります。
・数理モデル:現象を数式で表現したモデル
・確率モデル:数理的モデルの中で確率的な表現を伴うモデル
・統計モデル:データに適合するように構築された確率モデル
特に統計モデリングでは次にような際に役立ちます。
・母集団全てを入手することが困難な時
・過去の結果を基に予測をしたい時
・複雑な現象を説明したり、データの中にノイズなどが含まれていたりする時
モデリングと言う位だから私達自身でモデル作らないといけないのと思うかもしれませんが、必要ないです。モデルを作成するよりかはそのデータセットにあったモデルを選択する力が必要です。統計モデルと言われてもピンと来ないので代表的なモデルを紹介します。
1-2.統計モデルの種類
よく使われるのは回帰モデルで次のようなものがあります。
・線形回帰モデル
・一般化線形モデル
・ベイズ回帰モデル
・ニューラルネットワークモデル
・深層学習モデル
・ガウス過程回帰モデル
まだまだ沢山あります。次に紹介するのが生成モデルです。
・行列分解モデル
・混合モデル
・状態空間モデル
・トピックモデル
・確率的ブロックモデル
正直に言うとまだまだあります。ただ全部は紹介できないので(半分以上初見)、今回は回帰モデルの中の線形回帰モデルと一般化線形モデルのみ紹介します。
1-3.統計モデルの構成要素(用語確認)
・応答変数(従属変数):何らかの要因によって変化する変数のこと
・説明変数(独立変数):応答変数を構成する要素(複数可)
・パラメトリックなモデル:現象を単純化し、少数のパラメータ(説明変数)を使うモデルのこと。これによって解釈が容易になる。
・ノンパラメトリックなモデル:少数のパラメータを使わないモデルのこと。様々な現象を表現しやすくなるが、推定や解釈が難しくなる。
・線形モデル:応答変数と説明変数の関係に線形(直線である)の関係のみを認めたモデル
・係数(重み):
・Nullモデル:説明変数が入っていないモデルのこと。
・情報量規準:モデル選択を行う方法。これを使用してモデルの良さを評価する。例として赤池情報量規準(AIC)がある。AICは小さければ小さいほどよりモデルとなる。
2-1.線形回帰モデル(General Linear Model(GLM))
線形回帰モデルとは文字通り直線の関数によって予測を行います。また出力された値の誤差が正規分布に従います。例として単回帰分析や重回帰分析が挙げられます。
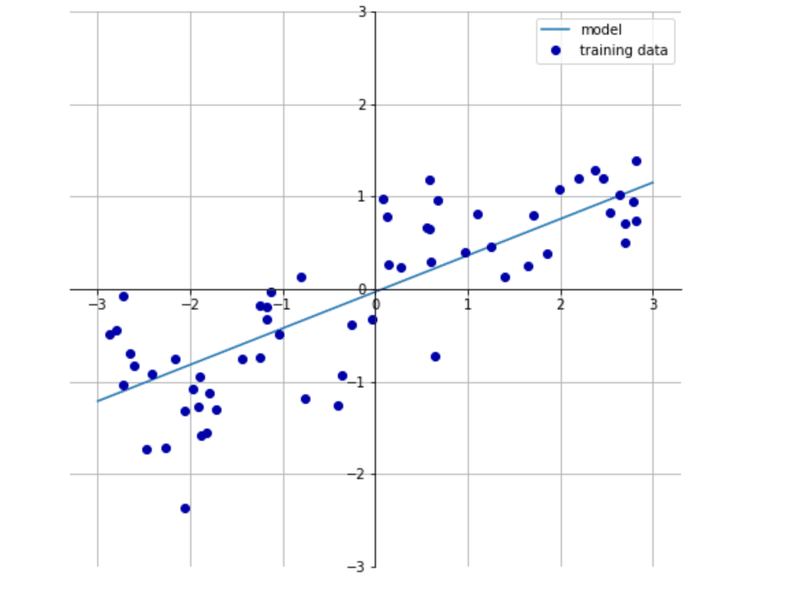
図をみて貰えば分かると思いますが、training dataと直線(モデル)は一致していません。ではこの直線はどのように引いているのでしょうか。一つの例として最小二乗法があります。
2-2.一般化線形モデル(Generlized Linear model(GLM))
線形モデルと違って正規分布以外の確率分布でも利用できるように一般化したのが一般化線形モデルです。例としてロジスティック回帰モデルなどがあります。ロジスティック回帰モデルは出力は0か1が出力されます。このモデルでは二項分布を使用することでその二つの値を出力することができます。
ざっと概念を紹介しました。次回からはそれぞれのモデルについてより深く掘り下げていきます。
この記事が気に入ったらサポートをしてみませんか?