グラフの見方について

前回統計学の基礎についての記事を書きました。今回はその中の記述統計学についてより深く見ていこうと思います。メインは推測統計学の方なので今回は基礎的に用語説明になると思います。またpythonも使う予定です。なので前提としてpythonの基礎的な使い方やanacondaインストール、numpy・pandas・matplotlib・seabornの基本的な使い方はできているとします。(とは言っても確認用に説明するかもしれません。)numpyが使えるならわざわざインポートする必要はないです。ではレッツラゴー!
・今回の内容
・基礎的なscipyの使い方
・用語の確認
・グラフについて
1.Scipyの基礎情報
scipyとは科学技術計算ライブラリです。配列や行列の演算が行えるnumpyを内包していて、統計など高度な計算を行うことができる。最適化、フーリエ変換、信号処理など沢山のことができます。(そのためにはサブパッケージを別でインストールする必要があります。)早速インポートしてみましょう。
import numpy as np
import scipy as spこれでインポートが完了しました。次に配列の作成していきます。固定にしたいので同じ値で試したい人は同じシード値を入れてください。
np.random.seed(1)
array = np.random.randint(1, 5, size = 10)
arrayarray([2, 4, 1, 1, 4, 2, 4, 2, 4, 1])と表示されました。次に基本的な統計量をみていきますが、numpyとそこまで大きく違わないのでざっとやります。
sp.mean(array)#平均
sp.var(array, ddof = 0)#分散
sp.var(array, ddof = 1)#不偏分散
sp.std(array, ddof = 0)#標準偏差
sp.amax(array)#最大値
sp.amin(array)#最小値
sp.median(array)#中央値これで大体の統計量はもう大丈夫です。多少変わっているところはありますが、numpyでも同じように書けば実行されます。四分位点についてもみていきましょう。では、より統計処理に特化したサブパッケージをインポートします。statsというパッケージを読み込みます。インポートできたら二番目のコマンドを実行してみましょう。これで四分位点の25%の値が表示されました。(データ全体の下から25%の値のこと。)後にグラフ化します。
from scipy import stats
stats.scoreatepercentile(array, 25) 2.記述統計学の基礎用語
・用語説明
・標本:手持ちデータ
・母集団:標本を含む全てのデータ(記述統計学では標本=母集団)
・確率変数:確率的な法則に従って変化する値のこと。例えばサイコロの出る目をXと置きます。サイコロの取り得る値は1〜6ですね。もしサイコロを振って4が出たとするとX=4となり、6が出たとするとX=6となります。このようにXは出た値によって変動します。これを確率変数と言います。以下のコードをJupyternote bookで同じセルに書き、実行すると1〜6までの数がランダムに表示されます。もう一度実行してみましょう。また1〜6の間のランダムな数字が表示されました。この時のXを確率変数と言います。
X = np.random.randint(1, 7)
X 確率変数の種類
・連続確率変数:結果の数値が隙間なく現れる
・離散確率変数:結果の数値が飛び飛びでで並べれられる時
・サンプルサイズ:手持ちのデータの個数のこと
・全数調査:母集団全体を調べる調査(日本人全員のような)
・標本調査:母集団の一部のみを調べる調査
・確率分布:確率変数とそれに付与された確率との対応を示したもの
・無限母集団:文字通り無限に母集団が存在すること。例えばサイコロを例に挙げると、誰かがサイコロを振り続ける限り母集団は増えていきます。
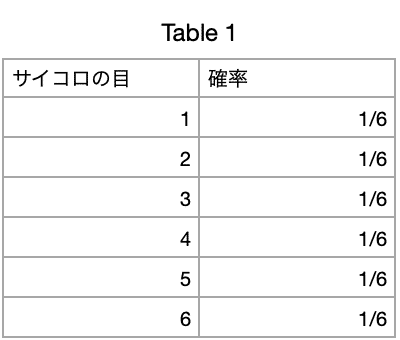
・度数:頻度
・相対度数:全体を一とした時の度数の占める割合のこと。例えばコインの表裏を挙げると、表の相対度数は1/2、裏の相対度数は1/2になります。
・累積度数:データをいくつかの範囲に区切ってたもの(階級)を小さい方から順番に並べて、度数の累積値を取ったもの。
・累積相対度数:相対度数の累積をとったもの。
基礎的な用語の解説は以上です。もし抜けていたらその都度解説します。
3.グラフの使い方について
データを集めたり、加工し終わったら次に可視化します。実際にpythonで図を可視化しながらやっていきます。ではまず先に代表的なグラフの種類についてみていきます。
・グラフの種類
・ヒストグラム
・箱髭図
・棒グラフ
・折れ線グラフ
・円グラフ
・散布図
また今回グラフを見ていくに当たって、Titanicのデータを使用します。なのでkaggleからTrain.csvと言うファイルをダウンロードしてきて下さい。(今回の記事ではあまり使わないので見ているだけで十分だと思います、はい)
まずkaggleと検索して図の右上にRegisterと言う黒いボタンがあるのでそこで自分のグーグルアカウントを使用するなりして登録して下さい。
登録し終わったらtitanicと検索してもらうと一番上にTitanic: Machine Learning from Disasterとあるのでクリックして下さい。そうすると次のような一覧が出てくると思います。この中のDataをクリックしてもらい、下へ行くとtrain.csvとあるのでそれをダウンロードして下さい。
3-1.ヒストグラム
まずヒストグラムについてみていきます。ヒストグラムはデータの散らばり具合を確認することができるグラフです。ヒストグラムを見るにあたって次のような側面に注意して見ましょう。
・ヒストグラムで見るポイント
・形:左右対称、左右の歪みなど
・中央:中央値や平均値
・範囲:四分位範囲(IQR(interquartile range))やSD(標準偏差)、分散など
・外れ値(outiers):データの集まりからかなり外れている値
では下記のコードを実行して見てください。正規分布を描画するためにseabornとをインポートしてください。
import seaborn as sns
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set()
mu = 160
sigma = 8
Unim = [np.random.normal(mu, sigma) for i in range(10000)]
Unimodal_median = np.median(Unimodal)
Unimodal_mean = np.mean(Unimodal)
sns.distplot(Unimodal, kde=False, norm_hist=False, color='blue')
plt.axvline(Unimodal_median, color="red", label="median")
plt.axvline(Unimodal_mean, color='yellow', label="mean" )
plt.legend()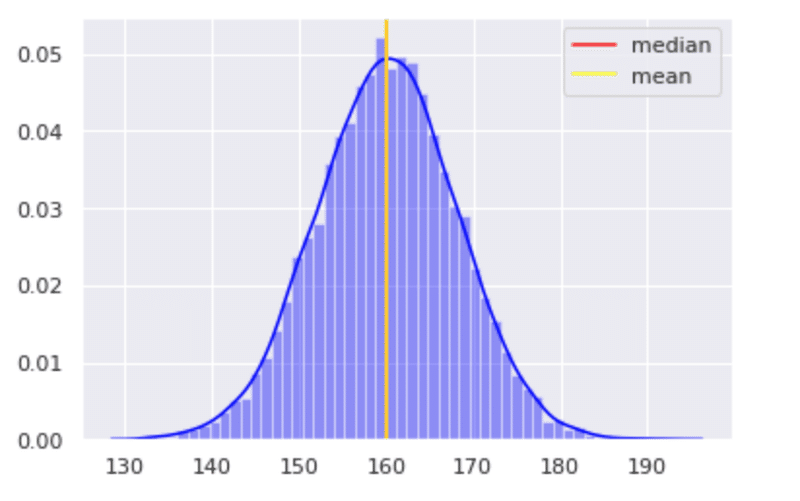
とても綺麗な分布になり、これを左右対称型と呼びます。(symmentric, Unimodal, Bell-shaped)。見てみると、平均値・中央値・最頻値がほぼ一緒の所に存在していると思います。このタイプの型かなり理想的です。この理想型を正規分布と言います。特徴として次のようなのが挙げられます。
・左右対称
・平均の観測データが生じる確率が一番大きい
・平均値から離れると生じる可能性が低くなる
この正規分布実行することで分かることが、ある一定区間に存在する人の割合を求めることもできます(特に連続型変数の場合)。例えば人の身長を例にすると、身長が170cmの人の確率はどれくらいでしょう。答えは0です。170.00000003cmや170.0023cmの人もいるわけでぴったり170cmの人がいることはほぼあり得ません。ここで登場するのが確率密度関数と言うものです。例えば170cm以上180cm以下になる確率であれば積分を行えば割合を求めることができます。上記の正規分布の青い線とx=0で囲まれた部分の面積を1と仮定します。X軸の170cmと180cmの所に縦に線を引きます。その170cm〜180cmで囲まれた部分を積分と呼ばれる手法を行って値を求めます。(今回の積分は面積を求める手法と認識しておいてください。)例えばその積分を行った結果の面積が0.20だったとします。170cm〜180cmの割合は20%と言うことになります。
またこれを平均0、標準偏差を1に標準化して描画し直した図を標準正規分布と言います。
では次に先程ダウンロードしたtrain.csvファイルを読み込みましょう。
import pandas as pd
df = pd.read_csv("train.csv")読み込みができたら次にヒストグラムを作っていきます。下記の通りに実行してもらえば描画できると思います。
mean_age = np.mean(df["Age"].dropna())
median_age = np.median(df["Age"].dropna())
sns.distplot(df["Age"].dropna(), bins=10)
plt.axvline(mean_age, color = "green", label = "mean of age")
plt.axvline(median_age, color = "yellow", label = "median of age")
plt.legend()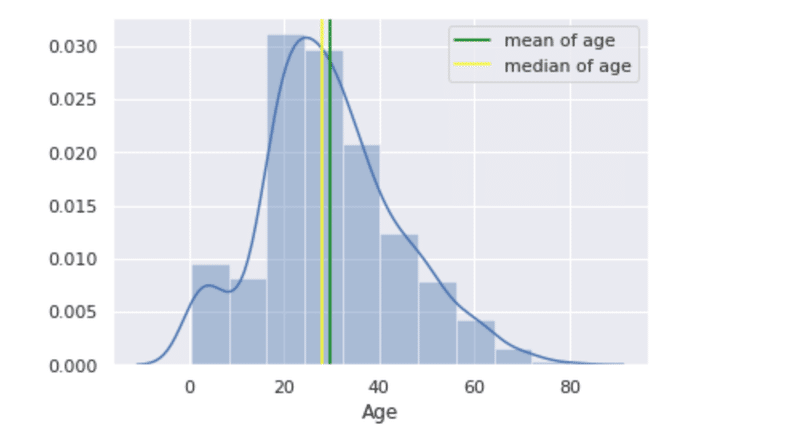
見てみると右側が歪んでいますね。これを英語ではright skewedといいます。(skewedは歪みを意味する。)逆に歪んでいたらもちろんleft skewedとなります。右に歪んでいる場合、平均値は中央値よりも大きくなります。逆に左へ歪んでいる場合、は平均値の方が小さくなります。その他の例を見ていきましょう。
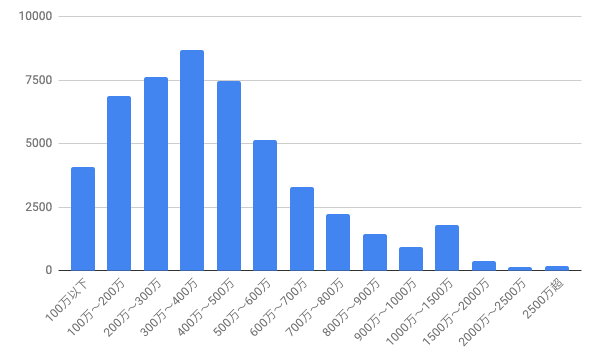
このグラフは日本人の年収をグラフ化したものですね。これも右に歪んでいますね。これらを平均した場合、右側の2000万以上の方達が平均値をあげてしまいますね。一方中央値は2000万以上の数が著しく増えない限りはそこまで揺るがないと思います。
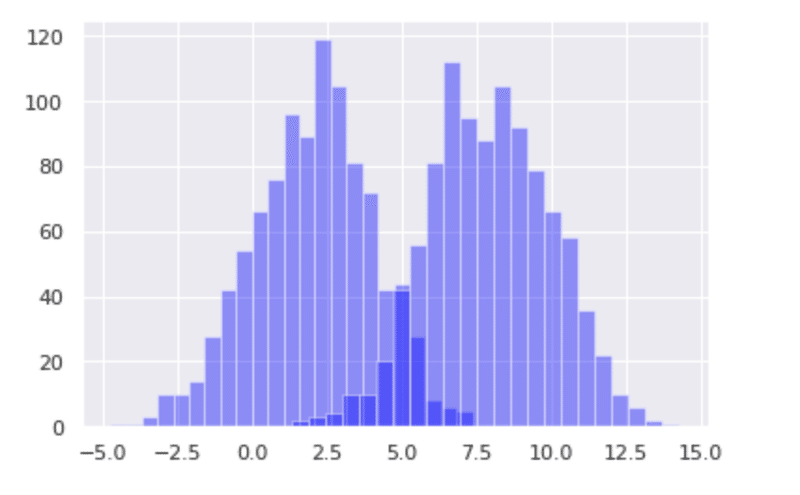
次のグラフを見ていきましょう。何やらに分割されていますね。これを二つ山型(二峰性)と呼びます。(英語でBimodal, double-peakedと言う)またこれが三つ以上、つまり凸凹になっている状態のことを多峰性(multi-modal, Plateau(高原))と呼びます。このデータから考えられるのは異なる性質を持ったデータが混じっている可能性があります。またそれ以外に考えられる理由としてデータを描画する際の設定(例えばbinsなど)を調整することで綺麗な正規分布になる可能性があります。
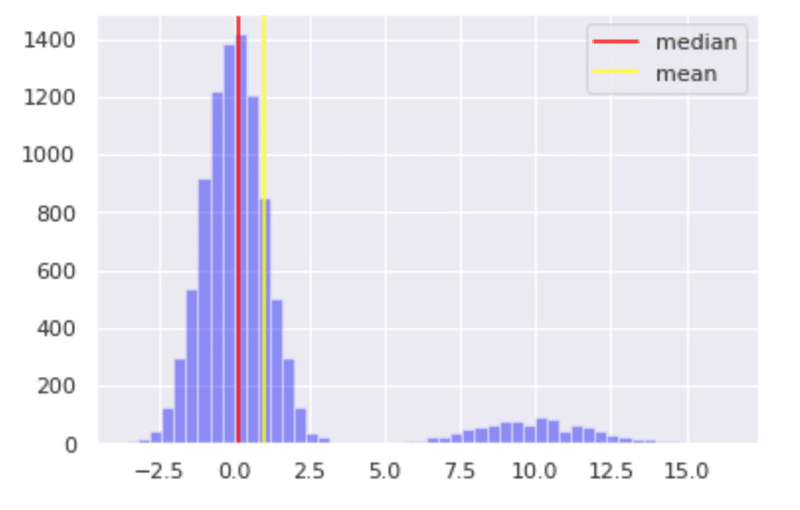
次のグラフにいきましょう。明らかに外れ値っぽいデータがありますね。これを離れ小島型と言います。これも異なったデータや測定の誤りが考えられます。
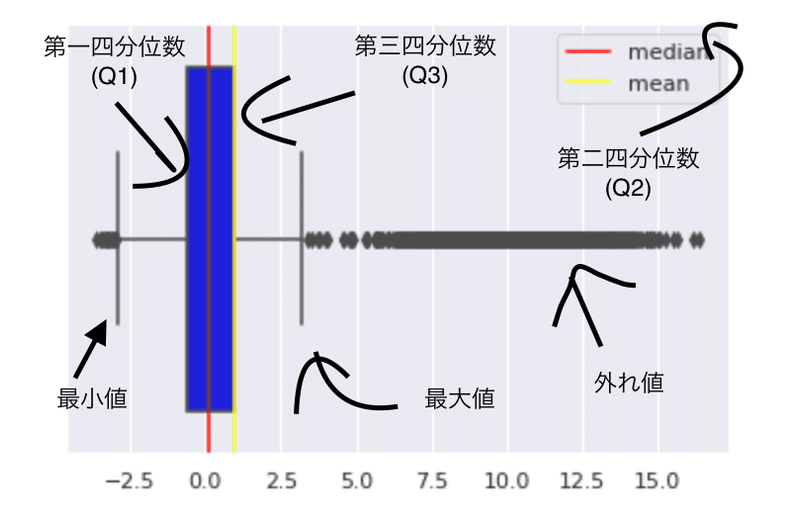
3-2.箱髭図
最大値や最小値、中央値などを視覚的にみやすくしたグラフ。また外れ値も分かる。先程の離れ子島型のヒストグラムを箱髭図にしてみると次のようになる。黒い点が外れ値である。
3-3.その他のグラフ(おまけ)
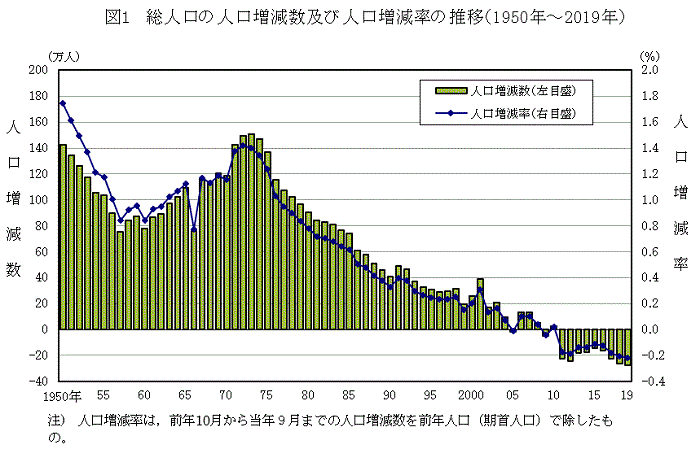
・棒グラフ:数の大小を比較する(世界の人口の数の比較など)
・折れ線グラフ:量の増減をみることができる。棒グラフと併用す際は増減率として表すことが多い。(日本の人口の推移など)
・円グラフ:全体の構成比をみることができる。円グラフを使う際は次のようなことを気をつけたほうが良い。
・情報が多い場合は要素が被ってしまうので要素の間隔を開けるなど工夫をする。
・同じくらいのパーセンテージだと視覚的にどちらが多いのか少ないのか分からなくなってしまうので、パーセンテージはつけ忘れないようにする。特に3Dだと誤解を招きやすいので気を付ける。
また表現によっては簡単に誤解を招きやすくなるので注意。以下のサイトが興味深かったので気になる方は見てください。
・データ可視化のアイデア帳
・これが印象操作!NHKの分かり易すぎる印象講座が話題に!
また円グラフ以外にも誤解を招くグラフの作り方があるので参考にして見て下さい。
・やってはいけない!誤解をまねくグラフ表現5パターン
個人的に円グラフがでたら真っ先に疑った方が良いと思います。とは言っても、円グラフも役立つ時があるので上記のリンクを見てみるとより円グラフへの理解が深まると思います。
次に散布図です。これはデータの関係性をみることが出来ます。一つの要素が変化した際に二つ目の要素がどのように変化するかを確認することができ、何かしらを相関関係をと呼びます。では再びTitanicのデータを使用して要素の関係を見ていきましょう。Titanicデータの年齢と料金の関係性について調べていきます。
sns.jointplot("Age", "Fare", data = df)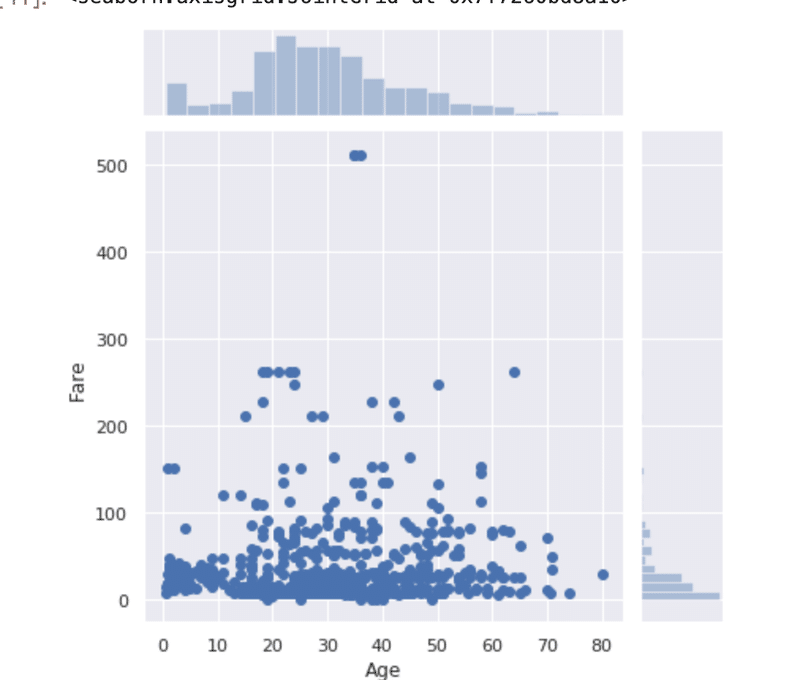
今回は関係性はなさそうです。
今回は以上です。
この記事が気に入ったらサポートをしてみませんか?