
Coursera Machine learning week 1(まとめ)

実は一度挫折しました。その時は機械学習のきすら知りませんでした。ある程度機械学習の知識がついてきたので英語の勉強も兼ねて再開しました。この講座がどのように構成されているかなどの説明は省きます。
week1のざっくりとした内容ですが、まず機械学習の概念的な説明、その次に損失関数、勾配降下法、最後におまけとして線形代数について紹介しています。線形代数は除きます。
https://www.coursera.org/learn/machine-learning
What is Machine Learning?
機械学習とは何かと説明する際に2人の機械学習の定義についてに述べた人を紹介しています。
・Arthur Samuel(1959):Field of study that gives computers the ability to learn without being explicitly programmed.
as measured by P, improves with experience E.
訳すと1人目が
明示的にプログラムされていなくてもコンピュータに学習能力を与える学問分野。
2人目が
あるコンピュータプログラムは、あるタスクTとあるパフォーマンス指標Pに関して、経験Eから学習すると言われています。
となります。
Machine Learning algorithms
次に機械学習のアルゴリズムについて紹介しています。
・Supervised learning(教師あり学習):
・Unsupervised learning(教師なし学習):
・Others:Reinforcement learning, recommender systems(強化学習・推薦システム)
ざっと内容を見てみると強化学習はこの講座では扱わないようです。
・Supervised learning
Supervised learning(教師あり学習):教師あり学習では入力値と正しい出力値が予め与えられていて、入力値と出力値間の関係をアルゴリズム で定義する。以前教師あり学習について簡単にまとめたので参考にしてください。
✅教師あり学習
— ジュキヤ@AI+英語勉強中 (@juki_DSandGM) September 11, 2020
☑️目的
ラベル付されたデータ(トレーニングデータ)を学習して、未知のデータや将来のデータを予測すること。
☑️種類
・分類ー出力値が離散値(このメールはスパムメールであるかないかを判断)
・回帰ー出力値が連続値(明日の気温はどれくらいかを示す)#機械学習 pic.twitter.com/ZWFNqa5Hpx
また教師あり学習問題は回帰(regression)と分類(classification)に分けることができます。
・Regression(回帰)
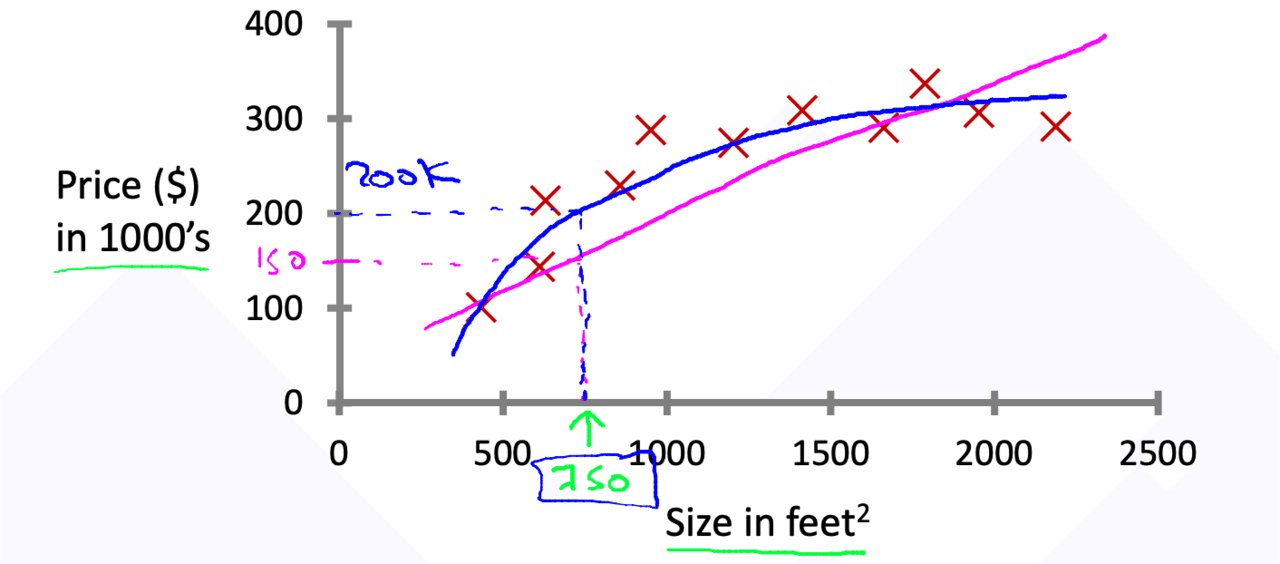
回帰問題では連続値の結果を予測します。例えば次の住宅の価格を予測する場合、入力値の値を参考にして直線を引きそれを頼りに価格を予想します。例えば住宅の大きさが750だった青のモデルの場合は200k、マゼンタモデルの場合は150k位だと予測することができます。
・Classification(分類)
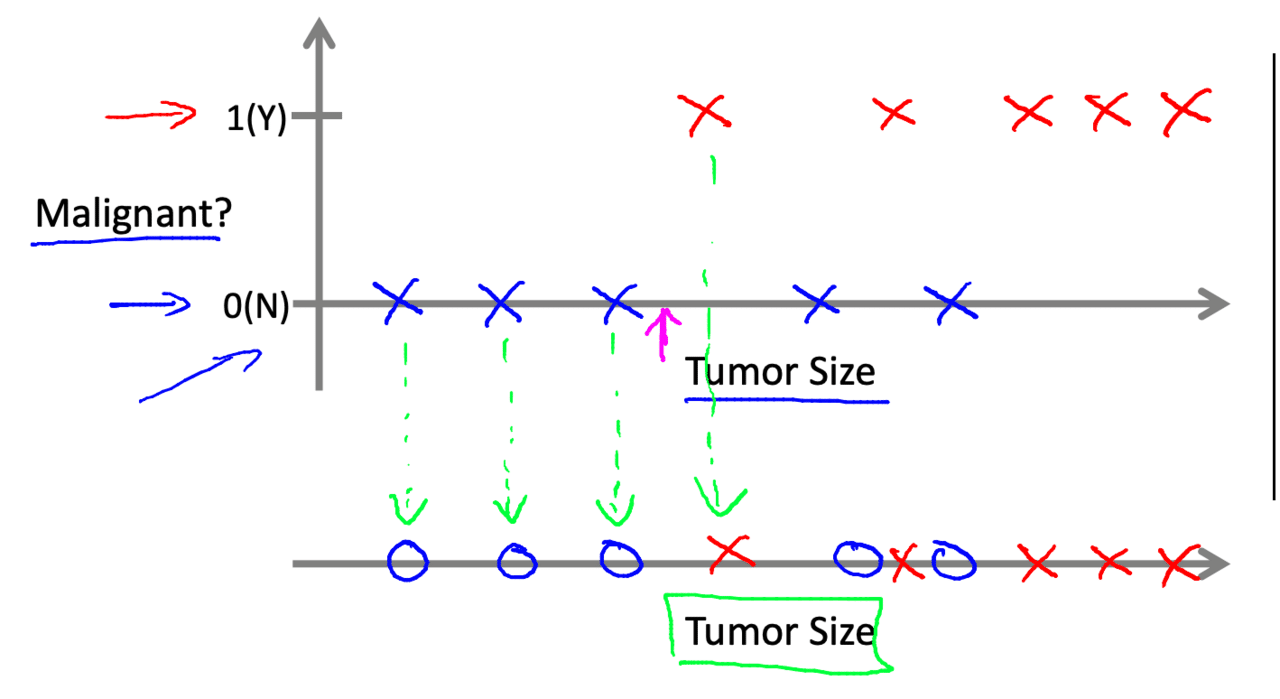
分類モデルでは離散値を出力します。入力された変数を離散値に分けます。例えば癌の腫瘍が陰性か陽性かを判断する問題を用意します。ある一定のサイズを超えたら陽性判断するみたいな感じです。
・Unsupervised learning(教師なし学習)
教師なし学習との違いは正解データがあるかないかの違いです。教師あり学習でしたらこの面積の場合はこの価格だ、この腫瘍の大きさだったら悪性だと判断していました。一方教師なし学習は入力値しか必要ではありません。ではこの教師なし学習では何を目的とするでしょう。
正解はデータの特徴を見つけます。例としてクラスタリング問題があります。入力されたデータから似たような集団(クラスタ)を作成します。教師なし学習は後の講座であるので詳しくは省きます。
・モデルの定義とコスト関数
このチャプターでは実際にモデルの定義をしていきます。モデルはアルゴリズムを構成するための一つの要素です。
先程の回帰問題を例にあげます。この問題では住宅の大きさ(入力値)から価格(出力値)を予測していました。このように入力値が一つの回帰を単回帰と呼びます。複数の場合は重回帰と呼びます。機械学習では仮説関数と言う関数を求めます。
モデルを定義する前に軽く記号について紹介します。
・m:Number of training example(トレーニングセットの数)
・x:input variable(features)(入力値)
・y:output variable(target)(出力値)
モデルは次のように定義します。(仮説関数Hypothesis functionのhを取っています。)θがパラメータと言います。xに入るのが今回の場合住宅の大きさになります。
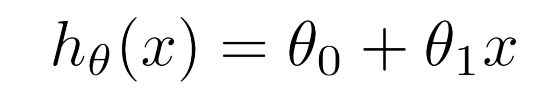
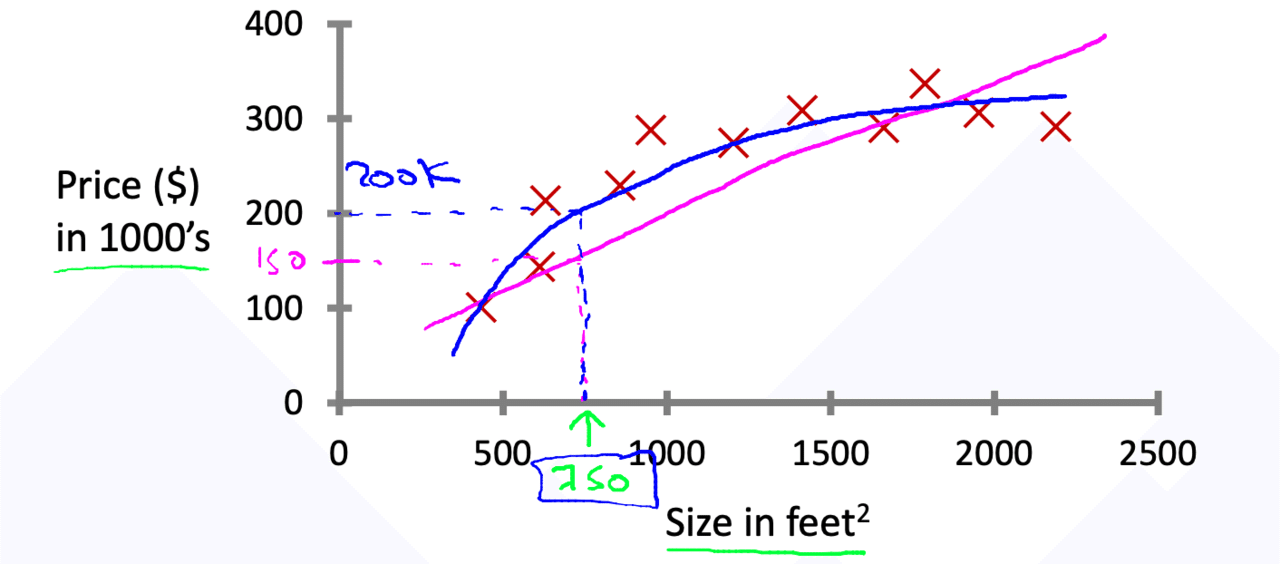
先程のマゼンダ色の直線を仮説関数とします。(青色も仮説関数ですが今回は一次関数を扱います。)
直感的なイメージは次のスライドで紹介されています。
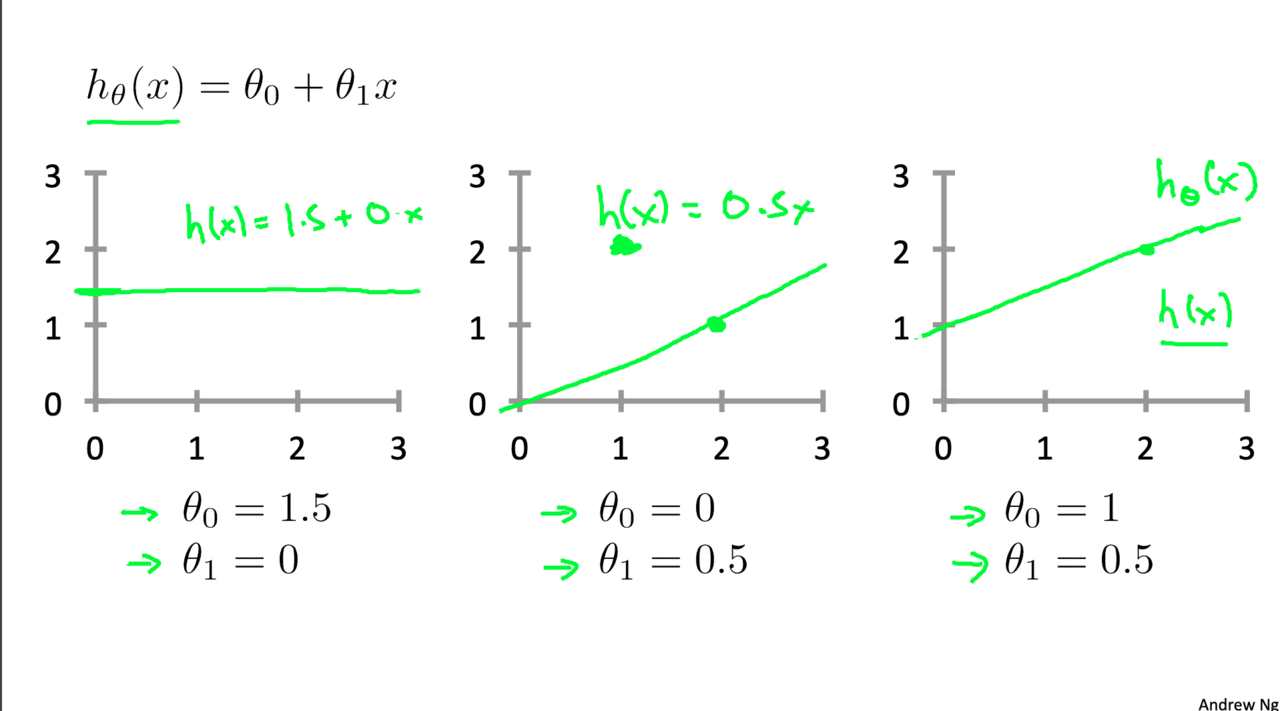
ではこのパラメータ(θ)をどのように求めるか。ここで登場するのがコスト関数というものです。
・コスト関数
コスト関数は次のように定義されます。
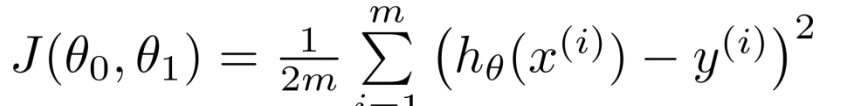
この関数を求めるに当たってJ(θ)を最小化します。最小化することでより正確な予測をすることができます。このJ(θ0、θ1)を最小化するの最終的な目的です。左側が仮説関数で右側がJ(θ1)とθ1の値との関係のグラフです。左側の関数を見てみると値と仮説関数が全て当てはまっています。この時誤差は0で、θ1の値は1です。なのでその情報を右側のグラフにプロットしてあげます。
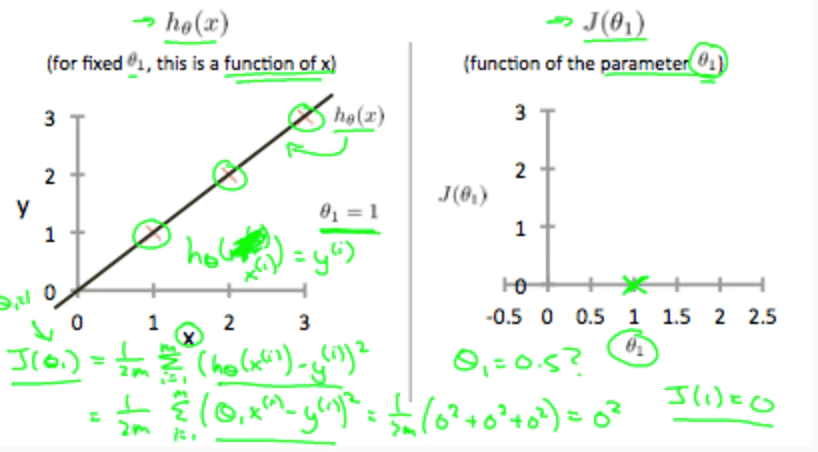
誤差とθの値をプロットしていくと二次関数ができます。これをθ0、θ1でどちらもやります。ではJθを最小化するために次のアルゴリズムを使用します。
・勾配降下法(Gradient descent)
まず式 は次の通りです。これは偏微分の公式と同じです。αは学習率を表しています。学習率については後ほど紹介します。ここで注意ですがθは同時に更新します。例えばθ0を先に求めてそのθ1をθ1の時に使用してはいけません。

勾配降下法とは主にニューラルネットワークで使われる手法で最適な重み(係数)を求める手法のことです。最適な重みというのはコスト関数の誤差が0ということです。先程のグラフでいうθ1が1の所でJθが0になりました。この勾配降下法を使用して今回でいうJθが0になるθを探します。
・Learning rate(学習率)
学習率とは簡単に言えばどれだけ学習を進めるかと言うことです。
・学習率が小さすぎると、勾配降下法は遅くなってしまう
・学習率が大きすぎると、勾配降下法は最小値を通り過ぎてしまう。(収束するどころか広がってしまう。)
一見便利な勾配降下法ですが、よく局所的最適解(local optima)に陥ることがあります。局所的最適解とは見せかけの最小値というイメージです。求めるべき最適解というのは大域的最適解と言う用語があります。こちらが真の最小値となります。局所的最適解と大域的最適解をグラフで見てみましょう。
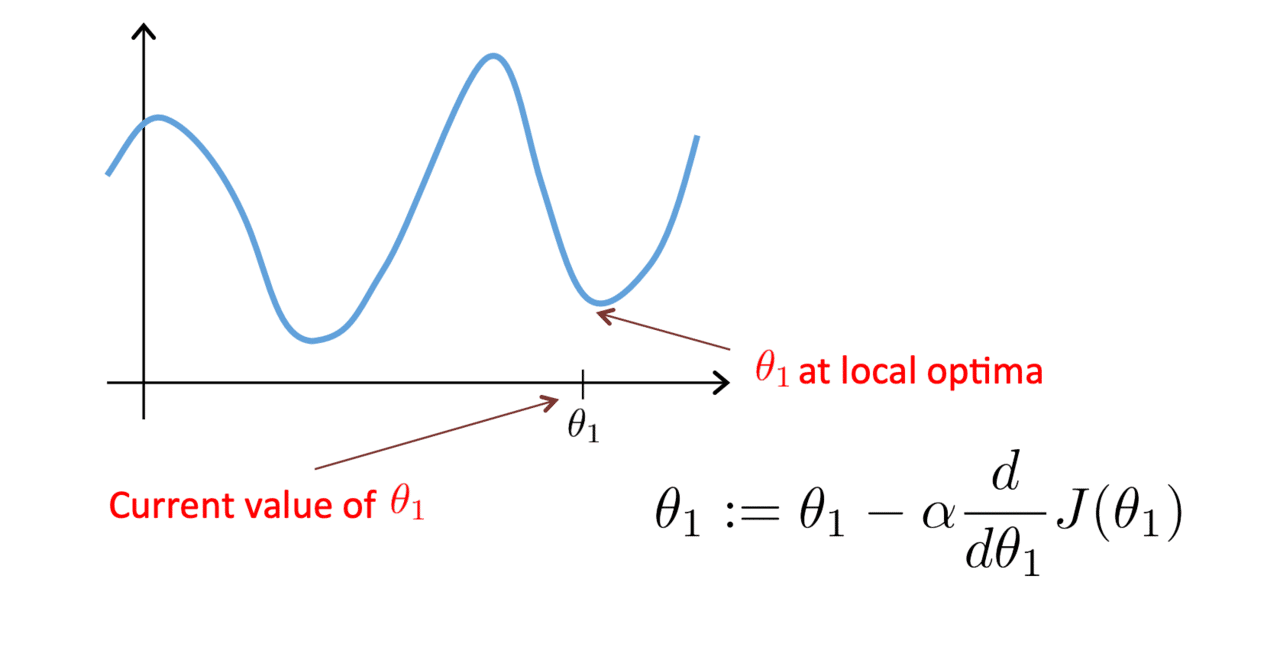
以上がweek1の内容です。かなり有名な講座なので調べれば沢山有益情報があるので調べてください。またこの講座は日本語訳もあるので気軽に受講することができると思います。
昔挫折した時わかりやすいと感じた英語の記事↓
この記事が気に入ったらサポートをしてみませんか?