CommonLit Readability Prize参戦記

こんにちは
8/3に終了したCommonLit Readability Prizeコンペの反省を書きたいと思います。
結果から言うと大幅shake downしてしまいました。
![]()
publicではメダル圏内ギリギリ残れていたのですが、見事にshake downしてしまいました。
今回は自分なりになぜこんなにもshake downしてしまったのかということと、コンペ期間中の自分の取り組みを簡単に振り返ります。かなり内容が薄いので生暖かい目で見てください。
・なぜ大幅にshake downしてしまったのか
考えられる理由として下記の可能性があると思いました。
・CVよりもLBに注目しすぎた
・適当に決めた加重平均の重み
・アンサンブルを甘く見ていた
まず一つ目に関してですが、一番の理由がこれかなと思っています。LBが高かったモデルのほとんどがCVは結構低いということに気づきました。
参考までに使用したモデルのCVとLBです。
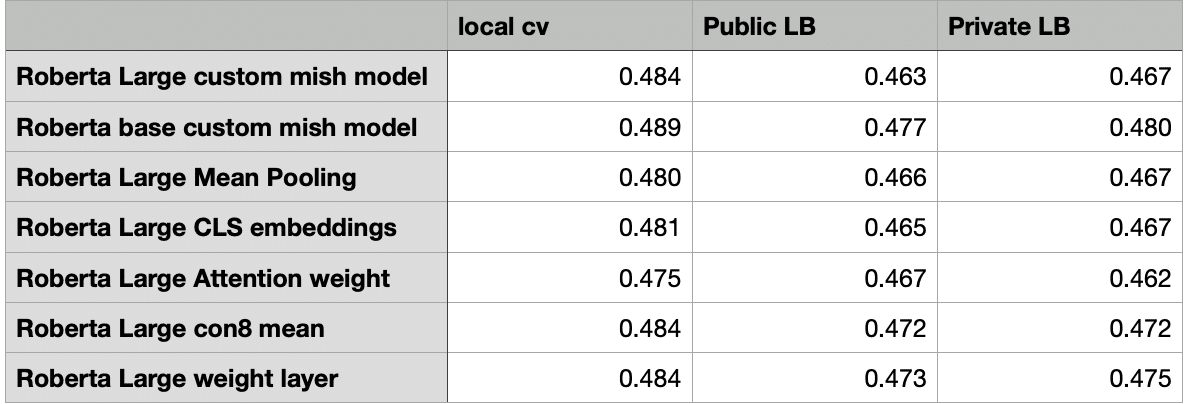
最終的に選んだのは上5つのアンサンブル(public LB: 0.460, private LB: 0.462)とこれら全てを使用したアンサンブル(public LB: 0.461, private LB:0.463)のモデルです。二つ目の理由も含まれているのですが、publicLBのスコアを元に加重平均をしたためshake downしたのではないかと考えています。
三つ目の理由ですがアンサンブルを舐め過ぎていました。上位陣はシングルで0.55くらい出しているのだろうと思っていたのですが、そんなことありませんでした。大体0.465位のモデルを沢山アンサンブルして高いスコアを出していました。また思い込みとして、アンサンブル学習はベストなシングルモデルが出ない限りやらない方がよいという固定概念をずっと持っていました。そのため最終週までアンサンブルをやらず、適当に重み付けをしたため思うような結果が出ませんでした。
これら以外にも反省点がかなりあります。まず実験管理がうまく機能していませんでした。一応github上のREADMEで実験のまとめなどしていたのですが、LBのスコアを上げたいがために途中で汚くなってしまいました。具体的にはseed値, max_len, batch_sizeがばらばらになってしまい、同じ実験を2, 3回繰り返すはめになってしまいました。
・今後どうすべきか
一番の反省点は実験が汚かったことと、CVを甘く見過ぎていたことだと思っているので次回以降のコンペではこの辺を最優先で重視してみます。
最初の心意気として落ちている手法を一通り試すというのが目的でしたが、結果的にRoBERTa onlyになってしまったのも反省しています。言い訳ですがLargeモデルがなかなか安定しなかったので、やる時間がありませんでした。
ある程度のモデルバリエーションができたらアンサンブルを試す。これに関しても言い訳ですが、時間がなかったのと上位陣はアンサンブル抜きで銀圏くらいのスコア(0.455位)を出していると思い込んでいたため中々手をつけることができませんでした。
かなり汚い実験になってしまいましたが一応今までの取り組みを載せておきます。(改めてみたら地獄絵図でしたので閲覧注意です。)
この記事が気に入ったらサポートをしてみませんか?