うごくExcelを作る

実はこの記事が山場です。動くExcelを作ります。
難易度 ☆☆☆☆
便利度 ☆☆☆☆
応用度 ☆☆☆☆☆
まずは分析
データを増やしました。前回は、商品がA,B,Cの三種類でしたが、実際のデータでは商品が数千~数万点、商品カテゴリだけでも数百と言うことはざらにあります。そこで、そういうケースを想像できるように、とはいっても多すぎるとレクチャーにならないので、商品数を8点、レコード数を2万行にしてみました。また、前回と同様の集計もくっつけています。このようにワークシート関数で集計をしておくと、アイテムが替わっても、数式はコピペだけで十分で、J8:Q8をコピーして下方へペーストするだけです。
さて、ここまでは前回と変わりません。いや、実は、データが少し変わりました。前回のデータでは、価格が安くても高くても、一回あたりの購入点数は変わりませんでしたが、今回の商品達は、価格が安いときと高いときで平均購入個数が変わっているようです。
データ分析者は、こういうところに引っかかります。価格が安ければたくさん買う、価格が高ければ少量買う、という心理があるのではないか?・・・これが、「仮説」です。実際にもそういう心理はありそうですので、この仮説をもっとちゃんと観察していきましょう。
前記事の「ソースを一元化すること」にてヒストグラムを作ったときと同様に、ここではpriceを横軸にしてヒストグラムを作って見ます。ひとまず、レコード数(購買回数)と、購入個数を対象にヒストグラムを作ります。商品はまずりんごを対象に。りんごの最安値は125円、最高値は282円なので、価格を125円から4円ずつ区切って、レコード数の累積と購入個数の累積を取っていき、その後で差分を取って、その価格における回数と個数を出します。

このように、priceを125から285まで4ずつ動かして、回数累積、個数累積を入れます。それぞれ式は、
=COUNTIFS($B$8:$B$20007,"りんご",$C$8:$C$20007,"<="&$K21)
=SUMIFS($D$8:$D$20007,$B$8:$B$20007,"りんご",$C$8:$C$20007,"<="&$K21)です。データが増えたので、参照範囲が20007行目までになりました。この数式をそれぞれL21, N21に貼って下方へコピーペーストします。データを眺めると、どちらも真ん中の方で盛り上がっている様子が見えますね。これをグラフにすると、

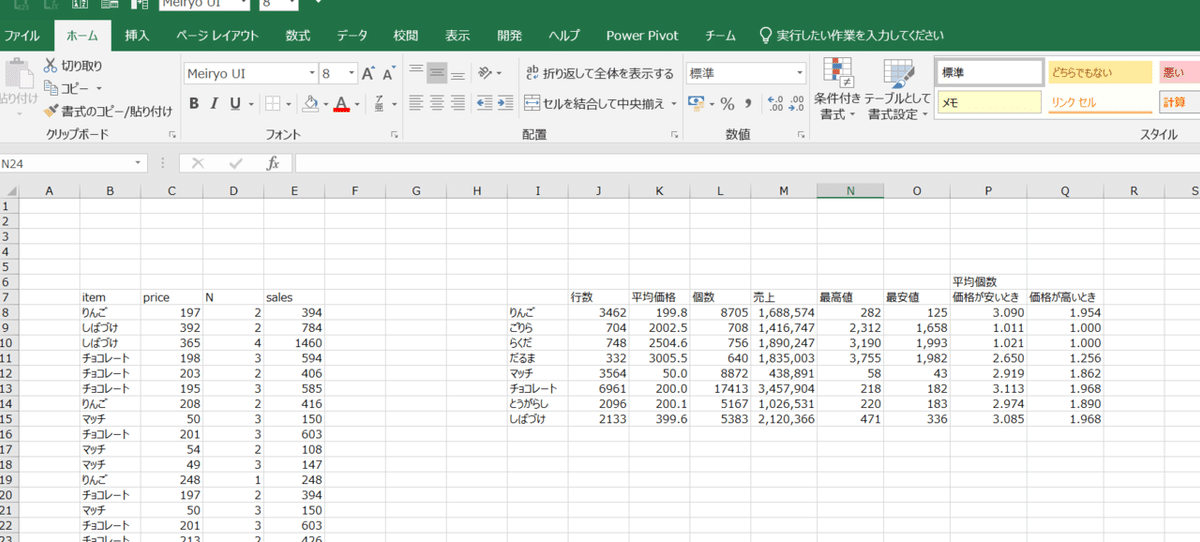
こうなります。回数、個数とも、平均価格付近で沢山販売されている様子が見られます。しかしこれだけでは、当初の仮説だった、「価格が安い方が、一回につき沢山売れる」は観察できません。ただ、若干ですが、個数のグラフの方が左に寄っている気がしませんか?個数の方が左に寄っていると言うことは、少ない回数でも個数が多くなる、つまり、安い方が一回に買う個数が多いんじゃないかと思えます。
となると次は当然、「一回あたり購入個数」を出せばいいですね。このヒストグラムでは、価格別に購入回数と購入個数を算出しているので、これを割り算すればOKです。個数の右隣のセルに、「個数/回」の列を作り、
=IF(M21>0,O21/M21,"-")と数式を入れて下にコピーします。実は、数式は(個数=O21)/(回数=M21)でよいのですが、価格帯によってはたまに回数がゼロになり、割り算ができなくなるので、IF文を入れてゼロ割を回避しています。さらにこれをグラフにすれば、
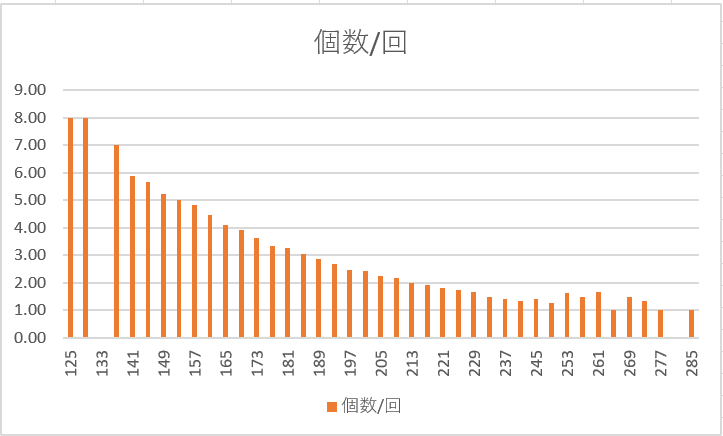
このグラフが得られました。見事に、価格が上がると一回あたりの個数が減っている様子が見られました。
次は、うごくExcel
さて、「りんご」について、価格と購入回数、購入個数、一回あたり購入個数を観察してきたわけですが、これを他の商品についても見たいですよね。
でも、例えばこのデータをワークシートごとコピーして、リンゴのシート、ごりらのシート、らくだのシート・・・と作るのは大変だし、データがコピーされることは避けたい。では、ヒストグラムを書くために作った集計テーブルを8つコピーして・・・というのも、数式をいちいち引き写すのがめちゃめちゃ面倒です。では、どうするか。
まず、上の式、"りんご"と書かれているところを、ワークシート参照にします。例えば$I$20のセルに"りんご"と記入しておき、それを参照すると
=COUNTIFS($B$8:$B$20007,$I$20,$C$8:$C$20007,"<="&$K21)
=SUMIFS($D$8:$D$20007,$B$8:$B$20007,$I$20,$C$8:$C$20007,"<="&$K21)$I$20の値を"りんご"から"ごりら"に替えれば、たちまちごりらのグラフができあがります。
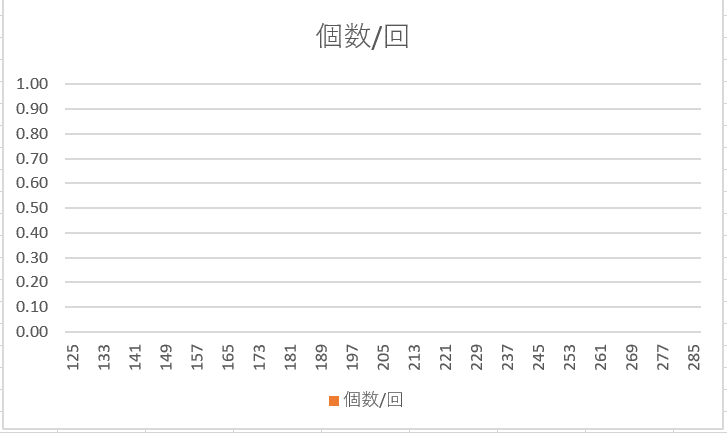
あれ?グラフが出ない・・・。それもそのはず、価格の値が125円から285円までになっていて、しかしごりらの最安値は1658円ですから、$I$20の値を変えるだけではダメで、価格の軸も同時に替えなければなりませんでした。幸い、上の集計テーブルで最安値と最高値を既に計算済みなので、これを持ってきましょう。そして、最安値と最高値を40分割し、これをヒストグラムの軸にするのです。具体的には、$I$21と$I$22にそれぞれ
=VLOOKUP($I$20,$I$8:$O$15,7,0)
=VLOOKUP($I$20,$I$8:$O$15,6,0)を記入します。$I$20には"ごりら"が書かれているので、VLOOKUPでその値を検索し、最安値と最高値を持ってきます。そして、この最高値と最安値の間を40分割するための間隔を
=INT((I22-I21)/40)+1で作り、価格の欄には最安値からこの間隔ずつ足していく数式を入れれば、"ごりら"の価格幅に応じた価格軸を作ることができます。ごりらの場合は間隔は17になりました。また、この式は"ごりら"に限らず、他のアイテムの名前を入れてもちゃんとそれに合った軸が自動的に計算されます。ちなみに、間隔の式でINTを取っているのは、価格が全て整数なのに間隔が整数になっていないと気持ち悪いからなのですが、これは必須ではありません。
このように、「うごくExcel」では、一つのセル(この場合は$I$20)の値を変えることで、集計結果やそれを参照したグラフがそのセルの値に合わせて全て変わるように作ります。
さらに、うごくExcel
さて、このセルに「りんご」とか「ごりら」とか「マッチ」などと記入すれば、集計表とグラフが全て入れ替わるのでも十分なのですが、いちいちアイテム名を記入するのはまだちょっと面倒です。
そこで、修正します。
$I$20はアイテム名を入れる場所でしたが、ここに次の式を入れます。
=INDEX($I$8:$I$15,$I$19)そして、参照している$I$19に数字 1 を入れます。INDEXは、選択範囲の中から何番目かの値を持ってくる関数で、選択範囲は集計表のアイテム名が記されている場所ですから、つまり1を入れれば一番上の、2を入れれば2番目のアイテム名が、このセルに入ってきます。こうすると、いちいちアイテム名を入れるのではなく、アイテムの番号を一つの数字で入れればOKです。かなり楽になりました。
でも、さらにさらに動かします。
メニューの[開発]→[挿入]から、フォームコントロールの「スピンボタン」を選択し、ワークシート上に置きます。
この赤丸で囲ったボタンです。その後、右クリックから「コントロールの書式設定」を選択すると、

このような、オブジェクトの書式設定ダイアログが出てくるので、この中の「リンクするセル」を$I$19にします。その他の値は適当に入れます。
すると、このスピンボタンは、上を押すとリンクした$I$19のセルの値を1ずつ加算し、下を押すと減算しますから、スピンボタンの上下を押すだけで洗濯されるアイテムが順番に切り替えられ、その表とグラフが描画されます。(ちなみに、このボタンはマクロを使いません。Excelではセキュリティの理由から、マクロを追加してしまうといろんなところで動かなかったり、警告が出たりしますので、できるだけマクロは使いたくないのですが、このボタンはOKです。)
グラフを連続的に、1秒未満の待ち時間で描画できるということは、一つのグラフのイメージが脳裏に残っている間に次のグラフを見ることができるということで、グラフの変化や違いの認識をダイナミックに把握することができます。データ分析では「気づきの連鎖」が最重要課題で、頭の中でふと気がついたことが、気づきの連鎖によってどんどん大きくなり、「仮説」を生み出していくことが非常に重要な行為なのですが、短い時間で連続的にフラフを観察することは、その気づきの連鎖に大いに貢献しますから、「うごくExcel」を作ることはデータ分析にとって非常に重要な作業であると言えます。
全部入りのExcelは次です。
おわりに
実は、このように連続的にグラフを観察することは、他のツールでも十分できます。例えばRなどでは、スクリプトを書くことによって画像としてのグラフを大量に吐き出し、それを一枚の画面に貼り付けたりできます。連続的に見るよりは、一面に貼り付けられているわけですから、さらに気づきの連鎖が生まれやすくなります。
では、うごくExcelを作る意味は何か。
それは、ここまでの作業が、気づきの順になっているということなんです。
一回あたり購入個数の分布を、アイテムを替えて観察しようと、最初から思っていたわけではありません。最初は、集計表を作ったときに、「りんごは高値と安値では個平均購入個数が違うな・・・」という気づきでした。そこで、まずりんごについて価格別の回数分布と個数分布を作った。その後、これでは求めるものが見えないと思って、一回あたり購入個数の列を作った。そしてこれをグラフにした。すると、他のアイテムにも興味が湧いて、アイテムを替えられるようにした。すると、いちいちアイテム名を書き込むのが煩わしかったので、最終的にはスピンボタンで切り替えられるようにした。
これらの作業がすべて、気づき→作業→気づき→作業の連鎖になっています。データを見てすぐに、一回あたり購入個数の分布のグラフをアイテムの分だけ出そうと思っていれば、他のツールで作り始めても良いのですが、実は最初からそう思っていたわけではなく、気づきの連鎖によってここまできただけです。Excelで作業する意味はこれで、具体的なデータやグラフを常に観察しながら、ワークシートに気づきをどんどん注入していくことができる。気付いたことからすぐに試すことができて、確認することができて、あとからあとから追加していくことができるのが、Excelで作業することの強みです。
以前の記事「はじめに~Excelでデータ分析をしよう」にも書いたのですが、Excelは「究極のWYSIWYG」です。計算の途中経過も、試行錯誤の過程も、実現できていることも、すべてワークシートの上に見えますから、それだけ気づけるポイントが多いです。その他のツールは、データのことをよくわかっていれば、何が起こっているか、どうやって切ればいいか、どう可視化すべきかが想像つきますが、そのままが見えないので、よくわからないデータを観察するには不向きです。これが、私がExcelを愛用している理由です。
もちろん、データの規模によってはExcelは使いにくいということもどこかで書きました。Excelはビッグデータには向きません。しかし、ビッグデータもある程度集計したり、部分をサンプリングしてくれば、十分取り扱える範囲になりますし、とにかく何か切り口に気付かなければ分析のしようもないので、やはりそういうときにはExcelなどでまずデータを見て、切ってみて、だんだんと気づきを積み上げていくことになりますので、その時には集計データやサンプリングデータについて、うごくExcelを作ることになります。
注
上の分析結果は、どのアイテムでもきれいに価格と購入個数との間に相関が見られましたが、それは実はそのように作ったからです。実データはこんなに美しくはありません(笑)。
このデータは乱数シミュレーションによって作っています。もちろんExcelを使って。Excelの乱数関数であるRANDに、正規分布の逆関数であるNORM.INVをつかったり、ガンマ分布の逆関数であるGAMMA.INVを使ったりして、価格と購入個数にちゃんと相関が出るようにデータを作りました。
この乱数シミュレーションが、実は次のネタにしようと思っているところです。Excelで実施する乱数シミュレーションは非常に強力なツールになります。
この記事が気に入ったらサポートをしてみませんか?