
テキストで動画の内容を検索できるシステムの試作

この記事はjig.jp Advent Calendar 2023の12月18日(月)の記事です。
今年はAIの発展がものすごい一年でしたね。
この記事では、先日の AWS re:Invent 2023 で発表されたAI関係のサービスを利用して、テキストで動画の内容を検索できるシステムを試作してみます。
システムの全体像は以下のようになります。
動画ファイルがS3バケットに保存されたのをトリガーに起動したLambda関数で、動画から数秒間隔のスナップショット画像を取得してそれらのEmbeddingsを Titan Multimodal Embeddingsで計算します。そして、ファイルパスと経過秒数をスナップショット画像のEmbeddingsとともに OpenSearch Serverlessベクトルエンジン に保存することで動画ファイルを検索可能にします。
(上記リンクは両方ともDevelopers IOさんの記事に飛びます)

Titan Multimodal Embeddingsを有効にする
Titan Multimodal Embeddingsを利用するには、まずAWS コンソールのBedrockのページから申請を出す必要があります。
本記事執筆時点では、Titan Multimodal Embeddingsは一部の米国リージョン(us-east-1とus-west-2)でしか利用できないようです。
この記事では、リージョンをまたいだ通信を避けるためにS3バケットもLambda関数もOpenSearch ServerlessのコレクションもEC2インスタンスも全てus-east-1リージョンに作ることにします。
では、利用申請を出しましょう。 Request model access をクリックして・・・

次の画面で Titan Multimodal Embeddings G1 にチェックを入れて申請。

しばらくすると ✅ Access granted になりました。

Amazon OpenSearch Serviceベクトルエンジン
AWSコンソールのOpenSearch Serviceのページから新しい コレクション を作成します。
コレクションタイプで ベクトル検索 を選択します。
セキュリティの設定は、本番運用するなら標準作成を選んだほうが良いのでしょうが、今回は試作なので 簡単作成 でやっていきます。

しばらくすると、無事にコレクションが作られました。

作成されたコレクションの詳細ページを開くと、上部に「ベクトルインデックスを作成」というボタンがあるのでクリックします。

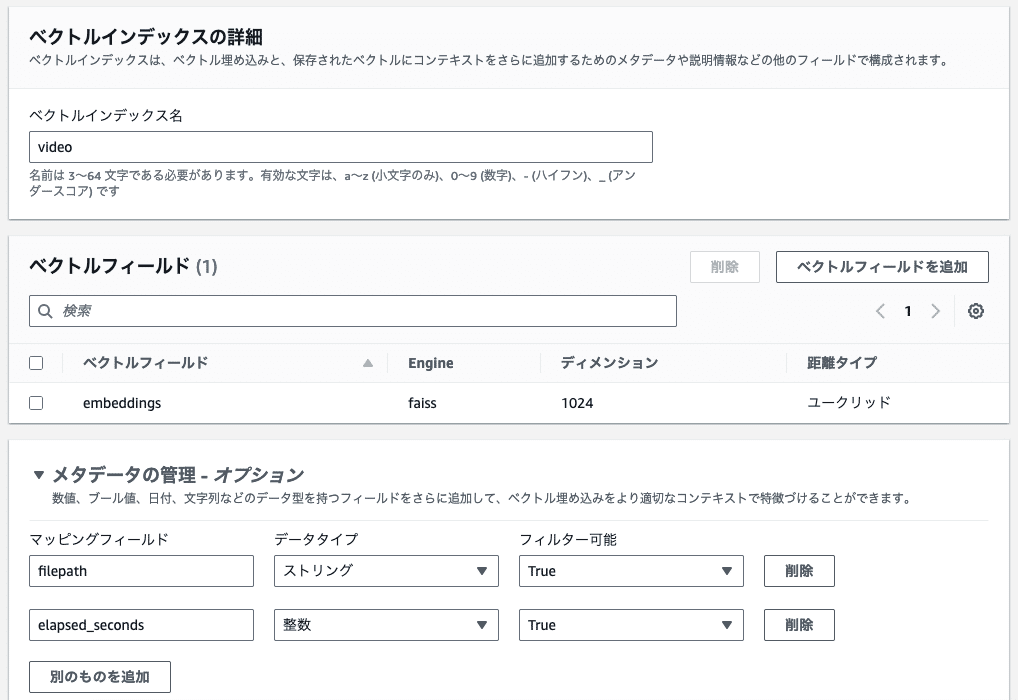
ボタンをクリックして遷移した先のページで、インデックスに入れるデータの構造を定義します。
スナップショット画像のEmbeddingsと、動画のファイルパスと、経過秒数のフィールドを追加します。
Lambdaカスタムレイヤー
ここでの手順は、Developers IOさんのFFmpeg をカスタムレイヤーとして Lambda 上で動かしてみたという記事と、AWS公式ドキュメントのPython Lambda 関数で .zip ファイルアーカイブを使用するというページを参考しています。
動画からスナップショット画像を取得するためのffmpeg、Titan Multimodal EmbeddingsのAPIを呼び出すための最新バージョンのboto3、OpenSearchを利用するためのopensearch-pyなどを含んだカスタムレイヤーを作成します。
以下のコマンドで、これらを含むzipファイルを作ります。
# zipファイルにffmpegのバイナリを追加
wget https://johnvansickle.com/ffmpeg/releases/ffmpeg-release-arm64-static.tar.xz
tar xvf ffmpeg-release-arm64-static.tar.xz
mkdir -p jigadvcal20231218_layer/bin
cp ffmpeg-6.1-arm64-static/ffmpeg jigadvcal20231218_layer/bin
cd jigadvcal20231218_layer
zip -r ../jigadvcal20231218_layer.zip .
# zipファイルに最新のboto3とopensearch-pyなどを追加
mkdir python
pip install --target python boto3 opensearch-py requests-aws4auth
zip -r ../jigadvcal20231218_layer.zip pythonS3にアップロードし、 AWSコンソールのLambda > レイヤーのページからカスタムレイヤーを作成します。

保存処理Lambda関数
AWSコンソールのLambdaのページから保存処理Lambda関数を作成します。

作成されたLambda関数の詳細ページを開き、「 Layers (0) 」からLambda関数に先ほど作成したレイヤーを追加します。
(実験のために何回もレイヤーを作り直したのでバージョンが4になっていますが気にしないでください)


続いて「+トリガーを追加」から、S3に動画ファイルが保存されたらLambda関数が呼ばれるように設定します。

タイムアウトとメモリ割り当ては大きめに。

環境変数に、OpenSearchコレクションのエンドポイントのURLを設定します。

Lambda関数本体のコードは以下のようになります。
とりあえず動けばいいというのを最優先で、AWSコンソールで作業するのに使っているIAMユーザのキーをベタ書きしてしまっていますが、本番運用するならこんな真似はしないほうがいいでしょう。
import base64
import json
import os
import shutil
import subprocess
import tempfile
from contextlib import contextmanager, AbstractContextManager
from typing import Any
import boto3
from opensearchpy import OpenSearch, RequestsHttpConnection
from requests_aws4auth import AWS4Auth
REGION_NAME = "us-east-1"
AWS_ACCESS_KEY_ID="AKIXXXXXXXXXXXXXXXXX"
AWS_SECRET_ACCESS_KEY="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
session = boto3.Session(
aws_access_key_id=AWS_ACCESS_KEY_ID,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY
)
bedrock_runtime = session.client("bedrock-runtime", region_name=REGION_NAME)
s3 = session.client("s3", region_name=REGION_NAME)
credentials = session.get_credentials()
awsauth = AWS4Auth(
credentials.access_key,
credentials.secret_key,
REGION_NAME,
"aoss",
session_token=credentials.token
)
AOSS_HOST = os.environ["AOSS_HOST"]
open_search = OpenSearch(
hosts=[{"host": AOSS_HOST, "port": 443}],
http_auth=awsauth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection,
timeout=300
)
def lambda_handler(event: dict[str, Any], context: Any) -> dict[str, Any]:
# S3イベントからバケット名とキーを取得
bucket_name = event["Records"][0]["s3"]["bucket"]["name"]
key = event["Records"][0]["s3"]["object"]["key"]
with tempdir() as movie_tempdir:
# S3からファイルをダウンロード
movie_filepath = os.path.join(movie_tempdir, os.path.basename(key))
s3.download_file(bucket_name, key, movie_filepath)
with tempdir() as snapshot_tempdir:
# 10秒ごとのスナップショットを生成
subprocess.run(["ffmpeg", "-i", movie_filepath, "-vf", "fps=1/10", os.path.join(snapshot_tempdir, "%04d.png")])
# スナップショットのEmbddingsを計算し、OpenSearchベクトルエンジンに登録
seconds = 0
for filename in os.listdir(snapshot_tempdir):
embeddings = embed_image(os.path.join(snapshot_tempdir, filename))
filepath = f"s3://{bucket_name}/{key}"
add_video_to_index(embeddings, filepath, seconds)
seconds += 10
return {
"statusCode": 200,
"body": "OK"
}
def embed_image(filename: str) -> list[float]:
with open(filename, "rb") as f:
input_image = base64.b64encode(f.read()).decode("utf8")
body = json.dumps(
{"inputImage": input_image}
)
response = bedrock_runtime.invoke_model(
body=body,
modelId="amazon.titan-embed-image-v1",
accept="application/json",
contentType="application/json",
)
response_body = json.loads(response.get("body").read())
return response_body.get("embedding")
@contextmanager
def tempdir() -> AbstractContextManager[str]:
dirpath = tempfile.mkdtemp()
try:
yield dirpath
finally:
shutil.rmtree(dirpath)
def add_video_to_index(
embeddings: list[float],
filepath: str,
elapsed_seconds: int
) -> None:
open_search.index(
index="video",
body={
"embeddings": embeddings,
"filepath": filepath,
"elapsed_seconds": elapsed_seconds
}
)検索処理Lambda関数
検索処理Lambda関数を作成します。
言語、CPUアーキテクチャ、レイヤー、環境変数、タイムアウト、割当メモリは保存処理Lambda関数と同じものを設定します。

コードは以下のようになります。例によって、キーをベタ書きしてしまっています。
import json
import os
from typing import Any
import boto3
from opensearchpy import OpenSearch, RequestsHttpConnection
from requests_aws4auth import AWS4Auth
REGION_NAME = "us-east-1"
AWS_ACCESS_KEY_ID="AKIXXXXXXXXXXXXXXXXX"
AWS_SECRET_ACCESS_KEY="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
session = boto3.Session(
aws_access_key_id=AWS_ACCESS_KEY_ID,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY
)
bedrock_runtime = session.client("bedrock-runtime", region_name=REGION_NAME)
credentials = session.get_credentials()
awsauth = AWS4Auth(
credentials.access_key,
credentials.secret_key,
REGION_NAME,
"aoss",
session_token=credentials.token
)
AOSS_HOST = os.environ["AOSS_HOST"]
open_search = OpenSearch(
hosts=[{"host": AOSS_HOST, "port": 443}],
http_auth=awsauth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection,
timeout=300
)
def lambda_handler(event: dict[str, Any], context: Any) -> dict[str, Any]:
keyword = event["keyword"]
keyword_embeddings = embed_text(keyword)
result = search(keyword_embeddings)
return {
"statusCode": 200,
"body": json.dumps(result)
}
def embed_text(text: str) -> list[float]:
body = json.dumps(
{"inputText": text}
)
response = bedrock_runtime.invoke_model(
body=body,
modelId="amazon.titan-embed-image-v1",
accept="application/json",
contentType="application/json",
)
response_body = json.loads(response.get("body").read())
return response_body.get("embedding")
def search(keyword_embeddings: list[float]) -> list[dict[str, str]]:
result = open_search.search(
index="video",
body={
"size": 5,
"query": {
"knn": {
"embeddings": {
"vector": keyword_embeddings,
"k": 5
}
}
}
}
)
return [
{
"filepath": s["_source"]["filepath"],
"elapsed_seconds": s["_source"]["elapsed_seconds"]
}
for s in result["hits"]["hits"]
]動作確認
Pexelsというフリー素材サイトから適当な動画をダウンロードし、S3にアップロードします。

クライアントから検索用Lambda関数を呼び出すコードは以下のようになります。
import boto3
import json
def search(keyword: str) -> list[dict[str, str]]:
aws_lambda = session.client("lambda", region_name="us-east-1")
invocation_result = aws_lambda.invoke(
FunctionName="jigadvcal20231218_search",
Payload=json.dumps({"keyword": keyword}).encode()
)
payload = json.load(invocation_result["Payload"])
result = json.loads(payload["body"])
return result
いろんなキーワードで動画を検索してみます。
"tiger" の場合。
ちゃんとトラの動画が一番にヒットし、それに続いてライオンの動画がヒットします。
非常に良い感じですね。

"shark" の場合。
ドンピシャでサメの動画をS3に保存してあるのですが、代わりに魚の動画がヒットしました。
まあ、似てはいますね。

"dog" の場合。
ブルドッグの動画と柴犬の動画とシェパードの動画をS3に保存してあるのですが、ネコの動画がヒットしてしまいました。
にゃんてこった!

まとめ
この記事では、先日の AWS re:Invent 2023 で発表された Titan Multimodal Embedding と OpenSearch Serverlessベクトルエンジン を利用して、テキストで動画の内容を検索できるシステムを試作してみました。
Titan Multimodal Embeddingには、利用可能なリージョンが限られていたり、英語にしか対応していなかったり、試してみた通り精度が微妙そうだったりと課題が多くありますが、テキストによる動画の内容検索に利用できることが確認できました。
これからの、日本語対応や精度改善などの改良に期待します。
この記事が気に入ったらサポートをしてみませんか?