
レコメンドシステムの活用を考える③(補足編)

三菱UFJフィナンシャル・グループ(以下MUFG)の戦略子会社であるJapan Digital Design(以下JDD)でMUFG AI Studio(以下M-AIS)に所属する、田邊・石井です。
前回お話した「レコメンドシステムの活用を考える②(実験編)」では、ニュースレコメンドの既存手法のパフォーマンス検証や、レコメンドシステムのポイントについて共有をさせていただきました。
本記事では、「レコメンドシステムの活用を考える②(実験編)」の詳細のステップおよび具体例を、補足編として紹介します。
その際、自然言語処理で利用される用語などが出てくるため、3つの用語を紹介したうえで、実験のステップについてお伝えします。
用語のご紹介
用語①:単語のベクトル化
まずは「単語のベクトル化」についてです。
ニュース記事のタイトルをコンピュータに理解してもらうために、記事の各単語を数値で表現する必要があります。実験では、ベクトル化した単語から、最終的にニュースタイトルのベクトルを取得します。
ここでは、単語を数値ベクトルとして表現するとはどういうことかをイメージできるように一つの例を挙げて紹介します。
単語のベクトル化で特徴的な考え方として、単語の意味はそれ自身ではなく、周辺で利用される他の単語によって意味が付けられベクトル化される点があります。
※単語のベクトル化の手法となるモデルは様々ありますが、イメージしやすいようにカウントベースの手法の一部を記載しています。なお、実際の実験では推論ベースのword2vecモデルを利用しています。
例えば、以下の3つのニュース記事のタイトルがあった際に、各単語をどのようにベクトル化するかを見ていきます。
title1 = ['老後', 'の', '心配', 'を', '無くす', '方法']
title2 = ['年金', '制度', '改正', '、', '老後', 'の', '変化']
title3 = ['老後', 'と', '年金', 'を', '考える']
まず、全ての単語が他のどの単語と何回一緒に利用されているかをカウントし、以下の共起行列と呼ばれる表を作成します。
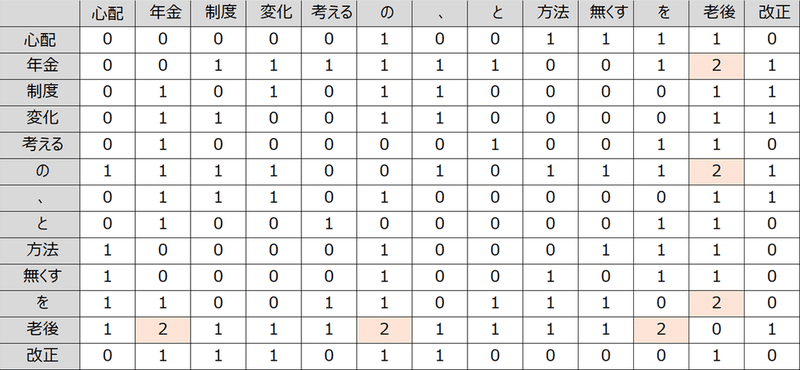
例えば、「年金」という単語は、「老後」という単語と使われる回数が2回、というような見方です。
次に、各単語の合計が1になるように計算し直します。
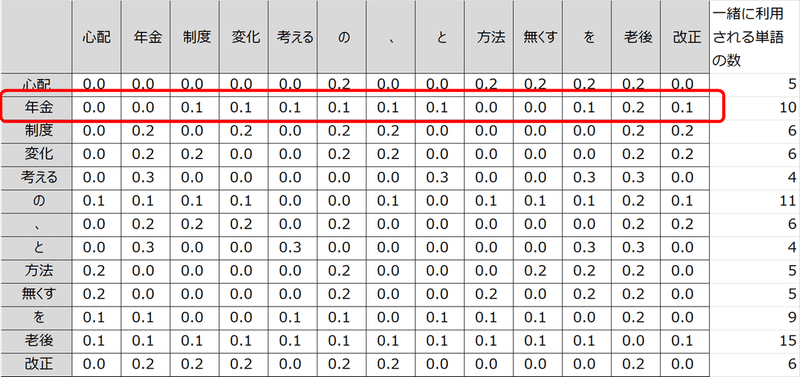
上記の赤枠で囲った部分は「年金」という単語のベクトルになります。
実際はもっと色々な工夫がありますが、このように各単語をベクトル化することができます。
注意点としては、単語の共起行列は集計時の単語集「コーパス」に依存するため、コーパスが異なれば単語の意味は異なってきます。なお、今回の場合title1~3がコーパスになります。
最後に補足ですが、単語のベクトル化は機械学習ではエンベディング(Embedding)と呼ばれます。
また、単語のベクトル化以外に文章をベクトル化する方法もあり、今回利用したモデルの参考論文では、文章をベクトル化した場合でも精度は出ています。
用語②:Attentionを利用した特徴量の取得
次に、機械学習の分野で有名なAttentionという機能についてです。
Attentionとは、データのどこに注目すればよいかをモデルに学習させる機能です。
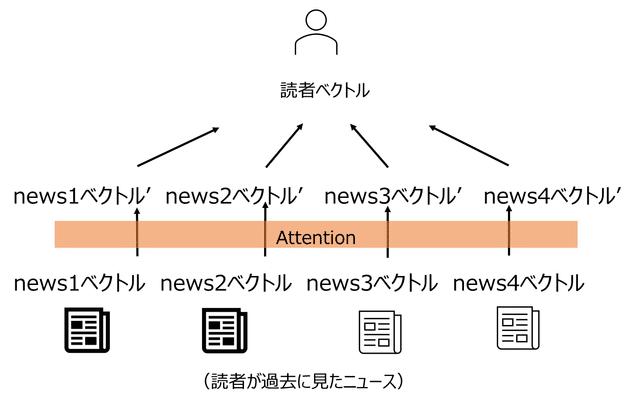
今回実験で利用したNRMSモデルでも、News記事や読者の特徴量を取得する際にAttentionを利用しています。ここでは、Attentionの役割がイメージできるように一つの例を挙げて紹介します。
例えば、次のようなタイトルのニュースがあった場合を考えます。
タイトル=['老後', 'の', '心配', 'を', '無くす', 'ため', 'に', '今', 'から', 'できる', 'こと']
「心配」は、「無くす」という否定単語によって心配でなはい(心配は無くせる)という意味になっています。
そのため、「心配」を理解する際には「無くす」に注目する必要があります。
Attentionを利用することで、以下のような各単語(単語ベクトル)の重みづけで「心配」を理解することが期待されます。
「心配」を理解する際に他の単語にどれくらい注目する必要があるかの重み=[0.1('老後'), 0('の'), 0.1('心配'), 0('を'), 0.6('無くす'), 0('ため'), 0('に'), 0.1('今'), 0('から'), 0.1('できる'), 0('こと')]
結果、心配’ベクトル(Attention後の「心配」という単語ベクトル)=0.1*老後+…+0.6*無くす+…0*こと、となり、他の単語も同様に表現することで最終的に以下のようにタイトルベクトルを計算できます。
タイトルベクトル(タイトル特徴量)=老後’ * w1+…+心配’ * w3+…+こと’ * w11
Attentionが無い場合、タイトル特徴量=老後 * w1+…+心配 * w3+…+こと * w11のような形でw1~w11は独立に学習することになります。
Attentionモデルを利用することで他単語との関係を明示的に考慮してどこに注目したらよいかを学習できるようにしています。
用語③:類似度からレコメンド対象を選定する
次に、類似度についてです。
Attentionを利用して求めたニュースタイトルのベクトルと、読者のベクトルの2つから、あるニュース1に対して読者Aがこのニュースを気に入るかどうかを判断します。読者のベクトルは、ニュースベクトルと読者の履歴を元に同様にAttentionを用いて取得します。
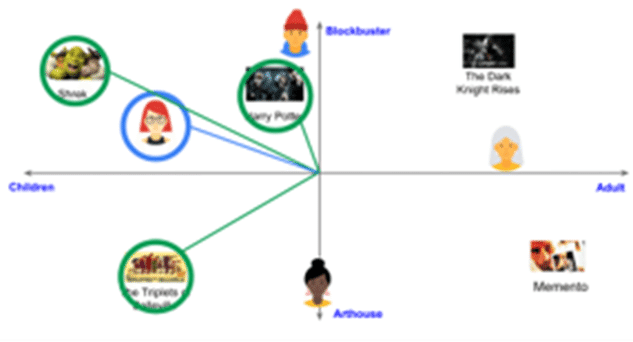
読者Aがニュース1を好むかどうかの判断は、類似度(近さ)で判断します。読者Aとニュース1は同じモデルを利用して取得されているため、2つのベクトル(特徴量)は比較でき、2つのベクトル(特徴量)の距離が近いほど似ているものとなり、同じ好みと判定します。
以下の図の例の場合、青枠が読者Aとなり、緑枠が読者Aの好みの映画と判断しています。
実験の各ステップについて
続いて実験の各ステップについて見ていきます。
(データ準備)読者に表示されたニュース情報と、各ニュースに対する読者のクリック情報を準備
(特徴量作成)ニュースの特徴量と、読者の特徴量を作成(今回は過去に参照したニュース情報から作成)
(スコア出力)ニュースと読者の特徴量の類似度からレコメンドするニュースを選択
(評価)類似度の高い順に読者に表示し、読者のクリック結果から評価
step1. データ準備
必要なデータとしては、①ニュース記事のタイトルと、②読者が過去に閲覧したニュースです。
具体的には、以下のようなデータを利用します。
①ニュース記事のタイトル
news_id, news_title
A001, デジタル化は何をもたらすか
D001, 関東大震災 被害を拡大させた“火の粉”の恐怖
B002, サンマ高騰に規格外野菜…猛暑・台風で“秋の味覚”に異変?②読者が過去に閲覧したニュース
user_id, user_clicked_news_history, user_clicked_news_label(正解ラベル)
user1, [A021, G901, F881], [B051-1, A723-0, F190-0, C031-0, D121-0, B220-0]
user2, [C141, D301, C024], [C051-1, A245-0, G277-0, G201-0, F531-0, C147-0]
user3, [A462, B671, G091], [B052-1, D144-0, F360-0, B551-0, A211-0, D645-0]step2. 特徴量作成
次に、データからニュース特徴量と読者特徴量を作成します。
各特徴量は、単語のベクトル化とAttention構造を利用して作成されます。
まずはニュース特徴量の作成です。
ニュースタイトルの各単語をベクトル化し、Attentionを利用して単語ベクトルを学習します。最後にモデルで学習した適切な重みをかけて、一つのタイトルベクトルとして作成します。
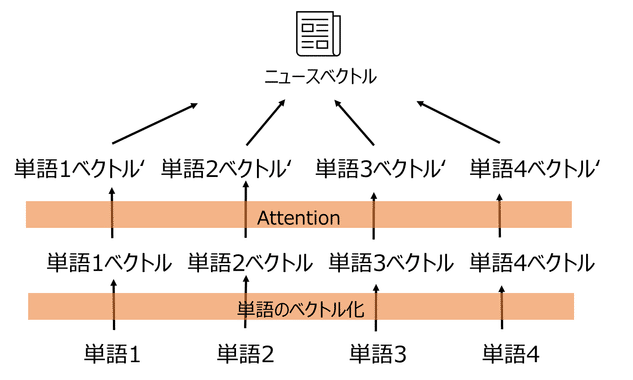
読者特徴量は、上記のニュース特徴量を利用して作成します。読者が過去に参照したニュースを先ほどのニュース特徴量と同様にベクトル化します。その後、各ニュース間の関係を考慮しAttentionを利用しながら、読者ベクトルを作成します。
step3. スコア出力
ニュース特徴量と読者特徴量を作成した後は、各読者に対してどのニュースに興味があるかを類似度から求めます。
例えば、読者Aがニュース「A001」「B002」に興味があるかを見る場合、各特徴量が以下だとすると
読者Aのベクトル:[0.07104776, 0.24611877, -0.0065576993]
ニュースA001のベクトル:[0.034561366, -0.18575591, 0.07443906]
ニュースB002のベクトル:[0.11301557, 0.44422676, -0.17580858]読者AとニュースA001の類似度は-0.84, 読者AとニュースB002の類似度は0.94となり、類似度の高いB002のニュースを読者Aは好むと判定します。
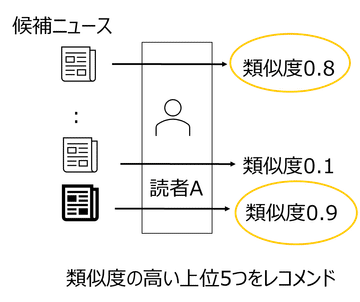
各ニュース記事と各読者の類似度を求め、類似度の高い上位5つをレコメンドします。
step4. 評価
レコメンドした結果、そのレコメンドが良かったかどうかは、幾つかの評価指標で評価できます。
今回はその中で一番シンプルな評価指標を紹介します。
MRR (Mean Reciprocal Rank)という指標で、レコメンドしたニュースリストの中で読者が最初にクリックしたニュースのみを評価するような指標です。読者がクリックしたニュースがレコメンドしたリストの上位にあればあるほど良いと評価をする指標です。
数式で表すとこちらです。
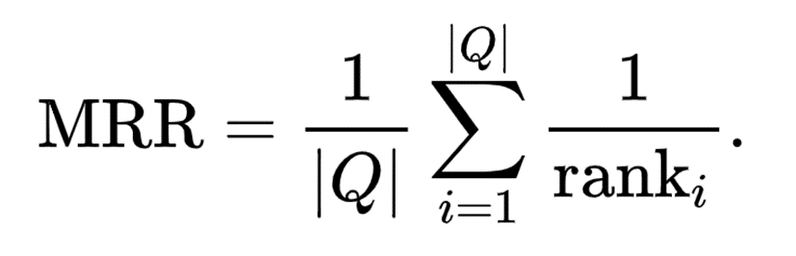
rank_iはユーザが最初にクリックしたNewsのレコエンドリスト内の順位を表し、|Q|は読者の総数(レコメンドリストの総数)を意味しています。
例えば、読者が3人おり、各読者に類似度が高い順に5つのニュースをレコメンドした場合を考えます。

1人目の読者はレコメンドリストの2番目のニュース(2番目に類似度の高いニュース)をクリックし、2人目の読者はレコメンドリストの3番目のニュース、3人目の読者はレコメンドリストの1番目のニュースをそれぞれクリックした場合のMRRは次のように計算されます。
MRR={(1/2)+(1/3)+(1/1)}÷3=0.6
3人目の読者は、1番おすすめとレコメンドしたニュースを最初にクリックしたため、MRRの評価としては一番よい 1/1となり、モデルの評価としては全読者の平均をモデルの評価としています。
以上が、実験の各ステップで行った内容となります。
「導入編」「実験編」「補足編」と長くなりましたが、読んでいただきありがとうございます。より具体的なイメージに繋がれば幸いです。
JDDのM-AISでは今回実施した検証のように、各々のデータサイエンティストが自身の興味に沿って決定したテーマの分析・調査を行うR&D活動に取り組んでいます。今後も不定期で活動報告を実施していきますので、次回の報告をお楽しみにしていただければと思います。
関連記事
最後に
Japan Digital Design株式会社では、一緒に働いてくださる仲間を募集中です。カジュアル面談も実施しておりますので、下記リンク先からお気軽にお問合せください。
この記事に関するお問い合わせはこちら
Japan Digital Design 株式会社
M-AIS
Naomi Tanabe
Chise Ishii