
Databricksで始めるLLMOps - MLflowを使ったトレース

三菱UFJフィナンシャル・グループ(以下MUFG)の戦略子会社であるJapan Digital Design(以下JDD)でTech PM(Technichal Project Manager)をしている吉竹です。Tech PMとして、プロジェクトのマネジメントや技術検証、アーキテクチャ設計等を行っています。
はじめに
皆さんは、大規模言語モデル(LLM)を使ったアプリケーションで、入出力値の追跡(トレース)を検討したり、その実装・分析方法に悩んだことは無いでしょうか?
通常のプログラムと異なり、LLMの出力は非決定論的に行われます。そのため、LLMの出力内容を把握・分析するためにも、従来以上に入出力値のトレースが重要となっています。このトレースを含め、LLMの開発や運用を効率的に管理する包括的なアプローチとして、LLMOpsという考え方が注目されています。
このブログではLLMOpsの入門として、OSSであるMLflowを使い、Azure OpenAIの入出力をDatabricksでトレースする方法をご紹介します。
LLMOpsとは
機械学習の分野では、従来からMLOps(Machine Learning Operations)という考え方が存在していました。MLOpsは、DevOpsの原則を機械学習プロジェクトに適用し、モデルの開発から展開、運用までのライフサイクル全体を効率化・自動化するためのプラクティスです。
LLMが普及するにつれて、MLOpsの考え方を拡張したLLMOps(LLM Operations)が提唱されるようになりました。LLMOpsは、LLMおよびLLMアプリケーションの管理、デプロイ、評価などを行う運用プロセスや実践に向けたプラクティスを意味します。具体的には、以下のような要素が含まれます。
モデルのデプロイメント管理
プロンプトのバージョン管理
モデルの評価
モデルのパフォーマンス監視
このように、LLMOpsは単なるトレースにとどまらない包括的なアプローチです。トレースだけではアプリケーションのログ記録や監視という限定的な目的にとどまりますが、トレースしたデータをデータプラットフォームと連携することで、データサイエンティストとの協働が促進され、高度なLLM運用の実現に繋がります。これは、LLMOpsの実践に向けたファーストステップと言えます。

なお、Google Cloudのブログでは「GenOps」という考え方も紹介されています。これは言語モデルに限らず、生成AI全般を対象とした運用管理の考え方であり、LLMOpsをさらに拡張した概念と言えます。
前提知識
本ブログでは、Databricks と MLflow を中心に取り上げますので、まずはこれらの概要を説明します。
Databricks
Databricksは、データの収集、分析、モデルのトレーニングなど、機械学習およびAIワークフローの全般を支援する統合データプラットフォームです。アメリカのDatabricks社によって開発・提供されています。
Databricks社は、分散処理フレームワークであるApache Sparkの開発者を中心に創設されました。そのため、DatabricksプラットフォームのコアコンポーネントにはApache Sparkが組み込まれています。
JDDでは、このDatabricksプラットフォームを採用しており、データサイエンティストによる分析やモデル開発といった業務で活用されています。
MLflow
MLflowは、機械学習のライフサイクル全体を管理するためのOSSです。モデルのトレーニング、パラメータの追跡、モデルのバージョン管理、デプロイメントの管理などMLOpsの実現に不可欠なタスクを統合的に行うことができます。
MLflowはDatabricks社を中心に開発されました。OSSですが、現在もDatabricks社が多くのコントリビュートをしています。
このことから、MLflowはDatabricksのコアコンポーネントとして組み込まれています。この組み込まれたMLflowの機能を、公式サイトでは「マネージドMLflow」と紹介しています。
Databricks/MLflowを検証する理由
LLMOpsツールの分野では、LangSmithやLangfuseが広く知られています。
DatabricksとMLflowは、昨今の生成AIブーム以前から存在していたツールですが、最近はLLM関連の機能を大幅に強化しています。
JDDでは以前からDatabricksプラットフォームを利用していました。そのため、既存環境を利用できるほか、データサイエンティストにとって学習コストの低いツールと言えます。このような理由から、本ブログではDatabricks/MLflowの検証を行いました。
実装例
前提
Databricksにデータを連携するには、DatabricksワークスペースのURLとアクセストークンを環境変数に設定する必要があります。これらの値は事前に用意・発行されているものとし、以降のコードでは環境変数が正しく設定されていることを前提とします。
# Databricks ワークスペースのURL
export DATABRICKS_HOST=https://xxx.cloud.databricks.com/
# Databricks のアクセストークン
export DATABRICKS_TOKEN=xxxx本ブログで紹介する機能には、2024/9/6時点でプレビュー・Experimental Status のものが含まれます。予告なく変更される可能性がありますので、必ず公式ドキュメントを確認ください。
概要
MLflowでLLMのトレースを行うには、2024/9時点で以下3つの方法があります。
Automated tracing: OpenAI, LangChain, LlamaIndexなどのライブラリと統合され、有効化するだけでトレースを有効化できる方法
Fluent APIs: デコレータ、関数ラッパー、コンテキストマネージャーなどを利用して、少量のコード変更でトレース機能を追加する方法
Client APIs: トレースを細かく制御するために、Low-levelなAPIを利用する方法
上から順に実装負荷が小さい方法です。
今回は、Automated tracing と Fluent APIs の2つを使いトレースを行います。トレースしたデータは、MLflowの機能によりDatabricksに連携されます。
本記事では、Client APIsについては言及しません。OpenAIライブラリの使用方法とは大きく異なるコードの記述方法が要求されるためです。
個人的な見解ではありますが、トレースのために特殊なコードの記述方法を採用することは避けるべきだと考えています。主な理由は以下の2点です。
1. LLMは現在も急速に進化しており、ライブラリの更新頻度も非常に高い。特殊な記述方法を採用すると、ライブラリのバージョンアップ時の確認や修正の負荷が高い。
2. トレース自体は、ユーザーに直接的な価値を提供するものではなく、LLM運用の改善のために導入するもの。トレースの実装が原因で開発や保守効率が低下してしまうと、本末転倒な結果になる。
これらの理由から、できるだけ標準的なコードの記述方法を維持することが重要と考えています。
また、公式ドキュメントではAzure OpenAIの例はありませんでしたが、OpenAIと同様の方法でトレースが可能でした。エンタープライズ領域においては、Azure経由で利用することが多いと思いますので、サンプルコードもAzure OpenAIとしています。
バージョン情報
Python 3.11.9
mlflow 2.16.0
openai 1.40.8
方法1. Automated tracing によるトレース
まずは、Automated tracing(自動トレース)の方法を使ったサンプルコードを紹介します。
Databricks へのデータ連携に関する設定も必要ですが、基本は mlflow.openai.autolog() の1行を追加すればトレースが行われます。
import mlflow
from openai import AzureOpenAI
# Databricksへのデータ連携に関する設定
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("<Databricks上のデータ保存パス>")
# 自動トレーシングの有効化
mlflow.openai.autolog()
client = AzureOpenAI(
azure_endpoint="<Azure OpenAIのエンドポイント>",
api_key="<Azure OpenAIのAPIキー>",
api_version="2024-05-01-preview",
)
response = client.chat.completions.create(
model="<デプロイしたモデル名>",
messages=[
{"role": "user", "content": "あなたの名前を教えて下さい"},
],
)
print(response.choices[0].message.content)トレースの結果を Databricks のUI上で確認します。
Experiments から Traces タブを選択すると、実行された結果が一覧で確認できます。(ここでは、mlflow-sandbox というフォルダに保存しています)
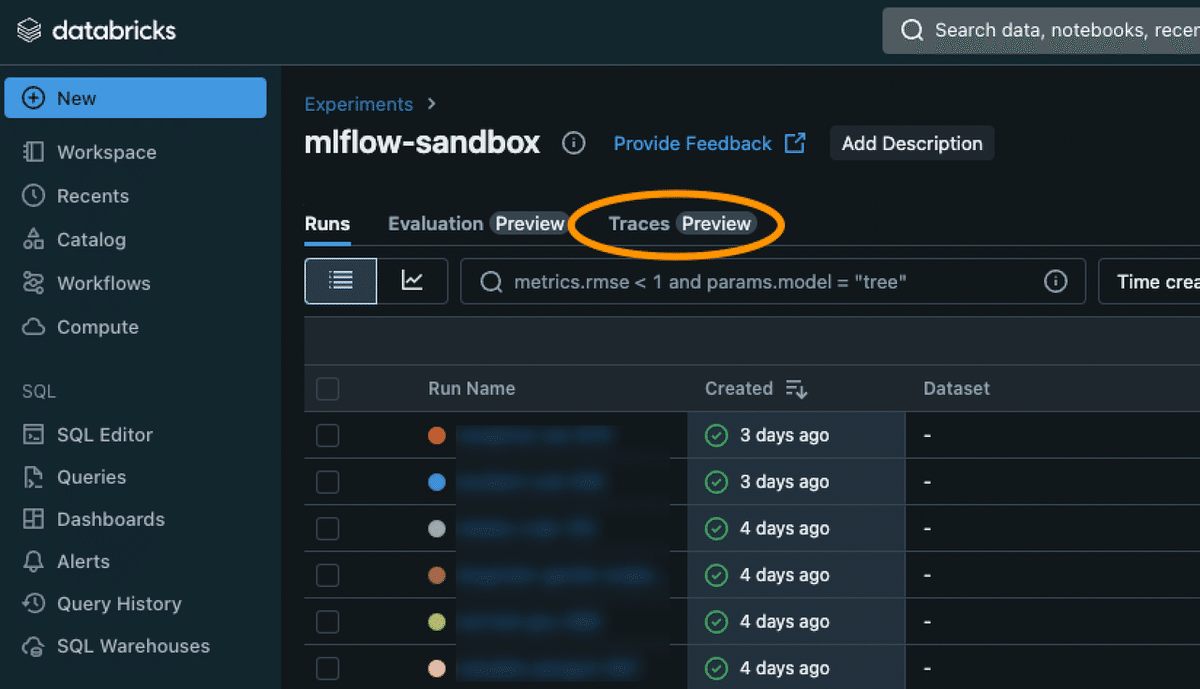

表示された Request ID を選択すると、LLMへの入出力データが確認できます。出力のみでなく、実行時間やChat Completions API のレスポンスに含まれる利用トークン数やフィルター結果も確認が可能です。


自動トレースを使うと、簡単なコード修正で Databricks と連携できることがわかりました。
方法2. Fluent APIs によるトレース
次に、Fluent APIsを使った方法を紹介します。Fluent APIsにより、以下のようなトレースが可能となります。
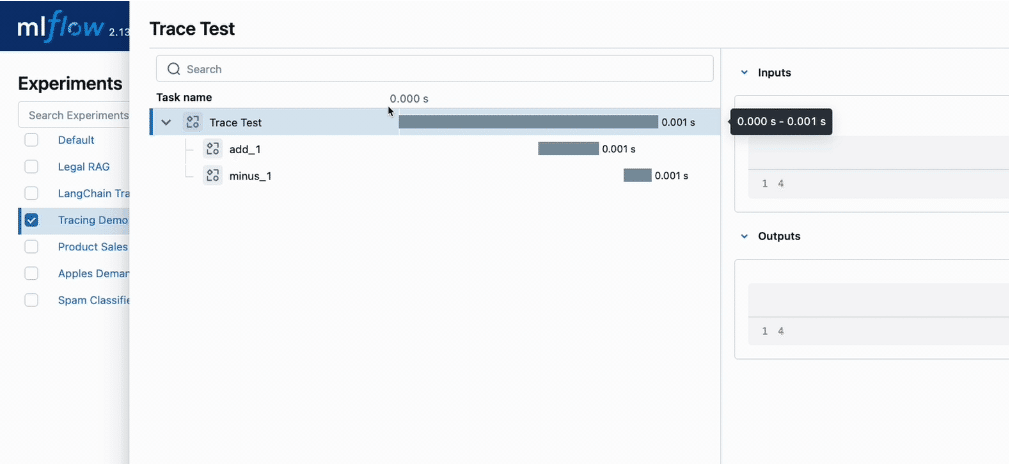
関数の親子関係を扱ったトレース
デコレータを利用すると、Python内の呼び出し順序に応じてトレースが処理されます。これにより、関数の親子関係をトレースに反映することが可能になります。
非同期でのトレース
デフォルトでは、MLflowのトレースは同期的に実行されます。すなわち、データの送信先(今回はDatabricks)との通信が発生するため、パフォーマンスのオーバヘッドが発生する可能性があります。
MLflow 2.16.0 以降で非同期でのトレースが実装されました。Automated tracing では未対応のようなので、非同期トレースを使うにはFluent APIsまたはClient APIsを使う必要がありそうです。
なお、非同期でのトレースを有効化すると約80%のオーバーヘッドが削減できるが完全に無くなるわけではない、という旨が公式ドキュメントには記載されています。前提を確認される場合は、必ず公式ドキュメントをご確認ください。
サンプルコード
サンプルコードは以下の通りです。Fluent APIsのデコレータを使っています。関数化していますが、コード内容は「方法1」のサンプルと違いありません。
import mlflow
from mlflow.entities import SpanType
from openai import AzureOpenAI
# 非同期トレースの有効化
mlflow.config.enable_async_logging()
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("<Databricks上のデータ保存パス>")
# デコレータの追加
@mlflow.trace(name="call Azure OpenAI", span_type=SpanType.CHAT_MODEL)
def call_azure_openai(message: str) -> str:
client = AzureOpenAI(
azure_endpoint="<Azure OpenAIのエンドポイント>",
api_key="<Azure OpenAIのAPIキー>",
api_version="2024-05-01-preview",
)
response = client.chat.completions.create(
model="<デプロイしたモデル名>",
messages=[
{"role": "user", "content": message},
],
)
return response
# デコレータの追加
@mlflow.trace(name="Fluent API Test")
def main():
message = "あなたの名前を教えて下さい"
res = call_azure_openai(message)
print(res.choices[0].message.content)
if __name__ == "__main__":
main()コードを実行すると、同じくDatabricksにトレースデータが連携されます。関数のデコレータにより、コードのmain関数 Fluent API Test からsub関数である call Azure OpenAIの親子関係が扱えるようになりました。
「方法1」ほどではありませんが、こちらも簡単な修正でDatabricksと連携できることがわかりました。

補足として、Fluent APIは関数の入出力をトレースするため、関数のレスポンスを変更すればそのデータがDatabricksに連携されます。前述のコード例で言えば、call_azure_openai 関数のレスポンスを response.choices[0].message.content (出力されたテキストメッセージ)に変更した場合、Databricksに連携されるのも content のみです。
本番での利用に向けて
簡単なコード変更でトレースを行えることがわかりましたが、本番を見据えて利用するにはいくつかの懸念があります。主に非機能の観点から、考慮すべき設計ポイントや今後のアップデートを期待する点を紹介します。
セキュリティ
トレースデータのセキュリティ管理は、LLMOpsにおいて極めて重要な要素です。
データの性質や運用環境にもよりますが、仮に本番データを扱う場合には、厳格なセキュリティ措置が不可欠です。誰もがトレースデータへアクセスできてしまう状態は、データ漏洩や予期せぬリスクを招く可能性があるため許容されません。リスクを最小化するためには、許可されたメンバーのみがトレースデータを参照できるよう、アクセス管理を実施する必要があります。
Databricksはアクセス管理機能を提供していますが、セキュリティ要件によっては、より高度な対策が求められる場合があります。例えば、データの持ち出しを技術的に制限したり、データを適切にマスキングしたりするなど、多層的なセキュリティアプローチが必要となる場合もあります。
セキュリティは、LLMOpsやトレースを検討するにあたって、第一に検討するポイントと言えます。
可用性
「実装例 - 概要」でも述べましたが、トレースはユーザーに直接的な価値を提供するものではありません。そのため、トレースが失敗してもユーザーに影響が無ければ大きな問題にはなりません。逆に言うと、トレースの失敗がユーザーに影響することは避けるべきと筆者は考えています。
検証したところ、MLflow のトレースは、データ送信先(今回はDatabricks)が障害などで利用できない場合に Exception が発生する挙動に見受けられました。これは、トレースの失敗がアプリケーション自体のエラーに繋がることを意味します。
システムの可用性を保つためにも、トレースに失敗した場合でも無視できるようなアップデートに期待したい、と個人的に感じました。
このブログで紹介したMLflowでのトレースは従来のロギングを代替するものではありません。その理由は以下の通りです。
・トレースデータの送信先(Databricks等)とアプリケーションログの保存先(Amazon CloudWatch Logs等)はツールの目的が異なるため、権限管理やアクセスできるメンバーも異なる。
・トレースデータの送信先で障害が起きてデータが記録されていなかった場合、ログ自体が失われる。
以上から、トレースの実装後も引き続きアプリケーションのロギングや監視は必須と言えます。
パフォーマンス
前述の通り、非同期トレースは完全に同期的な処理になるわけではありません。
そのため、LLMの応答速度にどの程度影響があるか、プロジェクトやシステム、データの特性に応じた検証が事前に必要と考えられます。
その他
検証する中で、非同期トレースの挙動が不安定に感じました。具体的には、mlflow.config.enable_async_logging() を追加すると以下のようなエラーが出ることが多々ありました。
調べても直接的な原因がわからず、PCを再起動すると解消するなど明確な解消方法は見つかりませんでした。調査が不十分かもしれませんが、ライブラリ起因である場合にはこういった点の改善にも期待したいです。
▼エラー内容はこちら
Exception in thread MLflowTraceLoggingLoop:
Traceback (most recent call last):
File "/Users/user/.asdf/installs/python/3.11.9/lib/python3.11/threading.py", line 1045, in _bootstrap_inner
self.run()
File "/Users/User/.asdf/installs/python/3.11.9/lib/python3.11/threading.py", line 982, in run
self._target(*self._args, **self._kwargs)
File "/Users/User/.asdf/installs/python/3.11.9/lib/python3.11/site-packages/mlflow/tracing/export/mlflow.py", line 165, in _logging_loop
self._handle_task()
File "/Users/User/.asdf/installs/python/3.11.9/lib/python3.11/site-packages/mlflow/tracing/export/mlflow.py", line 180, in _handle_task
self._trace_logging_worker_threadpool.submit(_handle, task)
File "/Users/User/.asdf/installs/python/3.11.9/lib/python3.11/concurrent/futures/thread.py", line 169, in submit
raise RuntimeError('cannot schedule new futures after '
RuntimeError: cannot schedule new futures after interpreter shutdown最後に
このブログでは、LLMOpsの入門として、Azure OpenAIの入出力をMLflowを使ってDatabricksでトレースする方法を紹介しました。簡単に内容を振り返ると、以下の通りです。
LLMOpsは、LLMアプリケーションの管理、デプロイ、評価などを行う包括的なアプローチ
DatabricksとMLflowを組み合わせることで、ライブラリ本体のコードの記述方法を活かしつつ、簡単なコード修正でLLMアプリケーションのトレースが可能になる。
本番環境での利用に向けては、セキュリティ、可用性、パフォーマンス等の観点で、検討や今後の改善を期待する点が残っている。
LLMOpsはまだ発展途上の分野であり、今後さらなる進化を個人的にも期待しています。
長くなってしまいましたが、このブログがどなたかのお役に立てば幸いです。
Japan Digital Design株式会社では、一緒に働いてくださる仲間を募集中です。カジュアル面談も実施しておりますので下記リンク先からお気軽にお問合せください。
この記事に関するお問い合わせはこちらにお願いします。
Japan Digital Design 株式会社
Technology & Development Div
Naoki Yoshitake