
【Whisper文字起こし】M1 MacBook Air のローカル環境でYouTube動画の字幕を自動生成してみた

どーも、リュークです。
今回は音声認識の精度が高くて有名なWhisperを使って、音声データから字幕ファイルを生成して、YouTube動画に後付けする方法を解説していきます。
Google Colab を使ったやり方が一般的ですが、無料版だと時間帯によって変動する制限が設けられているため、ローカル環境で実行できないか試してみたら、重たいながらもなんとか動いてくれました。
「俺は好きな時に好きなだけwhisperを使いたいんじゃ!」て方は、参考にしてみてください。
環境
デバイスやツール
MacBook Air 2020 (M1, 16GB, 1TB, Venture 13.0.1)
Visual Studio Code 1.77.1 (Universal)
asdf v0.11.3
Python 3.10.0
ffmpeg 6.0
gradio 3.4.0
pip 21.2.3
torch 2.0.0
whisper (last commit: 0a2d1210bcb98978214bbf4e100922a413afd39d, date: Thu Mar 30 19:29:29 2023 +0200)
あった方が良いツール
GPT-4 (バグ解決やリファクタに重宝します)
DeepL (日本語字幕の英語字幕化に使えます)
背景
なぜ字幕が必要なのか?
そもそも何故、字幕が必要なのか?
レビュー動画といった、動画の映像ではなく、テキスト情報に価値があるコンテンツは、見る人のスタイルが多岐に渡ります。
ブログ形式で見たい人
ラジオとして聴きたい人
無音で動画を見たい人
日本語以外で見たい人
前者の2パターンに関しては、動画の原稿を note化したり、動画の音質を改善したりすれば実現できます。
さほど手間ではありません。
しかし、後者の2パターンに関してはニーズに対して必要な労力が大き過ぎるという問題があります。
最近はよくフルテロップのYouTube動画を見かけますが、字幕の量とタイミングを合わせながらテキストを打っていく作業は、一人で回しているYouTubeチャンネルでは、到底できないことです。
さらに、日本語で話している動画に英語の字幕をつけようとすると、翻訳の精度や文量によって字幕のタイミングも異なるので、さらに難易度が上がってしまします。
そこで登場するのが whisper です。
Whisper で実現すること

whisper を使うことで、音声データを解析して、自動的にテキスト化してくれます。
さらに生成されたテキストデータを変換して、タイムスタンプがついている字幕データ(XXX.srt)を生成することで、字幕ファイルに対応している動画編集ソフトでそのまま使えたり、YouTube Studio で後から字幕を追加することができます。
そして、生成された字幕データをDeepLなどの高精度な翻訳ツールに通すことで、英語字幕化もできてしまいます。
自分の動画をもっと幅広い視聴者層に見てほしい、海外の視聴者にも届けたい。
そんな方は是非やってみてください。
やりかた✍🏻
今回のやり方は自身のMacBookをホストとして、web アプリで字幕ファイルの生成を行います。
エンジニアの方は好きなエディタを使ってもらえればいいと思いますが、僕はVSCodeが好きなので、今回はVSCodeでのやり方を解説します。
1.Visual Studio Code のセットアップ
VSCode をまだインストールしてない人は、こちらからダウンロードして、インストールしてください。
合わせて Python をインストールしていきます。
僕はバージョン管理ツールに asdf を使っているので、以下のコマンドを叩いてインストールしていきます。
asdf install python 3.10.0
asdf global python 3.10.0今回 Python 以外にもいろんなツールを使ったので、未インストールのツールは適宜インストールして進めて下さい。(著者の動作環境はデバイスやツールに記載の通り)
VSCode起動させて Extensionsタブから python をインストールし、セットアップしてください。

READMEに必要なことはだいたい書いてあります。
必要に応じてググったり、chatGPTに聞けば、すんなりセットアップ出来ると思います。
僕は以下のブログを参考にしました🙏
2.コードの追加

適当な場所にsubtitle_generator.py(名前はなんでもOK)というファイルを作り、以下のコードをコピー&ペーストします。
// コメント の部分は簡易的な説明なので、不要な場合は消しちゃってください🙏
subtitle_generator.py
import gradio as gr
import whisper
import os
from pathlib import Path
import torch
// 毎回 whisper model をダウンロードすると時間かかるので
// 2回目以降で使いまわせるようにハンドリング
def load_whisper_model(model_name):
model_dir = Path("whisper_models")
model_path = model_dir / f"{model_name}.pt"
if not model_path.exists():
os.makedirs(model_dir, exist_ok=True)
model = whisper.load_model(model_name)
torch.save(model, model_path)
else:
model = torch.load(model_path)
return model
model = load_whisper_model("large")
// ここでテキストを生成
def create_textfile(video_name, sr, timelag):
results = model.transcribe(video_name, verbose=False, language="ja")
with open("transcribe.srt", mode="w") as f:
for index, _dict in enumerate(results["segments"]):
start_time = _dict["start"]
end_time = _dict["end"]
start_time += timelag
end_time += timelag
s_h, e_h = int(start_time//(60 * 60)), int(end_time//(60 * 60))
s_m, e_m = int(start_time//(60)), int(end_time//(60))
s_s, e_s = int(start_time % 60), int(end_time % 60)
f.write(
f'{index+1}\n{s_h:02}:{s_m:02}:{s_s:02},000 --> {e_h:02}:{e_m:02}:{e_s:02},000\n{_dict["text"]}\n\n')
return "transcribe.srt"
// web の UI
css = """
.gradio-container {
font-family: 'IBM Plex Sans', sans-serif;
}
.container {
max-width: 730px;
margin: auto;
padding-top: 1.5rem;
}
#gallery {
min-height: 22rem;
margin-bottom: 15px;
margin-left: auto;
margin-right: auto;
border-bottom-right-radius: .5rem !important;
border-bottom-left-radius: .5rem !important;
}
#gallery>div>.h-full {
min-height: 20rem;
}
"""
block = gr.Blocks(css=css)
with block:
gr.Markdown("subtitle generator")
with gr.Group():
with gr.Box():
with gr.Row(mobile_collapse=False, equal_height=True):
segment_length_slider = gr.Slider(
0.1, 2, label="segment length ratio", value=1)
timelag_slider = gr.Number(value=0, label="time lag (second)")
text_button = gr.Button("transcribe").style(
margin=False,
rounded=(True, True, True, True),
)
video = gr.Audio(source="upload", type="filepath", interactive=True)
transcribe = gr.File(label="Transcripts text file")
text_button.click(create_textfile, inputs=[
video, segment_length_slider, timelag_slider], outputs=[transcribe])
block.queue(default_enabled=False).launch(debug=True)
右上の Runボタン▶️を押すと…
しばらく待つと Terminalに こんな文字が出てくると思います。
Running on local URL: http://XXX.X.X.X:XXXX
To create a public link, set `share=True` in `launch()`.このURL(http://XXX.X.X.X:XXXX)をブラウザで開くと、こんな画面が出てきます。

あとはここに音声データをアップロードして transcribe を押すだけ。
3.データの用意
字幕を付けたい動画のファイルを開いて、オーディオのみを書き出します。

4.字幕データの生成
音声ファイルをアップすると、このような画面になります。
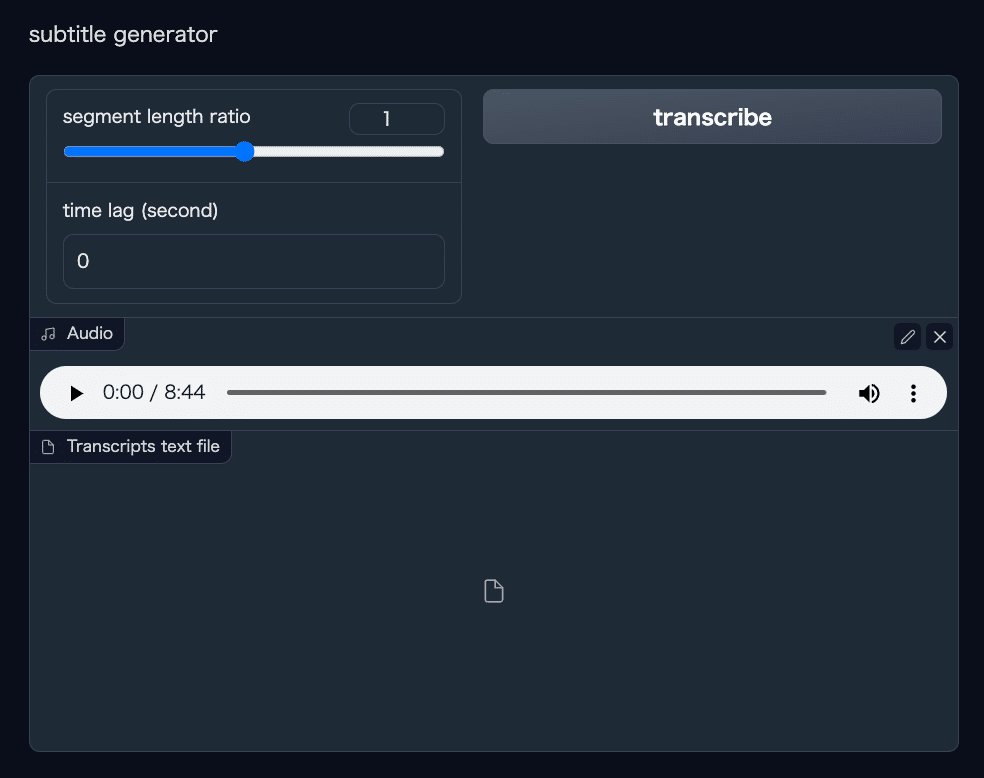
segment length ratio は字幕にする長さ(1回のテロップの長さ)の単位です。
各設定項目の詳しい説明は※この変換プログラムの作成者 AI VTuber にゃんた さんの動画をご覧ください。(Google Colab でのやり方)
※今回紹介しているプログラムは、著者の手により少し変更しています。
transcribe ボタンを押すと、処理が開始します。
処理は自身のMac上で行われるので、他の作業をしている場合はご注意ください(動作がもっさりします)

VSCode の terminal (頑張って書き出し中)
一般的にはGPUを使用する処理なのでCPUを使ってるのは気になるところ👀
改善できたらこの note に追記します。

700秒後くらい⏰
処理が終わるとダウンロードボタンが出現します。
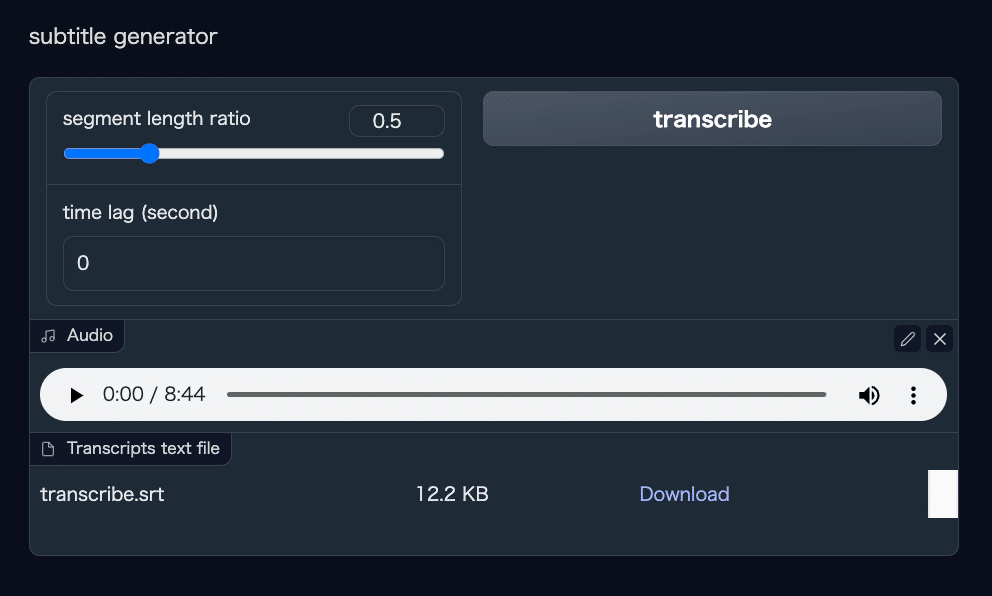
ダウンロードした transcribe.srt というファイルを開いてみると、こんな感じになっているかと思います。

生成されたテキストと、それが話されている時間がタイムスタンプになって順番に記載されています。
このファイルを動画編集ソフトや、YouTube Studio の字幕タブに追加することで、簡単にフル字幕化を実現できます。
5.YouTube Studio で字幕を設定
任意の動画を選択して、字幕タブから日本語を選択します。
YouTubeの自動翻訳機能で生成された日本語字幕とは別に追加するので、日本語(自動)が追加されていても新たに日本語字幕を追加します。
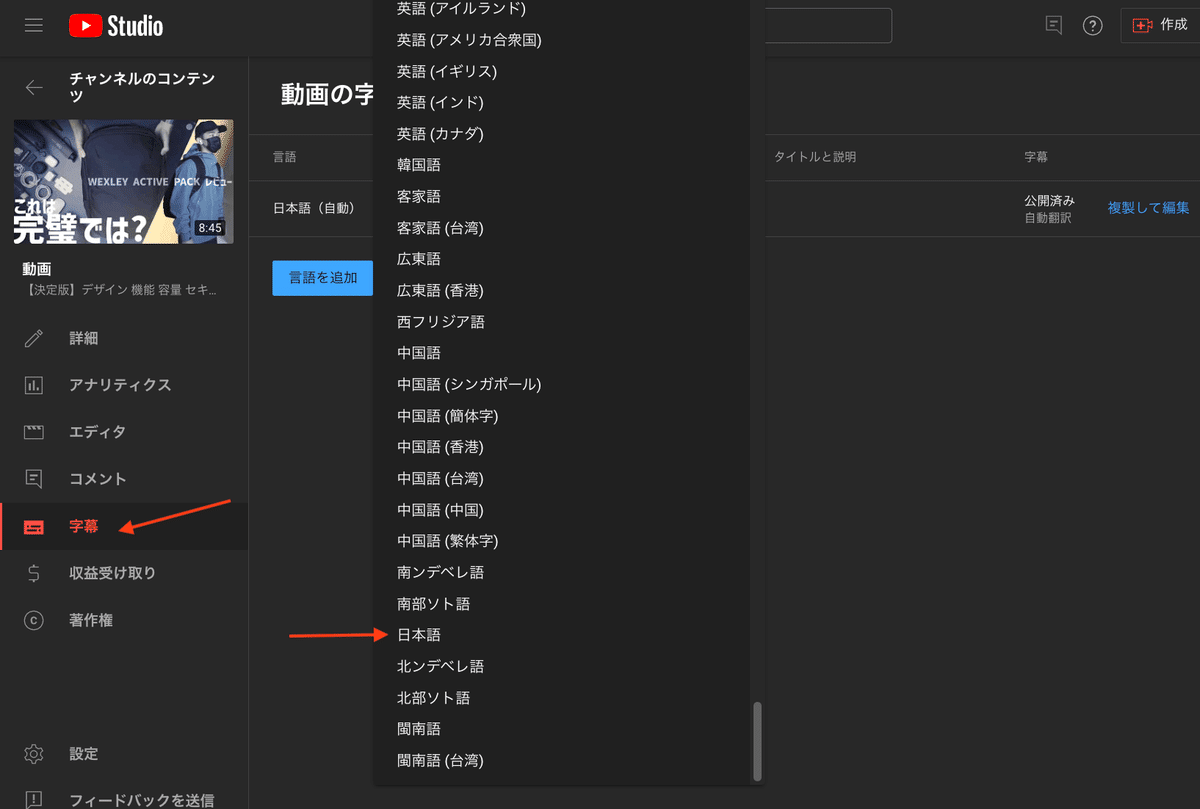
追加をクリック
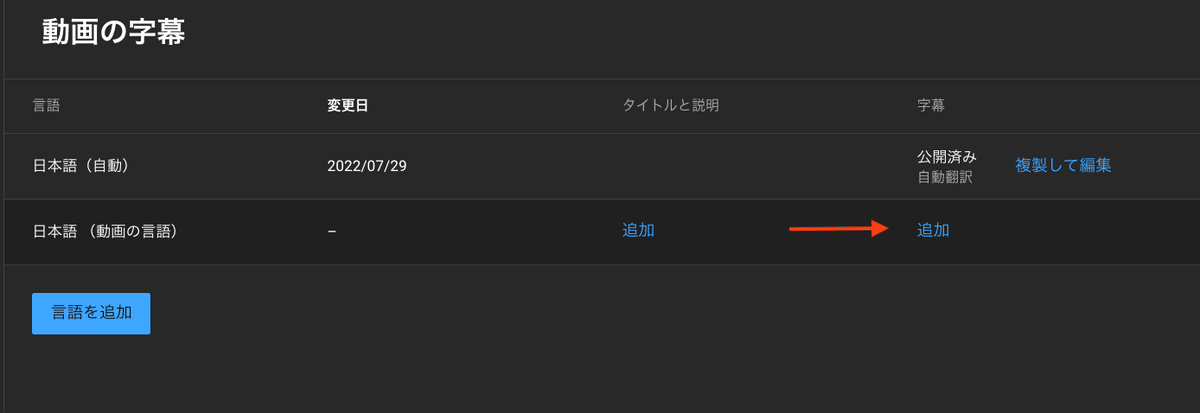
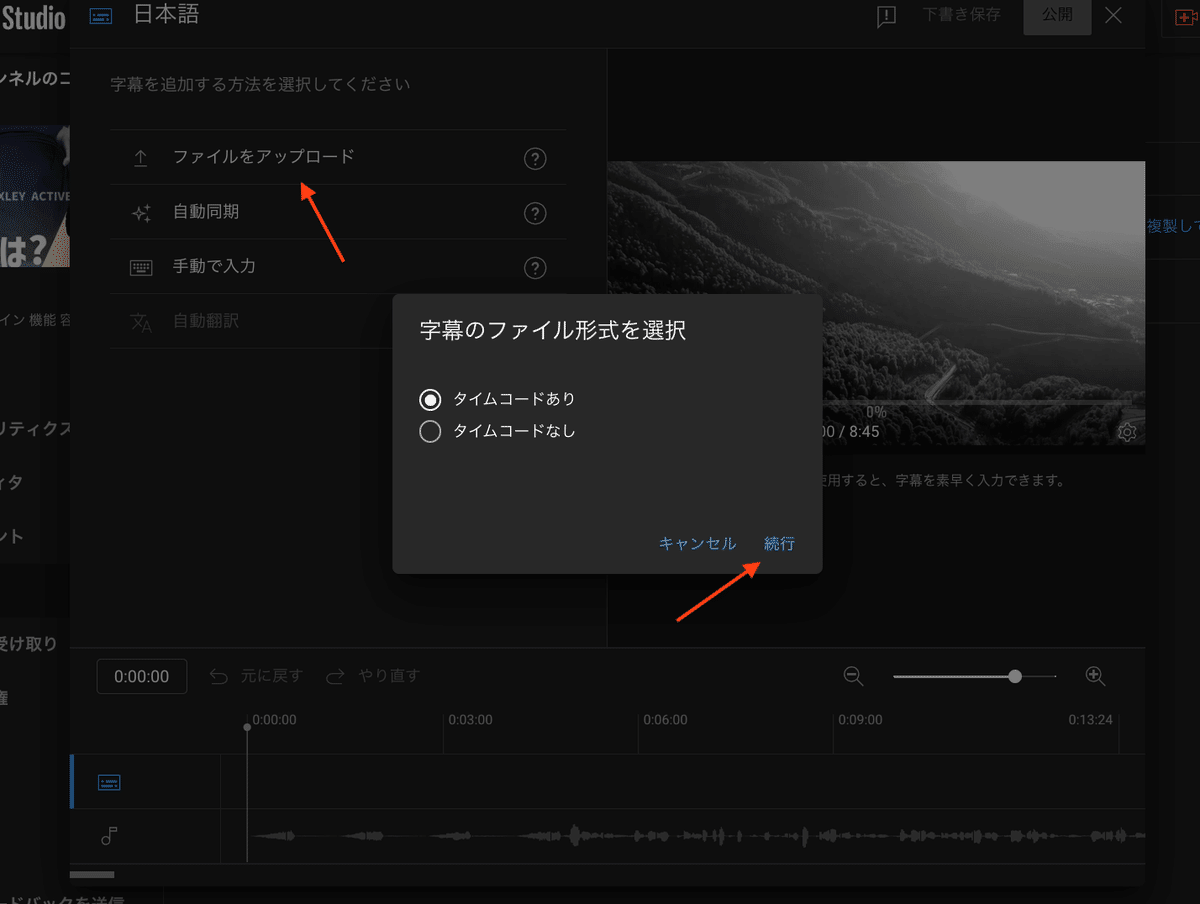
ファイルをアップロードから、先ほどダウンロードした transcribe.srt をアップします。
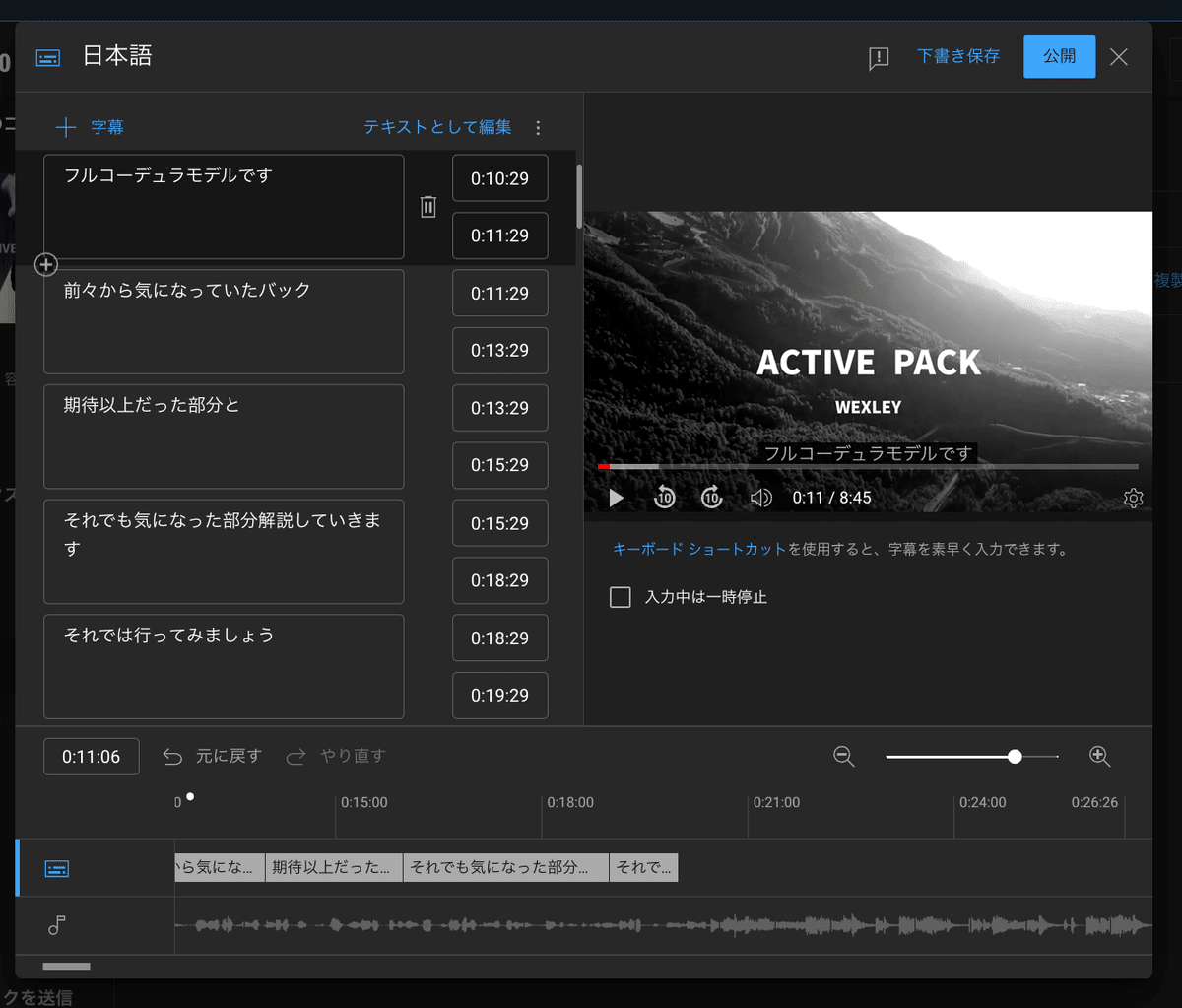
あとは必要に応じて微調整して完了です🚀
6.英語字幕の作成
英語字幕までGUIでサッと出力できたら理想なんですが、今回はDeepLを使った簡易的な方法に留めています。
やり方は簡単でDeepLに生成されたテキストをそのまま入れるだけです。

無料版だと3000文字までしか一気に翻訳できませんが、細切れにすれば翻訳できるので、無料版で十分かと思います。

1〜58までコピペして保存
59〜最後までもう一度翻訳(以後繰り返し)
10分くらいの動画なら2〜3回繰り返せば全て翻訳できました。
最後に
使ってみてわかったAIの楽しさ
今回初めて Python を触ったので、全体通して間違ったやり方や、不完全なコードもあるかと思います。
もっとこうしたほうが良いよ!って箇所があったら、是非教えて下さい!
GPT-4 に質問しながら、なんとか出力するところまで辿り着きましたが、基礎的な知識はまだまだ不足しているので、これからもっと Python や機械学習について知りたいと思いました。
また、本業のアプリ開発で、ここ半年ほどフォーカスしている Flutter と組み合わせたら、もっと面白いことができそうだなと思いました🚀
実際に僕が文字起こしする際は、基本Google Colabを使っています。
時間帯によって制限が設けられるので、Colabが使えない時のバックアップとして、ローカルで動く環境を作っておくのはお勧めできますが、かなり重たい処理をさせる行為なので、常用は控えたほうがいいかもしれません(マシンスペックお化けの人はその限りではない😈)
最後までご覧いただきありがとうございます!
ではまた〜👋
【Whisper 文字起こし】
— リューク | カバンの人 (@imigramrk) April 9, 2023
レビュー動画のフル字幕対応
着々と進行中🚀
英語字幕もサポートしてます😊
現在、以下の2つの動画で有効。
- Able Carry Daily Plus レビュー
- Remote Equipment The Alpha 31 レビュー#OpenAI #whisper pic.twitter.com/TCMLhBLvTH
👨💻著者の活動紹介
メジャーなものからマニアックなものまで
リュックやショルダーバッグなどを紹介するYouTubeチャンネル
ノーカットでバッグの細かな使用感が分かるYouTubeチャンネル
バッグのレビューや生活に役立つ情報の解説YouTubeチャンネル
Twitterで気軽に絡んでください🙋♂️
Instagram でお気に入りをピックアップ⭐️
TikTok もやってます!
Discord で好きなカバンやガジェットについて語り合おう!
この記事が参加している募集
よろしければサポートお願いします!より良い制作活動に活用させていただきます!