
YOUTRUSTでdbtを導入した話

初めまして。YOUTRUSTでデータアナリストをしている宮﨑(@ikki_mz)です。
普段は、施策の効果見積もりや検証、ダッシュボード作成、KPI管理、分析基盤整備など、データにまつわる諸々の業務に携わっています。
今回は、YOUTRUSTでこの半年ぐらい取り組んでいた、dbt導入とDWH(Data Ware House)整備について、だいぶ整備が進んできて知見も溜まってきたので、これまでやってきたことや、得られたメリットについて書いていきます。
この記事は主に、次のような方に向けて書いています。 (既にdbtを導入している方には当たり前の内容になっているかもしれません)
・dbtを導入しようか迷っている人
・DWHをどういう構造にすればいいのか迷っている人
・YOUTRUSTのデータ分析環境に興味がある人
何か少しでも参考になることがあれば幸いです!
YOUTRUSTの分析環境
はじめに、現在弊社で整備・運用しているDWHの全体像をご紹介します。

副業で分析基盤まわりのお手伝いをして頂いている方からのアドバイスを受けつつ、データレイク層、ステージング層、コンポーネント層、モデル層、データマート層の5層に分けて整備を進めています。
DWH整備の使用ツールは基本的にBigQueryとdbtの二つで、可視化には主にMetabaseを使用しています。
簡単に各層の説明をすると、以下のような感じになります。

各層について、詳細に解説するのはまた別の機会にするとして、今回はdbt導入の歴史や、導入したことで得られたメリットについて話したいと思います。
YOUTRUSTのDWH整備の歴史
なぜdbtを導入したか?
YOUTRUSTでdbtを導入し、DWHの整備に本格的に取り組み始めたのは約半年前の2022年2月頃です。
当時は、データレイク層に溜まっているローデータを直接参照して集計していました。DWHの整備はほとんどしていない状態です。
そのため、よく使う集計ロジックは、ローカルに保存しているクエリを使いまわしたり、BigQueryのスケジュールクエリを使うというような運用でした。
当時は、そこまで使いづらいという感覚を持っていた訳ではありませんが、DWHがだいぶ整ってきた今振り返ってみると、かなり非効率なクエリを書いていたな、と思います。非効率なクエリは、集計ミスをする可能性も高くなってしまうため、あらゆる点で問題が多く存在していました。
そんな中、データ界隈では「Modern Data Stack」やら「dbt」が話題になっていました。副業アドバイザーの方の助言もあり、弊社でも長期投資的にDWHを整備することを決めました。
これまでにやったこと
続いて、dbt導入を決めてからこの半年間でやったことを簡単に振り返りたいと思います。
DWHの整備は、最もデータレイク層に近いステージング層(entity, event)から進めました。entity, eventテーブルでは、データレイク層のデータに少し変更を加えたり、struct型に構造化して整理したりする程度の変更になります。

entity層の整備はかなり地味な作業で、ローデータとの差分もそこまで大きくはないため、得られるメリットが少ない作業でした。
そのため、dbtを導入して最初の1,2ヶ月はメリットをあまり感じられないまま、粛々とentity層の整備を行なっていました。
この辺りのフェーズは、労力に対して成果が出ないフェーズになるので、DWH整備はある程度長期的目線を持って進める必要があると感じます。
entity層によく使うテーブルがある程度揃ってきた段階で、次にユースケースに一番近いデータマート層の整備に着手しました。

ステージング層→コンポーネント層→モデル層→データマート層という順に開発するのではなく、データマート層の整備を先にした理由としては、実際にDWHの活用を意識しながら整備を行うことができるからです。
ステージング層→コンポーネント層→モデル層→データマート層と順番に整備を進めると、DWH整備のメリットをなかなか感じることができないので、
・メリットを感じることができず、作業モチベーションが下がる
・活用シーンをイメージできず、無駄なテーブルを生み出してしまう
というような問題が起き得ます。
一方でデータマート層はユースケースに直結しているため、
・「依存関係を処理してくれる」「テストができる」といった、dbtの価値を即座に体感することができる
・データマートを分析に活用しながら整備を行うので、必要なテーブルだけを揃えることができる
というようなメリットがあります。
弊社のデータチームは、フルタイムのデータアナリストは2人体制で、DWH整備もデータアナリストが行う必要があります。そのため、自分たちの分析作業が楽になる等のメリットを体感しながら進められたことは、とても良かったと思っています。
その後、データマート層に作成したテーブルを、コンポーネント層やモデル層に分解していくリファクタリングという形で、コンポーネント層やモデル層の充実を図っています。
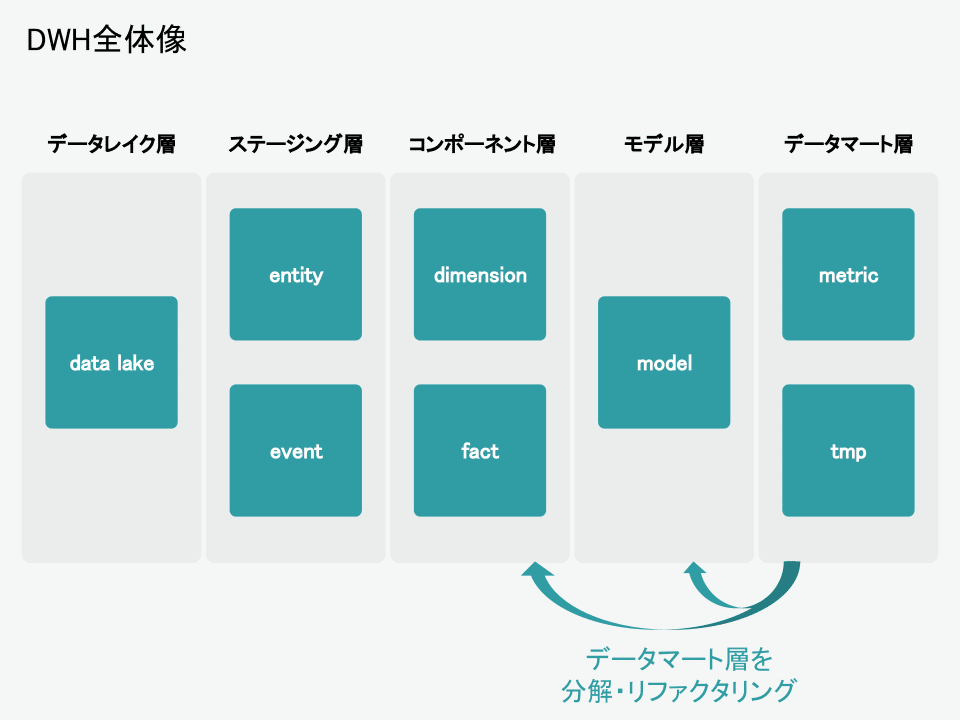
このように、常にユースケースを意識しながらDWH開発を行うことで、無駄なディメンションテーブルが乱立してしまったり、成果に直結しにくい作業に工数を無駄に割いてしまうリスクを最小限にできています。
現在、この辺りのdimensionやmodelテーブルを揃えるところは、まだまだ途中段階です。このまま放置するとデータマート層が肥大化してしまうため、分析業務の合間を縫って、DWH整備に時間を割くようにしています。
dbt導入とDWH整備で得られたメリット
以上が、dbt導入の背景と、これまでに進めてきたことの簡単な紹介になります。
続いて、dbt導入・DWH整備を通じて、感じられているメリットを3つ紹介したいと思います。
アドホッククエリの記述量が減った
dbtによってDWH環境を整備したことによる最大のメリットは、アドホック分析で記述するクエリがシンプルになったことです。
アドホック分析で何回も使用する指標やディメンションを、DWH環境に作ることで、同じようなクエリを何度も書く必要がなくなり、クエリがシンプルになりました。
例えば、とある指標をユーザーの属性(ex. 所属企業、職種、登録デバイスetc…)別に集計したいというシーンがあったとします。
従来であれば、これらのユーザー属性は別々のテーブルに散らばっていたり、算出ロジックをコピペしたりしていましたが、DWHのmodel層にuser関連のディメンションが全て集約されているテーブルを作ることによって、あらゆるユーザー属性での集計が簡単にできるようになりました。
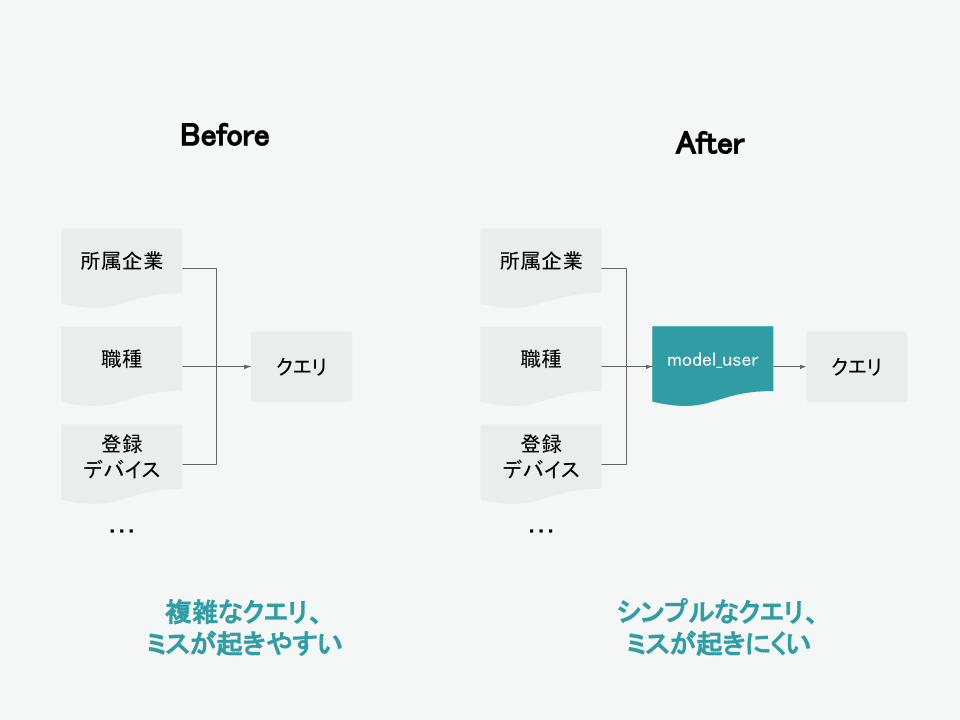
アドホックの記述量が減ることによるメリットは、単純にクエリを書くスピードが短くなるということだけでなく、クエリミスが減るとか、クエリミスを気にする精神的負担が減る、というようなメリットもあるので、全体的にクエリを書く作業が快適になったという実感があります。
集計ロジックの共通化
加えて、集計ロジックが共通化できることも大きなメリットの一つです。
改めて言うまでもない程にあるあるな問題として「各所でデータ分析が行われているが、同じ集計をしていても数値が一致しない」という問題があります。
弊社でも、さまざまな指標の数値が一致しないという問題はたまに起きていました。例えば、弊社YOUTRUSTのメンバーを集計に含めるかどうか、のような問題は、集計する人や目的によって判断が異なりがちです。
dbt導入後、主要な指標ロジックをGitHub管理するようになったので、誰がどういう意図で指標を作ったのかをアナリスト全員が確認することができます。また、この指標の定義を変更したい!という時も、Pull Requestを通して変更を行うので、独自の集計ロジックが乱立することを防げます。

クエリレビューの文化がついた
dbtのメリットというよりはGitHubのメリットなので、やや副次的な効果ではありますが、dbt導入後、メンバー間でクエリのレビューをする習慣がつきました。
dbtはGitHubでのクエリ管理を前提としたサービスであるため、必然的にクエリをレビューする機会が生まれました。dbt導入前は、クエリをレビューする機会はほとんどありませんでしたが、人間誰しもミスをゼロにすることはできないので、クエリのレビューを挟むことは重要だと思います。
全てのクエリに対してレビューを行っている訳ではありませんが、dbtで管理するような汎用的で重要なテーブルに関しては、アナリスト間でレビューをするようにしています。
今後の展望:データの民主化
今後の展望として、データの民主化にも繋げたい、という思いがあります。
現状、弊社ではクエリを書くのはデータアナリストと、非アナリスト数名という体制ですが、非アナリストが比較的簡単な集計をこなせるようになれば、アナリストが他の分析に時間を使うことができるようになるため、データの民主化は将来的に進めていきたいと思っています。
DWHの整備が進んでくると、分析でよく使うテーブルをモデル層やデータマート層に揃えることができるようになります。JOINをしなくても1つのテーブルから集計ができるようなテーブルが揃ってくると、非アナリストもデータ分析をしやすくなります。
まだまだ先の話にはなりそうですが、将来的に分析ができる人を増やすためにも、DWH整備への投資は続けていきたいと思っています。
おわりに
まだまだ事業のグロースフェーズにあるYOUTRUSTにおいて、短期目線で成果を出すだけでなく、長期目線でデータ基盤に投資を行えているのは、データアナリストとしてはかなり幸運だと思っています。
SNSというビジネス上、人と人とのつながりデータであったり、投稿などのテキストデータであったり、データ量が豊富でデータ活用の重要性も非常に高いビジネスです。なので、データ基盤に対しても積極的な投資を行うことができています。
一方で、DWH環境の整備はまだまだ不十分で、データ活用も完璧にできているということは全くないので、YOUTRUSTでのデータ分析に興味がある方はぜひ一度お話させて頂けると幸いです!
この記事が気に入ったらサポートをしてみませんか?