
無料から始める歌モノDTM(第19回)【調声編①調声の基礎】

はじめに
はじめましての方ははじめまして。ご存知の方はいらっしゃいませ。
ノートPCとフリー(無料)ツールで歌モノDTM曲を制作しております、
金田ひとみ
と申します。
お待たせしました。
今回からやっと【調声編】を始めます。
普段は考え方についてのお話がメインで、テクニック的なことはあまり触れてきませんでした。
しかしこと調声に関してはDTMerやボカロPの皆さまご興味がおありのようですので、拙いながらも書き進めて参りたいと思います。
初回ですのでまだ基礎的なお話と今後の流れの紹介が中心になりますが、ある程度歌モノDTM曲を制作できるという方も再確認の意味も込めてお付き合いくださいませ。
また始めたばかりで機能や用語が曖昧という方もいらっしゃると思いますので、調声って何なの?レベルのお話から解説していきます。
私が使っている歌声ソフトはAIシンガー「NEUTRINO」(ニュートリノ)シリーズです。
以前から紹介しておりますように、初音ミクを初めとしたボーカロイド系とAIシンガー系はそもそもの成り立ちが違いますので、調声うんぬんの手前、音声を分解→再合成して出力するという時点で仕組みが異なります。説明は【ツール編】でやりましたので今回は省きます。
ですので、AIシンガー系なら自動でやってくれることがボカロ系だと手動かもしれませんし、ボカロ系ならできる歌い方がAIシンガー系では暴走してできなかったりということもあるかもしれせん。
この点はご理解ください。
また、このnote記事は無料から始めるという趣旨ですので、「NEUTRINO」を使っての調声法は有料ソフトと比べると操作が不便だったり機能が十分でなかったりということもあるかもしれません。
そのあたりも何卒ご了承を。
出来る限り他AIシンガー系でもボカロ系でも応用の利きそうな歌声の一般的な面からの解説を心掛けますが、具体的な操作等については「NEUTRINO」とその「NEUTRINO調声支援ツール」、またNEUTRINOに歌わせるための楽譜を作成する「MuseScore」を使っての説明になります。
この点もよろしくお願いいたします。
DAWは「CakeWalk」を使っていますが、おおよそ基本的な機能や操作はどのDAWも共通ですので問題ないかと思います。
すでにNEUTRINOユーザーでより詳細を知りたいという方は、私以外のブログや動画等でも数多くの解説を見つけることができますのでそちらも併せてご参考ください。
質問等は答えられる範囲でコメントやTwitterで受け付けておりますが、実はそこまでエンジニアリング的なことは得意ではありません(汗)
どの分野でも専門の方がいらっしゃいます。
ただ一般的な面からの解説であるということはつまり、歌に関することを広く取り扱うということですので、もしかしたら「うたってみた」など歌に関わる活動をされている方や、私のように作詞作曲両方やっている方の参考にもなるかもしれません。
(カラオケも上手くなる?かも?いや、生身の人間は機械のようには調声できねんだわ。コツはつかめるかもだけど。)
【調声編】の大まかな流れとしては
基礎:(今回)調声そのものについて。以下の項目や用語の紹介
歌声:音声、音価・音高、トランジェント・アタック等について
発音:子音・母音、フォルマント、ピッチガチャ、ブレス等について
抑揚:ビブラート、コブシ、シャクリ、フォール等について
効果:エフェクター、ハモ等について
の5つを大枠として考えています。各回数など未定です。
各項目の代表的な用語までを今回でざっくり解説していきます。
一応項目や用語で分けてはいますが互いが密接に関わっていたりもしますので行ったり来たりしながらにはなります。
これらは私がDTMを始めてこの1年9カ月ほどで試行錯誤して得た現時点での情報ですので、間違いや未熟な部分あるかもしれませんがよろしくお願いします。
それでは始めます。
そもそも調声って何?
まずそもそもなお話。
「調声」=「歌声ソフトに上手に歌わせること」
とざっくり言われていますが、中身はいくつもの概念や作業がごっちゃになっています。
「上手に」の定義が曖昧だからです。
一般的に想定されるであろう狭い意味は、ナチュラルな発声が前提で、そこにブレスやビブラートを追加していくことですかね。NEUTRINO調声支援ツールでも基本機能です。
もう少し広げてシャクリなどの癖付け、早口や裏声、フォルマント調整による元気/優しいなんかのキャラ付けも調声に含めて問題ないかと思います。
さらにその先、エフェクターを使った初歩的なディエッサー処理やダイナミクス調整はどうでしょう。場合によってはやらないと耳障りになるので「上手い」と思わせるには必要かもしれません。
エフェクターと言えばイコライザーを積極的に使ったラジオボイス風な特徴付けは調声でしょうか? 効果的に「声」を「調えて」いるので一応調声に含めましょうか?
調声ツールやエフェクターだけで可能かは別にして、やくしまるえつこさんのようなウイスパーボイスや、マキシマムザホルモンのデスボイスはどういう扱いでしょう? 「上手い」かどうかは好みがあるので置いておいても、もしできたら「調声スゲー!」とはなりますね。
ハモりやダブリング、リバーブなどエフェクターの掛け方もボーカルの出来不出来に関わっていて「上手い」と感じさせますね。
コブクロのような美しいハモを多用する歌手は「上手い」と言われます。
エンヤ(Enya。アイルランドの歌手)のようなエコーエフェクトごりごりの歌手も心地良くて「上手い」ような気がします。
だとしたら広い定義ではアレンジやミックスの部分まで含まれるかもしれません。
……うーん(汗)
これらは「どこまでが調声なのか?」という方向性です。
逆に「どこからが調声なのか?」の広い定義をするなら何度か紹介した以下の自作品が良い例だと思います。
『レモンキャンディ』東北きりたん
この曲ではピッチガチャというテクニックをアウトロリフレインで段階的に掛けた以外は、NEUTRINO調声支援ツールでは何も手を加えていません。
音符に歌詞を当てはめて、音声合成ボタンをポチッと押して、DAW上で貼り付けただけ。つまりナチュラルな発声という最も狭い意味での調声は何もやっていない。
無調整豆乳ならぬ無調声投入(笑)
でも調声を施したような自然な歌い方になっているかと思います。
楽譜に歌詞を打ち込んで出力しただけでこのレベルなので、無料といえどNEUTRINOの性能の高さが伺えます。
では全く何もいじらずにやっているかとそうではなくて、このレベルの自然さに聴こえるまで何度もキーやテンポを変え音価(音符の長さ)を微調整してテストを行い、NEUTRINO東北きりたんが歌いやすい曲になるよう作曲時点から取り組んでいます。
ですのでこの場合、広い意味では作曲も調声ということになります。
さらに言えば、【作詞編】でも触れたように、どこにどんな歌詞を配置して、どの歌詞に対してブレスやビブラートを乗せるかによっても感情表現がより奥深いものとなり、「上手い」と感じさせることもある。
ということは作詞も調声と考えることもできます。
いやいや、そんなところも含めたら果てしなく道のりが遠くて無理〜!
と思われるかもしれませんが、逆にその歌声ソフトのシンガーが歌いやすい曲を最初っから作詞作曲できれば、特にAIシンガーの場合、あとは自動で狙い通りに歌ってくれるのでミリ秒単位の波形やコンマ数%単位のパラメータなんかとにらめっこする必要が無くなってよっぽど楽、と考えることもできます。
基本的には私はこっちの考えが主軸です。感覚としては「歌ってもらう」。
そのためには作詞作曲の段階から「調声」として手を加えることも多々あります。
しかし作詞作曲からミックスまで調声となるとさすがに範囲が広過ぎる。
歌モノ曲制作の過程ほぼすべてが調声に関わってしまう。
事実そうなんでしょうけれど【調声編】で取り上げるには話が大き過ぎる。
どこかで区切らないといけない。
さてどこで区切ろう?
調声は調教?
ちょっと極端な例まで挙げてみました。混乱してしまいますね。
冷静に考え直してみると、おそらく多くの方が抱いている調声の概念は、いわゆる
「調教」
のほうが近いのではないでしょうか。
すでにある程度完成した歌詞やオケの都合に合うように「歌わせる」。
語弊を恐れず言えば、矯正や強要です。
私個人としてはこれはモヤっとするし、今まで書いてきたこのnoteの方針「真価を見極め発揮する」とも合致していない。
しかし同時に、「歌わせる」ことがダメとも実は思っていません。
むしろ新しい発見に繋がることも。
そのシンガーが得意ではないと思い込んでいた曲を歌わせてみたら、予想外に良い歌い方だった!なんてことが起こり得ます。
前回【分析編】がまさにそうです。「バラードならめろうさん、セブンちゃんはアップテンポだけ」と思い込んでいたのが覆されたりするわけです。
「歌ってもらう」のか「歌わせる」のか、現実の歌手でも似たようなことがあります。
一昔前アニソンで大ブームになった『創聖のアクエリオン』。
菅野よう子さん大好き人間なのでその裏話を紹介します。
歌手のAKINOさんは実はオーディションで頭が真っ白になって上手く歌えなかったそうです。で、絶対落ちたなと。
ところが作曲者である菅野さんは彼女を押した。それが大ヒットに繋がった。
以降2作目では、菅野さんはAKINOさんがどこまで出せるか音を確かめながら作曲を進め、AKINOさんは菅野さんからアドバイスをもらいながらさらに高いキーや表現豊かな歌い方ができるようになった。
それはつまり歌ってもらう歌でもあり歌わせる歌でもあるということ。
菅野さんのことなので初めからAKINOさんの歌唱力を見抜いていたのかもしれませんし、ご本人も歌うことがあるので思い込みを越えて声を出せるコツを知っていたのかもしれません。
「上手に歌ってもらう」のか、「上手に歌わせる」のか。
こうなってくると個々人の「想い」や「考え」に関わる、どちらも調声を通した表現方法のひとつとも言えます。
そしていずれにしろ共通しているのが
「上手に歌う」
ということ。
最初に戻ってしまいましたが結局ところそれが調声です。
これは言い換えると
「歌が上手いとはどういうことか?」
に尽きます。
我々DTMerやボカロPがやるべきは、調声ツールの操作法を網羅したり、人間っぽく歌わせるテクニックを漠然と真似たりすることよりまず先に、
自分自身や視聴者が「歌が上手い」と感じる、あるいは反対に「歌が下手」だと感じる理由や特徴が何なのかを理解することです。でないと途中で調声の方向性を見失いかねません。
まずは、上手いと言われる歌手や自分がそう感じる楽曲を色々聞いてみるのが一番だと思います。作曲する際に参考曲を集めるのと似ています。
またその分析には今までの記事で書いてきたことが役に立つかもしれません。
その楽曲の中から「こんなふうに歌ってもらいたい/歌わせたい」と感じる理由や特徴を、今後の【調声編】で取り上げる項目や用語に沿う形で意識的に聞いてみるのが良いかと思います。
ナチュラルな歌い方や上手い歌手には、おおよそ理論的に説明できる法則のようなものがあります。
それと並行して目的に合致した操作法やテクニックを学んだほうが効率的です。
ただし、どういった歌が「上手い」と感じるかは人によって好みやその時々の流行りがあります。おおまかな法則はあるけれど絶対ではなく傾向のブレが存在する。
ひょっとしたらお使いの歌声ソフト自体がご自身の好みでない可能性も……。ボカロの機械的な感じがそもそも苦手という人もいますよね。
ここまで言い始めるとソフトの入手すら調声の一部になってしまいまそうなので、本筋に戻りましょう。
調声はおてつだい
もう一つの別視点から調声について考えてみたいと思います。
実はとてつもなく当たり前のことなのですが、AIシンガーにしろボーカロイドにしろ、その音声データの素はプロの声優や歌手です。
いわゆる中の人ですね。
(すべての中の人が明かされいるわけではありませんので、無名の方もいらっしゃるかもしれません。)
彼ら彼女らは声を仕事にしている人たちですので、我々一般人と比べると間違いなく声自体が良くて歌も上手いはずです。
少なくともボイストレーニングを行ったり色々な勉強をされて、それを実践されています。
ということは、中の人にそのまま歌ってもらえば当たり前に上手く歌ってくれる(……はず。「声が良い」と「歌が上手い」はまた別の話なので)。
ただ惜しくも?その中の人の良い声や歌を、一旦バラバラにデータ化してそれを再生し直しているのが歌声ソフト。劣化は避けられません。
そう考えると、調声とはできる限り元の声に戻す作業であり、
またできることなら元の声以上のパフォーマンスを発揮させてあげたり、ご本人が出せないかもしれない声や歌い方に変換させることとも言えます。
初音ミクの中の人の藤田咲さんはセルフで変換しちゃってますね(笑)
元の声とは別に初音ミクのモノマネ?もたびたび披露しています。
調声とは、ある意味プロのおてつだいとも考えられるわけです。
そのためにはバラバラになったデータをどのように組み立てていけば、元の音声やそれ以上のものに再生できるのかを知っておく必要があります。
これは言ってしまえばデータをいじる作業なわけで、調声するご自身がプロレベルに歌が上手い必要はありません。
そして作業であるなら手順があれば誰でも何度でも再現できる。マニュアルやレシピみたいなもんです。
作曲、作詞、歌唱は才能、みたいな風潮や研究はありますが、調声はそれに比べるとハードルが低い。おてつだいなので。
その代わりといってはなんですが、組み立て作業・手順が明確な以上、音声・歌声のルールを把握していないといけません。仕組みや決まり事です。
なんとなーくでは必ずしも上手くいかない。
感覚派より理論派の人のほうが得意かもと思っています。
ですので、私の【調声編】は感覚より理論が少しばかり優先です。
音楽理論はもちろんですが、音声学、言語学なども今までより登場回数が増えると思います。
ただ、私自身作詞作曲においては基本感覚派なので、それほど厳密なコンマ数%単位のパラメータ調節なんかは出てこないのでご安心ください。
てか私もそういうふうに解説されたところで多分100%は理解できないし再現もできない。音響エンジニアや歌唱研究者とかではない一般人です。
自身が特別に歌が上手い必要もなく、エンジニアや研究者ほど専門知識が必要でもない、その中間くらいで解説できればなと思います。
調声の基本
上手に歌うときどんな要素が絡んでいるのか、どんな法則があるのか、
また組み立て作業や手順にどのようなものがあるのか、
それが「はじめに」で上げた枠組みの項目やその内容です。
再掲します。
今回が基礎回でそれ以降は、
歌声:音声、音価・音高、トランジェント・アタック等について
発音:子音・母音、フォルマント、ピッチガチャ、ブレス等について
抑揚:ビブラート、コブシ、シャクリ、フォール等について
効果:エフェクト、ハモ等について
の順にしています。意味があってです。
【調声編】では音の三要素とされる、「音程」「音の大きさ」「音色」は一つずつの項目としてはピックアップしません。音の基本要素ですので他の項目との絡みが特に多く、相対的に定義が変わることもあります。
できる限りその都度の意味で使いますが、私も音響・音声のプロではありませんので厳密な用語ではなく平易なひとつのことばとして使う場合もあるかと思います。ご容赦ください。
今回は基礎回ですので一応簡単に解説しておきます。
音程(インターバル)は、インターバルの名の通り2つの音の高さの隔たりのことです。音階(スケール)で表される各音の高さですが、歌声の場合半音ずつの12音階にキッチリ分かれているわけではなく、なめらかな連続的変化を伴います。また例えば女声と男声で同じ音程でもオクターブ違う音域を初めから指していたりもします。【調声編】ではドの音なのかレの音なのかといったことより、周波数の高さやその隔たり、含まれる周波数の割合で説明していくことになります。
音の大きさ(ラウドネス)は、音量(ボリューム)の意味なのか、音圧(ダイナミクス)の意味なのか、歪みも含めた音質(エフェクトやクオリティー)として扱うのかなどで相対的に定義が変わります。同じ音量でも音圧が違うこともあります。それが声の力強さや太さ、はっきり聞こえるかどうかに関わってくることもあります。
音色(おんしょく、トーンカラー、timbreティンバー)は各歌声ソフトの元々の音声(ヴォイス)の特徴として考えておきます。単音で含まれる周波数や倍音による特徴を指しますが、連続で時間的に変化する歌声になると同じ「あ」の音声が前後の流れや音価・音高・音の大きさなどで変化する場合もあります。また歌声の場合この特徴を音質としてつまり声質と呼ぶこともあり、調声によってはこれも変化させることができます。
この音の三要素自体が密に関わり合っていて、どれかを変化させると他も一緒に変化する場合もありますので個別解説しにくいところがあります。
さて、
枠組みの項目とその内容に登場する用語が調声での主な概念です。これらの扱いで、歌の「上手い」「下手」、調声が上手くいっているかどうかが左右されると考えます。
例えばブレスやビブラートは調声でよく登場するテクニックですのでご存知かと思います。
NEUTRINOユーザーであればピッチガチャやフォルマントといった用語も見たことがあるのではないでしょうか。
音価・音高や子音・母音といったあたりが、言葉として知っていても一般的な調声法ではあまり目にしないかもしれません。
これらの定義や音声学など科学的な視点で見たとき実際に何が起こっているのかを把握して調声ツール等を操作している方はどれほどいらっしゃるでしょうか?
というか理解している方はこの記事を読む必要ないんじゃないかな、うん。
楽器音源の音色やその打ち込みテク、エフェクターの性能や掛け方についてこだわる人は多いと思いますが、歌声については、
なんとなーくフォルマントをいじったり、なんとなーくブレスを入れたり、なんとなーくビブラートを掛けたら、なんとなーく良さげになったなぁ、
くらいの方も多いのではないかと思います。
「歌が上手い」という定義が個々人の感性によるところも大きいのでそうなってしまうのでしょう。
反対にいくら手を加えてもちっとも良くならないことも。
また各歌声ソフトの性能や機能によるところも大きいので、ほんの少しの調声で済むこともあれば膨大な操作が必要な場合もあります。
音源プラグインの性能差みたいなものですね。
私の経験上ですが、AIシンガー/ボカロ調声に関する情報をネット上で探しても各歌声ソフトごとのテクニック的なものは見つかれど、歌声ソフト全般にまで広げたテクニックや科学的知見から分析された解説となるとなかなか数が少ない。
楽器音源の打ち込みテクニックやエフェクターの掛け方なんかは、多少の性能差はあれどどのプラグインやどのDAWでも共通する基本操作があるのに、調声についてはあまり無い。
音声合成技術的な観点から、つまりAIシンガー/ボカロそのものを作る側の情報はちょこちょこあります。最新技術が惜しげもなく解説されています。
でも欲しいのはその出来上がっているソフトを使って上手に歌ってもらう/歌わせる側の情報です。それも各ソフトごとに限定された特有の操作機能や特殊テクニックではなく歌声全般に共通するもの。
でないと、特別な機能を持った高価な有料ソフト以外選択肢が無くなり、歌声ソフトを使った音楽活動が金持ちの道楽かPC音楽オタクだけの狭い界隈の特権になってしまう。20~30年前ならいざ知らず、今現在の誰もが挑戦できる時代にはもったいない。
で調べていくと、歌声そのものの解説もあるにはあるんですが、それは大学論文やら研究レポートやら○○フォーラム報告書やらで、専門用語&数式&謎グラフ。そのレベルの話から始めても直接具体的な調声法には結び付けにくいです。私も目を通しはしますが正直半分も理解できているかどうか……。
かといって具体性においては間違いないであろうボイストレーニングや歌唱法に関する情報は、あくまで生身の人間向けで、これもまたAIシンガー/ボカロにそのまま適用はできない。
おでこあたりを意識して~、横隔膜を使って腹式呼吸をして~……なんて解説されても、歌声ソフトは肉体を持っていないのでどうしようもありません。
現実の楽器の仕組みや演奏法がDTMでもある程度活かせるのと違って、歌声だと現実の歌唱と歌声ソフトの調声を繋ぐ情報がなかなかリンクしていない。
困った。
というわけで、それらの情報を私なりにまとめ直して、DTMer/ボカロPが馴染みやすいであろう順番に組み替えてみました!
それが
歌声→発音→抑揚→効果
の順番です。ドヤァ!
(DTM歴2年にも満たないやつの自己満なのでご容赦ください。)
一応コレ、普通にDAWで曲制作する時の順番に則ってます。
では、長いですが順に紹介します。
歌声
歌声の項目には音価・音高、トランジェント・アタックなどやや馴染みの薄い用語が入っていますが、音楽用語としてはかなり基礎的な概念です。
なぜ馴染みが薄いかというと、どの音源/歌声ソフトを選ぶかの時点でこれらの概念が含まれていて普段気にすることが少ないからです。ドラムス音源の代わりギター音源を使うなんて普通は無いですから。
絶対無いわけではないんです。声であればボイスパーカッション(ボイパ)とかありますよね。声を打楽器音源として扱っている。
逆に周波数やらトランジェントやらをいじってあげると、放送時間外のテレビなんかで鳴っているザーッというホワイトノイズから音声を合成することもできます。
さすがにここからの解説は果てしないので本編でも紹介程度に留める予定ですが、知っていると知らないでは今後の理解の深さが変わってくると思います。
「上手に歌う」という観点に絞ればざっくり音源選び=歌声ソフト選びと考えてもらってよいです。
DAWで曲制作する時はまずトラックごとに音源を選びますね。それと同じです。
有料/無料、バージョン違いなどで性能差はありますが、こればっかりは声の好みもあるのでお好きな歌声ソフトを選んでください。
音価・音高はDAWで言うところのピアノロールで打ち込むノートのプロパティ(設定、属性)です。
具体的な曲制作は誰しもノート打ち込みから始めるはずです。
音価はノートの長さに相当します。デュレーションですが打ち込む開始位置のタイムも含んで考えます。
音高はノートの高さに相当します。ピッチですね。
(「音の大きさ」はここではノートのベロシティ相当と考えておきます。ベロシティの意味は本来「速さ」のことなんですが、電子音の規格上ピアノ鍵盤を押し込む速さが音の強さと定義され、それが至っては音の大きさに繋がるため、とりあえずここでは大きさがベロシティに相当するものと考えておいて差し支えないかと思います。)
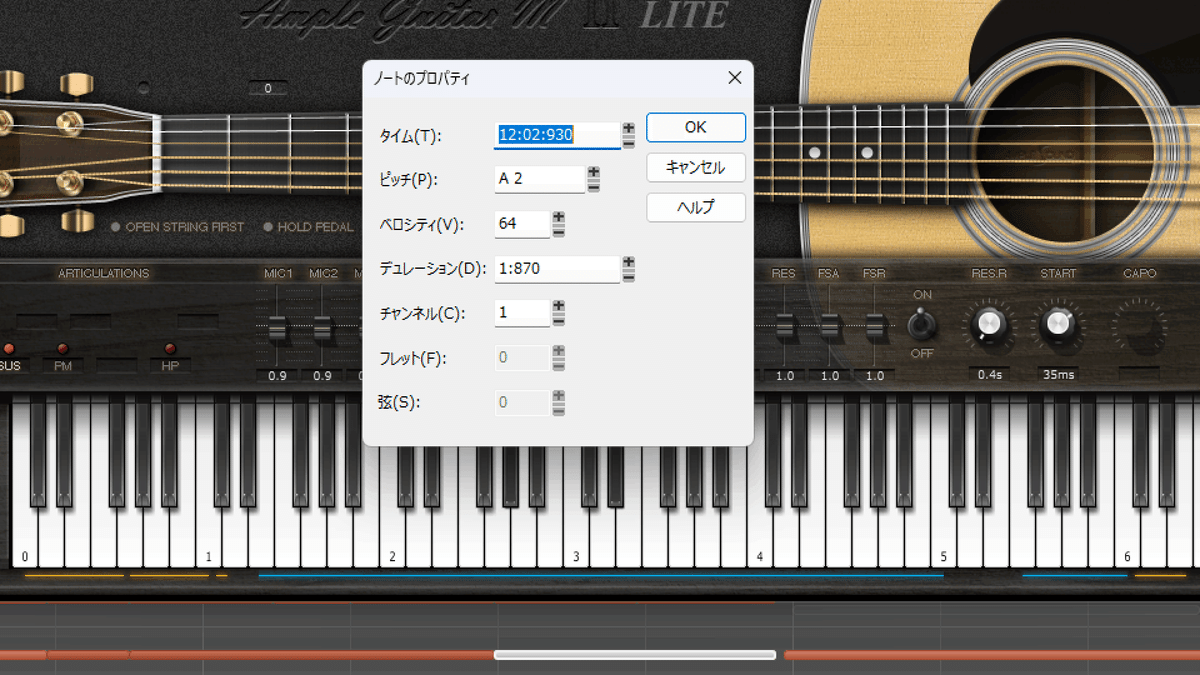
ノートを音楽理論に則って適切に打ち込むことで、狙い通りの音がDAWで再生されますね。理論から外れた長さや高さで打ち込めばだいたい音痴に聴こえます。
歌声もDAWと同じく音価・音高が間違っていれば当然音痴になったり不自然に聴こえます。「下手」なわけです。
あったりまえだろ、と思うかもしれませんが、調声に関する”簡単な”テクニック紹介ブログなんかではなかなかここから解説していません。あったりまえなのにです。
このノート打ち込みから曲制作が始まるように、調声もこの時点から始まっています。
参考にNEUTRINO調声支援ツールの画像を貼ります。
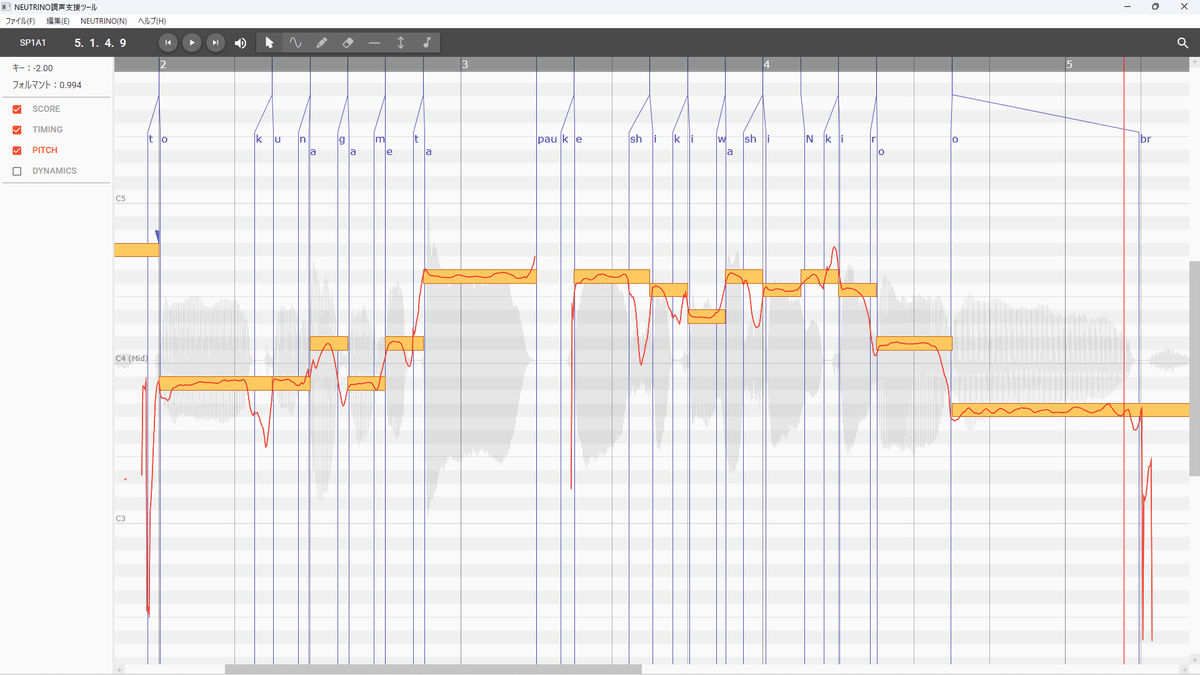
NEUTRINO調声支援ツール(以下、調声ツール)は、MuseScoreで歌詞を入力した楽譜データから、NEUTRINOシンガーの音声を合成してさらに調声作業まで行う必須ツールです。
(他の歌声ソフトだと歌詞入力から調声までDAW上で直感的に操作できるものもあるようですね。やはり無料の不便さは仕方ない。)
調声ツールの画面は上のような感じで、読み込まれた元の音符のデータを黄色いノートとして表示します。ノートの横幅が元の音符の長さ、縦幅が半音1個分です。背景色も白黒鍵盤になっていて、まさにピアノロールっぽいですね。
おおよそノートに沿っている赤い波線が実際に合成された音声データのピッチ(音高)、
縦向きの青い直線が合成された発音タイミング(音価の開始位置)、
その裏面にうっすら音の波形が見えています。(細かくて非常にわかりにくいですが横幅の細かさが周波数で、縦幅がその振幅=音の大きさです。細かさが密なほど高い音であることも拡大すれば確認できます。また別画面でダイナミクスも別に確認・操作できます。)
小さくて見にくいので拡大します。

左側に黒で手書きしたC4とC5の間隔が1オクターブ分、下側の長い横矢印が1小節分の長さです。つまり上側の黒い横矢印が4分音符分。
よくよく見てみると、元の音符の黄色いノートと実際に合成されたピッチの赤い波線はおおよそは沿っていますがピッタリ同時には変化していません。ピッチは上がったり下がったりしています。
それどころかノートの切れ目ではオクターブ以上落ちていたり、そうでなくてもノートの途中、一つの音声が続いているところでさえ大きくズレている部分もあります。
画像中央やや左あたり(縦の赤矢印)では6~7半音分、F♯(ファ♯)からB~C(シ~ド)くらいまでピッチを下に外しちゃっている。
ここの発音タイミングを表す青い縦線もノートの開始位置とはズレている。
上の青四角で囲ったところには小さく[sh]と[i]が表示されています。子音が[sh]で母音が[i]なので「し」の発音なわけですが、子音の[sh]は母音の[i]よりかなり手前から発音していることになる。小節の幅から逆算してみると16分音符~付点16分音符ぶんくらいは早いです。
この曲は4/4BPM=164で制作しているので付点16分音符(91.463ms)以上、約100ms(0.1秒)以上はズレている計算。人間の耳で聞き分ける2つの音の時間差は20ms(0.02秒)くらいからで50ms(0.05秒)では明らかな2音として聴き取れると言われているので、0.1秒ってかなりの差です。
そして調声ツールで合成する前、MuseScoreで実際に音符に「し」を入力しているのはこの次の半音下がったF4のノート上。母音の[i]の先、黄色い丸で囲った「し」と書いてある所から先が実際の「し」の歌声です。
ところが合成された音声の子音の[sh]の発声が始まっているのは手前のF♯4[k][e]「け」の歌詞の途中で、母音の[i]が終わっているのは「し」のノート上にかぶっている次のD♯4[k][i]「き」の歌詞の途中、ということになります。
[F♯→F→D♯]に乗せて「けしき」(景色)と歌っている間だけで、ピッチもタイミングもこれほどズレがあります。
実際に画像で見てご理解いただけたかと思いますが、合成された音声は音高(ピッチ)も音価(この場合、タイムとデュレーション)も入力時の楽譜からは大幅にズレます。やっぱりAIによる自動生成なんてそんなもので、さぞかし音痴で下手なのかと思われるかもしれませんが、これで合ってます。
では実際に聴いていただいて……といきたいところですが、ここから先の解説の詳細は次回以降にやっていきます。まだ制作途中の曲なのです、てへ。
ある程度調声に取り組んだことのある方ならご存知かと思いますが、このくらいのズレは当たり前のことで、少なくとも音痴ではないだろうなと経験上理解しているかと思います。
初めて意識して音声波形等を見たという方や、調声についてちゃんと学びたいという方はここから始めないと今後何が起こっているのか、どうしてそういう操作になるのか一切理解できません。
ドレミの音程や音符の長さすら知らないままDAWにノートを並べるだけでは上手く作曲できないのと同じです。最低限の知識です。
逆に言えば感覚や才能的なものではなく、画像やグラフ、数値によって視覚化・言語化できるということであり、ソフトやツールの性能の限界はあれど誰でもある程度再現できるということに他なりません。
知識が身に付いた頃には、何でもないことのように調声作業ができるようになっていると思います。
発音
さて、このペースで進めていては基礎回だけで数回に渡ってしまい終わりそうにもないので、あとはサクサクッと紹介します。詳細はのちの各項目回に譲ります。
次が発音です。
そのまんまなので曲制作に当てはめるのもなんですが、音を出すことです。DAWでの曲制作においてノートとは、ピッチやデュレーションを指示するただのデータを横棒として表示しているに過ぎず、本来まだ音は鳴りません。DAWがそれでは不便なので、入力した時点で音が鳴るように環境設定されています。
AIシンガー/ボカロで言えば、実際に歌わせること。
NEUTRINOで言えば、DAWに打ち込んだノートをMIDIデータとしてMuseScoreに取り込み、歌詞のデータを上乗せして(musicXMLデータ)、調声ツールで音声合成して歌わせるところまでです。
DAWのトラックにWAVデータとして取り込んでミックスするところまでは含みません。
ノートと同じくDAW上で打ち込みながらそのままナチュラルに歌ってくれたら便利なんですが、技術的限界や無料ゆえの試練です(泣)
子音や母音の詳細は大枠のここの項目で解説予定ですが、先の音価・音高でも子音・母音に触れたように他とも密接に関わっています。やっぱり行ったり来たりになります。
先に、大学論文やら研究レポートやら……と紹介しましたが、音声・言語研究などで度々出てくるのは、この発音に関してのものが多いです。ですので直接的・実践的に調声に結び付くものではありません。
でも【作詞編③】で、発音レベルから調声しないと自然な歌声にはならないと実例を挙げたように、必ず通らなければならない道です。
「~センス」と英語っぽく発音させるのに一苦労。
— 金田ひとみ(2) (@Hitomi_Kanada) December 19, 2022
短いと母音のDynamics削るだけでもごまかせるけど、ロングトーンの最後に"-nce"だと「ンス」ってあからさまに発音してしまうので、歌詞から調声が必要。
(続きにコツ↓)#NEUTRINO #調声 pic.twitter.com/Fr4aTf3jQ0
この時の回では子音の[s]について例を挙げましたが、そもそも子音や母音がなぜそのように聴こえるのかについても知っておいたほうが調声のレベルアップに繋がります。
なぜ息を吐きながら口唇の形を変えただけで「あ」「い」「う」「え」「お」を別の音として発声できているのか?、
「た」と「ら」はそれぞれ舌の動きは似ているのになぜ違う音になるのか?、
「ふ」と「く」は口唇を一切動かさずに連続で違う音を出せるのはなぜなのか?……
などについても少し触れるかもしれません。
……あ、今画面の前で「たらふく」って言ってるでしょ(笑)
記事内容が大き過ぎておなかいっぱいなんですね、私もです。
という冗談は置いておいて、疑問を持って実践で確認するのは良い心がけだと思います。
ただあまり深くまでは解説しません。ガチで音声学・言語学の分野の話にズレていってしまいますし、スペクトログラム分析とかできるわけではありませんので検証があやふやになってしまいます。
調声ツールをガチで使っていると、ぐちゃぐちゃっとなった周波数だけを表示したスペクトログラムを見ただけでも、おおよそ何と発音しているかわかるようになります。

楽勝だったわ。 pic.twitter.com/VWtNoxzxmV
— 金田ひとみ(2) (@Hitomi_Kanada) January 9, 2023
ここでやるのは、せいぜい調声ツール上で「”た”と”ら”は何が違うのかな~」と比較するくらい。
実際の発音は、AIシンガーやボカロがイイ感じのところまでやってくれますので調声では微修正するだけ。おてつだいです。その程度の知識で十分かと思います。
あとは一応、ひとつ手前のTwitterの「adolescence/アドレセンス」の例のように英語っぽい発音なんかにも応用できます。
「た」と「ら」で例を出すと、
たとえば「Get Up」を「げっとあっぷ」と入力したら絶対下手な発音になるのはわかりますよね。
子音[t]と母音[a]を繋いで「げったっぷ」でもまだ変。
どちらかというと前の「っ」を飛ばして「た」が「ら」に変化して「ぷ」が子音[p]だけになった「げらっp」が近い。
NEUTRINOを初め多くの歌声ソフトは日本語の発音しかできませんので、こういったテクニックも上手く使いこなしたいなら発音の基礎に少し触れておくと良いかなと思います。
発音関連では他に、私がたまにやっている「歌詞に無い歌詞」を歌わせる「ゴーストノート調声」を紹介します。私の秘密兵器です。
実は【作詞編④】で出した楽譜画像にあった青丸がこのゴーストノート調声です。

実は青丸がゴーストノート調声用の「歌詞に無い歌詞」。
ゴーストノートとは、主にドラムスの打ち込みなどで使われる、叩いたか叩いてないか分からないくらいの小さな音を入れることで、より自然でリアルに聴かせるテクニックです。ギターやベースなどの打ち込みでも使われます。
人体そのものと楽器の音の鳴る場所が近い、要はニュアンスがダイレクトに伝わりやすい楽器の打ち込みで頻繁に使用する傾向があるようです。
そう考えると声はまさにそうですね。近いどころか人体そのものなので。
主にドラムスのテクなので正確には意味が違うのですが、発音がほぼ消えているのにその音のお陰で本来しっかり聞かせたい発音が自然でリアルになるので勝手にそう呼んでます。
あまり他の方の解説では出てこないと思います。あるにはありますが少ないですね。発音そのものを理解していないと使いこなすまでに至らないからかもしれません。
それから大きな話題としては他に、フォルマントとピッチガチャについて。
このふたつは結構連動しています。
フォルマントは調整ツールにある機能で、数値を下げると大人っぽく、上げると子供っぽくなるものです。他の歌声ソフトでも似たような機能があると思います。
バラードならしっとり落ち着いた声、ポップスなら明るく元気な声など特徴付けを目指すなら、フォルマント機能も意図的に使えるようになっていると良いです。
機能としてではなく音声学におけるフォルマントそのものの本来の意味もここで解説します。母音にかなり関わっています。まったく違う音声に聴こえるくらいに。ホワイトノイズからでも音声合成が可能な理由になります。
次で説明するピッチガチャはこのフォルマントの周波数を原音と違う周波数帯で生成することで、声質だけでなく歌い方まで変えるテクニックです。
で、ピッチガチャ。
これはNEUTRINO特有のテクニックで、わざと違うキーで音声合成してから元のキーなどに戻すことで原音と違う狙った声を作るための、これも秘密兵器とも言える調声法です。戻したあとにフォルマント機能と組み合わせることでさらに自在に扱えるようになります。
他の歌声ソフトで同様の操作ができるかどうかは不明です。
私の場合、Aメロ/Bメロ/サビ、1番/2番/落ち/ラストサビといったパートごとや、同じパート内でも前半後半に分けてピッチガチャを掛けていることもあります。
NEUTRINO関連の解説ではよく出てきますが、シンガー毎の得意音域、出したい声の特徴などを把握した上でやらないと無限沼にはまってしまいますので、その方針などを紹介できればと思います。
他解説等では「運頼り」みたいに言われていますがそんなことは無い。ある程度意図的に操作できます。
あとはブレスですね。
【作詞編④】で、ブレスは発声ではないけれど歌声であると考えることもできると紹介しました。
的確に効果的にブレスを入れることで、のっぺりとした機械音声ではなくまるで生きて呼吸しているような自然な歌声にできますし、どこに入れるかによって感情表現や盛り上がり方も変わってきます。
作詞にすら逆に影響を与えるくらいです。
そのポイントやコツを紹介します。
この回はNEUTRINO特有の操作も多いので、他ソフトでの応用がそのまま効くかは残念ながら不明ですが、似たような操作はおそらくあるんじゃないかと思います。
そこはお使いのソフトやツールの機能をいじり倒して、アイデアでがんばっていただくしかありませんのでご了承ください。
抑揚
さあまだまだ長いぞ……(泣)
次は抑揚です。
アクセントやイントネーションの付け方、要は歌い方の癖の部分です。
12音階音程外の半端な高さも含めた音高(ピッチ)を上下させることが主な操作になります。音の大きさ(ダイナミクス)を調節することもあります。
ギターの打ち込みにこだわる方なら想像しやすいと思いますが、曲制作におけるピッチベンドに相当します。ギター奏法のチョーキングやスライドですね。
ギターの奏法をよく知らない方でもエレキギターがギュイーンとなめらかに鳴っているのを聴いたことはあると思います。
ここからはそれまで以上に音価・音程・発音などについて事前知識がある前提での解説になってくると思います。それらとさらに密接に関わってきますので。
リアルなギターの打ち込みがやたら難しいのと同じです。
それなのにおそらくほとんどの調声に関する操作やその解説は、それまでをすっ飛ばしてここから始めていることもあるようです。
特にビブラート。
確かに調声と言われて一番誰にでも分かりやすく花形っぽいのがビブラートではないかと思います。ギターソロなんかでもその傾向はあります。
調声ツールの機能でも最も簡単に掛けることができて、よほど掛け過ぎない限りはなんとなーく上手く調声できたような気になる……。
罠です。
確かに歌が上手い歌手と言われて名前が挙がるアーティストは大抵ビブラートも上手いです。
しかし彼ら彼女らは、音価・音高・発音など、ここまでの歌声の基礎を生まれつきや訓練によって習得していて、その上で自分なりの歌い方を見つけ、そこに意図的にビブラートを上乗せしたり自然とビブラートを掛けることができるようになっているから上手く聴こえるのです、たぶん。
これも【作詞編④】で少し紹介したお話ですが、下手にビブラートを掛け過ぎると「ちりめんビブラート」と揶揄されるようなくどい歌い方になります。
そうならない適度で自然なビブラートの掛け方を検証します。
(実はビブラートはちょうど今研究中で、ひょっとしたら調声ツールの使い方次第ではよりナチュラルで力強いビブラートを再現できるかもしれません。)
それからコブシについて。
演歌でよく聴くアゥアゥいうやつ。
コブシは演歌だけなんじゃないの思われるかもしれませんがビブラートと共通している部分もあり、最新のポップスシンガーだろうが当たり前に使っています。
力強さを出すには知っていると便利です。
ただこれも掛け間違えると、ねちっこい歌い方になります。
調声ツールだけでなくMuseScore楽譜上での操作も関わってくるのでそれも併せて。
シャクリは歌い終わりなどにピッチが上がるもの、フォールは下がるもののことを言います。
これも表現力をアップさせるには便利な調声法です。
上手く使えばより可愛く明るく歌わせたり、落ち着いた優しい雰囲気を出したりもできます。
きりたんやセブンちゃんが少女っぽく、めろうさんが大人の女性に聴こえる要素のひとつです。
ビブラート、コブシ、シャクリ、フォールなどはカラオケの採点基準にもなっているので馴染みがあると思います。
要は調声でそれが再現できると表現力がアップするということです。
でもやりすぎると癖が強くてしつこくなる。仕組みを把握していないと最悪の場合ナチュラルになるどころか、より機械音声感が増してしまう。
私が小手先のテクニックが好きではないのはそのせいです。
でもこれまでの知識やテクニックを総動員して取り掛かれば、間違いなく調声が上手くなると思います。
あとオマケですが、私の自作品でたまに入れているセリフっぽい歌詞。
あれも実は今までの発音の基礎と、この抑揚の機能などを駆使して調声ツールで再現しているものです。別個にトークソフト(テキスト読み上げソフト)を導入しているわけではありません。
東北きりたんや東北ずん子であればNEUTRINO以外でもトークソフトがありますのでセリフを入れることも可能でしょうが、セブンちゃんたちはNEUTRINOオリジナルキャラクターなので残念ながらありません。
ですので以下の曲↓のイントロなどで入っているカウントコールは調声だけで作っています。
『HARD BEAT HEART BEAT』No.7/SEVEN/セブン
調声って面白いでしょ。こんなこともできちゃいます。
効果
やっと最後の項目まで来ました。
効果つまりエフェクトです。
曲制作で言えば、今までがノートを打ち込み、音を作り込み、強弱やニュアンスを施し、そして最後にエフェクトを掛けたりミックスをしたりといった手順の最終段階部分です。
【調声編】の順番が、歌声→発音→抑揚→効果となっている理由がご理解いただけたかと思います。
この順番がおかしいと後からどう修正しようともどうにもならないことは、DTMをやっている方は経験上身に染みているのではないかと思います。
曲制作だと当たり前のことなのに、調声となると後半の抑揚や効果の解説ばかりを目にします。
それらの解説がたくさんあるということは、ここから先は私のようなまだまだDTM歴の浅い人間が解説するより、専門の情報を直接当たったほうが間違いないということでもあります。
ですので一番最初に「どこまでが調声か」の最も広い定義を挙げましたが、そのすべてを解説し始めると本当に果てしなくなるので、私の【調声編】では「歌が上手い」に主に関わる部分までにします。
エフェクター加工ごりごりの「調声スゲー」にはそこまで触れません。
というかここまでで十分「歌が上手い」&「調声スゲー」をクリアできると思います。ナチュラルに歌えて、歌声ソフトの実力を存分に発揮できている状態。
あとは色付け、曲調・曲ジャンル、ご自身の好み、流行りなど各自の目標があるでしょうから、それに応じた効果を加えていってください。そういった情報はネット上にいくらでも転がってます。
この項目で私が扱うのは、
ディエッサーやコンプレッサーやイコライザー等による微修正、
ダブリングやリバーブによる臨場感、
ハモの作り方や入れ方・考え方、
などの基本的な部分までです。
ディエッサー、コンプレッサー、イコライザー等のエフェクター群についてのそれぞれの使い方や設定などは専門の解説にお任せします。検索すればいくらでも出てきます。
私はエンジニアリング的なことそれほど詳しくありませんので、あくまで調声の観点からの必要最低限の解説になります。
どちらかというと、なぜ掛けるのか、というお話。
エフェクターをがっつり掛けなくてもそれまでの調声が上手くいっていれば微修正で済みます。
エフェクターを使った積極的な声質作り、例えばラジオボイスやケロケロボイスの作り方は含みません。逆に下手に掛け過ぎて意図としない機械音声にならないための注意点みたいな感じです。
ケロケロボイスはPerfumeやSEKAI NO OWARIなどでよく聴かれるテクノっぽいロボットの声みたいなやつです。NEUTRINO調整支援ツールにはケロケロボイス機能があります。そういう意味では調声か?(笑)
解説はしない予定ですが、何が起こっているのかはこれまでの調声で自然と理解できると思います。
ダブリングは2つ以上の同じボーカルメロディーラインでそれぞれ揺らぎなどが微妙に違うものを重ねることで、音の厚みや豊かさを生むテクニックです。
無くても問題ないですし私もあまり使いませんが、やり方を知らずに重ねると逆に機械音声感が増してしまうことがあるので、これもそうならないための注意事項です。
またリバーブと同じ項目で扱うのは、少し遅らせたダブリング、要はディレイを掛けるとリバーブと似たような効果が得られるからです。
掛けなくても調声としてはそれほど問題無いのですが、やはりオケと合わせたときにボーカルだけが浮いてしまうことがあるので、あくまでオケに馴染ませて臨場感を作るため、程度のところまでです。
掛け方を間違えるとお風呂場で歌ったようなこもった響きになったり、はるか遠くで歌っているような歌声になってしまいます。手前の項目と合わせて勝手にケロケロ温泉と呼んでます(笑)ケロリン桶ではありません。

ケロリンファンクラブより画像をお借りしました。
エフェクターの掛け方は調声というよりは、最終的な完成品にするためのミックスに関するお話に傾いてきますので、ミックスの情報を当たったほうが早くて間違いないです。
また生身の人間の声を直に録音したのと違い、調声済みの歌声ソフトシンガーの声は極端なダイナミクスの差やノイズやブレが少ないので最低限の修正・調整で十分かと思います。録音マイクの性能やその距離や録音スタジオの音響まで考えることは普通ありません。
そして今回の【調声編】の最後。
ハモです。
ハモ(ハモり、由来はハーモニー)はメインボーカルの主旋律に対して、サイドボーカルとして別のメロディーを重ねて歌わせるボーカルテクニックです。ダブリングが同じメロディーを重ねるユニゾンの一種であるのに対し、ハモはたいていの場合別のメロディーを重ねることを指します。
また、ハモではないですが私がたびたび自作品に入れている輪唱(カノン)や、メインボーカルのバックで「Uh」や「Hah」といったスキャット、ハミング等を入れる合唱(コーラス)についても触れます。
ほとんどの方が知っているでしょうから定義は改めて解説するほではないと思いますが、実際作ってみようとするとかなり難しい。
それは「なぜハモが美しく聴こえるか」を理解していないのと、「何のためにハモを入れるのか」を決めていないからではないかと思っています。
前者は和声理論についてで、後者が「歌が上手い」に繋がる調声に関わります。ですので主に後者についてのお話になるかと思います。
私も和声理論をちゃんと理解してるわけではありません。音大とかに通っていればしっかり勉強するんでしょうが。
でもそれなりにハモやコーラスを入れた曲を作っています。というか入っていない曲のほうが少ない。1回聞いただけでは気づかないレベルで重ねているときもあります。
クラシックでは禁止されている和声が現代の曲では普通に使われていて、逆にその曲らしさになっていることもあるようです。
テクニックを極めたい方は和声理論を勉強してください。
ただし目標のないテクニックだけを学ぶのは苦痛ですし、ここまでの様々な調声法と同様「しつこくなる」だけで「歌が上手い」とはかけ離れてしまうかもしれないことは心に留めておいて欲しいと思います。
結び
基礎回なのにまたもや恐ろしく長い記事になってしまいました。
項目だけをパパッと挙げて具体的な内容にさっさと進むか、具体的な内容を散発的に羅列していくかで最初ちょっと迷ったのですが、最終的に初回から方向性や初歩的な解説も含めて書くことにしました。
普段から書いているあの長い記事は結構思い付きで書き連ねていることも多いのですが、【調声編】は普段と違い理論的・技術的なことも多く含むので思い付きだと整合性が破綻するかもしれない、と危惧してのことです。
ある意味今回が【調声編】のコンセプト&構成です。
私の作曲法が、コンセプト→構成→具体的な内容と進んでいくのと同じですね。ここがしっかりできていれば内容が破綻することはない(はず)。
また各回において、本来なら【作曲編】【制作編】等で取り上げるべき理論や用語、テクニックなどが登場することになります。トランジェントやアタックなどが最たるものです。
ですので途中途中で【作曲編】等に戻ったり、同時進行で【制作編】を挟む可能性もあります。そういった意味では散発的になるかもしれない。
今後進めていく各回の具体的な内容も、特に前半は基礎的で学術的な話も多くて何をやっているのか方向性が理解できないものも出てくるかもしれませんが、そんな時は今回初回の【調声編①】を見直してその流れをつかみ直していただけると良いかと思います。リンクを常時設けておきます。
私自身今回を見直しながら今後進めて参ります。
何か月かかるかな~、できれば半年、いや一年くらいかかるかなぁ。
まぁそのくらいの価値はあるということで。
次回予告
次回からは具体的な内容に移ります。
まずは歌声の項目、音声そのものからですね。
今回の基礎解説で挙げた調声ツール画面などをまた改めて見直しながら、声ってどういう仕組みなの?のところから始めます。
わざと「下手」なパターンなど実例も挙げながら進めていきます。
あぁ~その制作に時間がかかりそうだ(泣)
金にもならんのにご苦労なことですわ。
(リアルの本業も立場上忙しくなる時期と重なっており、更新が遅くなる点は何卒ご了承くださいませ。趣味ではなく、ちゃんと結果を出して稼いで生きてかなきゃならんのです。社会人のつらいとこ。)
何はともあれお楽しみに。
それではまた次回。
Thank you for reading!