ChatGPTでスクリプトを書くスクリプトを書いてアプリレビューを分析する

相変わらずChatGPTがないと業務が成り立たないぐらい依存しています。スマートに使っているかはよくわかりませんが、増え続ける"やらなければならないこと"と"やりたいこと"に対して、ChatGPTが担っている役割は非常に大きいと思います。大きな組織であれば多くの人のお願いできるかもしれませんが、スタートアップでそんな状況があるわけもなく、最初にお願いする人は大体ChatGPTです。
ということで、今日はアプリのレビューを分析をしました (してもらいました)。内容は毎日見ているので大体の傾向はわかっているつもりですが、他の人と全体の状況を共有するために分析してみました。すぐに終わったので、その方法を書いてみたいと思います。
分析するスクリプトを生成するスクリプトを書く
いまさらですが、ChatGPTは構造化されていないテキストの分析・サマリ能力は非常に高いです。ただし、ご存じの通り一度に分析できる(入力できる)テキストの長さには上限があります。
ありがたいことにアプリのレビューはそれなりに量があるので、残念ながら全てを一度にプロンプトに入れるのは厳しそうです。何か考える必要があります。ただし、だからと言って、一つずつをChatGPTのWebUIに入れて集計していくのもめんどくさいです。そして、今後も多くの文章を分析したいケースはありそうなので、長いテキストをChatGPTで分析するスクリプトを書きます。
仕様は難しくなく、まずはプロンプトに入れられる長さのテキストに分割して、それぞれを集計し、最後にその中間サマリを集計して最終結果を得るというものです。正しく実装しようとすると再帰的に分割>サマリを繰り返さないとだめですが、今回は1階層での分割でよさそうだったので、再帰処理はスキップします。
ただ、その簡単な仕様ですら、スクリプトを書くのもめんどくさい、、、ではなく、そもそも一から書けません。従って、スクリプトをOpenAI APIで出力するスクリプトを書きました。(OpenAI APIをCallする部分は過去のスクリプトからコピペしてます)
import openai
openai.api_key = "hogehoge"
response = openai.ChatCompletion.create(
model = "gpt-4",
temperature = 0.0,
timeout=300,
messages = [{"role":"system","content":"""Write a python script to process long text(text) in following procedures.
1. Split the text by return code ('\n').
2. Append the splitted text with a return code ('\n') until the length of the text is less than 4000.
3. Call ChatGPT API with the appended text.
```
response = openai.ChatCompletion.create(
model = \"gpt-4\",
temperature = 0.0,
messages = [{\"role\":\"system\",\"content\":f\"\"\"{{task_description}}
{{splitted_text}}}
\"\"\"}])
```
4. Get the response from ChatGPT API. You can get the response by calling `response.choices[0].message.content`, and print it.
5. Append the response to an array (intermediate results).
6. Repeat 2-5 until all splitted text is processed.
7. Call ChatGPT API with the array (intermediate results).
```
response = openai.ChatCompletion.create(
model = \"gpt-4-32k\",
temperature = 0.0,
messages = [{\"role\":\"system\",\"content\":f\"\"\"Summarize intermediate results, counting similar items, understanding the following task description. Output only top 5 items with title and description in order of the number of counts descending in English.
[Task Description]
{{task_description}}
[Intermediate Results]
{{intermediate_results (as array, not string)}}
\"\"\"}])
```
Write a python script contains __main__ to run as an independent script. The function that satisfies the above requirements has parameters of `task_description` and `text` and returns final output from ChatGPT.
"""}])
print(response.choices[0].message.content)
ちなみに、このスクリプトはGitHub Copilotに補完してもらいながら書きました。GitHub Copilotを使って書くと、コードの補完と同じようにプロンプトの補完もしてくれます。
考えていたことと違うことも多分にあります(上記も半分ぐらい違っています)。ただ、自分でゼロから書くよりははるかに速いですし、違っているものを直す方がはるかに簡単です。スクリプトを書くスクリプトを書くのに補完してもらっているなんて、本当にありがたい時代になったなぁと思います。ゼロからコードを書ける気が全くしません。
そして、tabキー(補完)を多用して書いたコードを実行します。下記がコードを実行して出力されたコードです。
import openai
openai.api_key = "hogehoge"
def process_text(task_description, text):
# Split the text by return code
splitted_text = text.split('\n')
# Initialize an array to store intermediate results
intermediate_results = []
# Initialize a string to store the current chunk of text
current_chunk = ""
# Process each line of text
for line in splitted_text:
# If adding the next line doesn't exceed the limit
if len(current_chunk) + len(line) < 4000:
# Add the line to the current chunk
current_chunk += line + '\n'
else:
# Call the ChatGPT API with the current chunk
response = openai.ChatCompletion.create(
model = "gpt-4",
temperature = 0.0,
messages = [{"role":"system","content":f"""{task_description}
{current_chunk}"""}]
)
# Get the response from the API and print it
api_response = response.choices[0].message.content
print(api_response)
# Append the response to the intermediate results
intermediate_results.append(api_response)
# Start a new chunk with the current line
current_chunk = line + '\n'
# Call the ChatGPT API with the intermediate results
response = openai.ChatCompletion.create(
model = "gpt-4-32k",
temperature = 0.0,
messages = [{"role":"system","content":f"""Summarize intermediate results, counting similar items, understanding the following task description. Output only top 5 items with title and description in order of the number of counts descending in English.
[Task Description]
{task_description}
[Intermediate Results]
{intermediate_results}"""}]
)
# Get the final output from the API eand return it
final_output = response.choices[0].message.content
return final_output
if __name__ == "__main__":
task_description = "task description"
text = ""text"""
final_output = process_text(task_description, text)
print(final_output)冒頭のapi_keyのところだけ追記しました。それ以外のところは全く何も修正していません。
根拠はないですが、ぱっと見、動きそうな気がするので、変数部分を記載します。まずはtask_descriptionです。今回は下記のようにしてみました。
AIキャラクターを作るアプリの以下のレビューデータから、ユーザーがどういうキャラを作りたいと思っているか、その傾向をレビュー内容を分析してください。ニーズは同様のものをまとめて、関連するレビュー数をカウントしてください。われながら、とてもあいまいな定義です。これまでの経験からこの程度で大丈夫そうな気もするので、いったんこれで試してみます。
textには、Google Play Console、AppStore Connectから取得したアプリレビューの内容を1行・1レビューの形にしてコピペしました。今のところ、コピペは人間にしかできない大事な仕事です。
そして実行して、結果を得ます。(そのまま動いたので何も書くことがありませんw
得られた結果をそのままWebのChatGPTにコピペして、Advanced Data Analysisでグラフを作り、それぞれのカテゴリのコメントを適当な長さに調整して完了です!
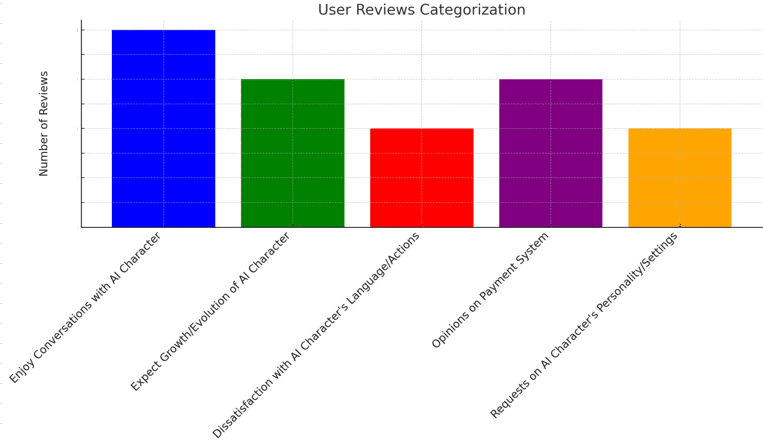
- Enjoy Conversations
Users relish dialogues with their AI, including chats with favorite or created characters.
- Growth Expectations
Users anticipate the development and progression of the AI character.
- Dissatisfaction with Behavior
Some users are unhappy with the AI's language and unpredictable actions.
- Payment System Views
Mixed feelings exist about the payment system, with some users expressing concern.
- Character Customization Requests
Users desire more options for personalizing the AI character's traits and settings.ちなみにサマリでの圧縮率(インプットとアウトプットのトークン数の比率)は、5~6分の1ぐらいでした。つまり、1段階の分割でプロンプトの上限の5,6倍の情報は要約できると思います。gpt-4-32kだとそれなりの量は分析できると思います。API Callの費用もそれなりになりますが、数時間かけて分析することを考えれば圧倒的に安いと思いますし、2回目からはデータさえ準備すればほぼ実行時間のみで結果が得られます。
まとめ
アプリのレビューなど、大量のテキストデータを分析するスクリプトを作るスクリプトを書いて分析してみました。最終的なグラフとサマリを得るまでにかかったのは20分ぐらいです。次回から同様のタスクを実行する場合は数分で終わると思います。このブログを書く方がはるかに時間がかかっています。
今回記載したのはほんの1つの例ですが、このような効率化・自動化を繰り返すことで、今年の初めに比べれば少なくとも半分ぐらいは時間を節約できている気がします。今後も楽するために頑張って効率化していきたいと思います。
ということをやっていたら、AWSのBedrockでClauseが利用できるようになりましたね。簡単に少し試してみたら出力結果もよさそうでした。100kトークンまで処理できるので、今回のように分割して処理する必要がないかもしれません。
この分野は非常に進化が早いので、日々、品質があがり、新しいことができるようになり、そしてさまざまな制約がなくなっていきます。一方で、実際に試してみないことには、何に使えるのか使えないのか、次にどういうことができそうかの感覚がつかみにくいです。今後もそのインプットの時間を増やすためにも、作業時間をなるべく圧縮していきたいと思います。
この記事が気に入ったらサポートをしてみませんか?