Splunkの分散サーチ環境の構築(後編)

ここまででSplunkの基本的な構成からインストールまで話を進めてきました。ここからは実際に分散サーチの構成を構築していきたいと思います。
SearchheadとIndexerを繋げる

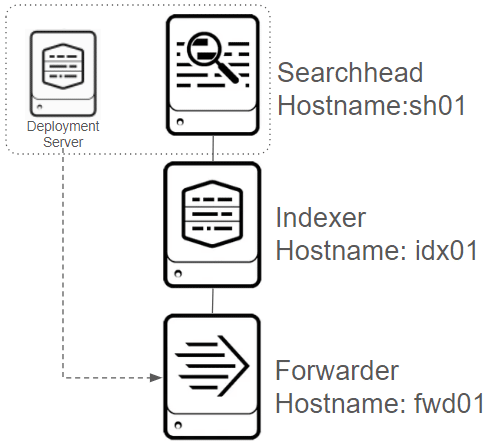
改めて全体の構成をおさらいします。先に説明をした分散サーチ構成の基本構成は下図の構成となっています。ターゲットとなるログについてはForwarderがインストールされているfwd01に存在しています。そこからUFがログを持ってきて、Indexerに送信、SearchheadがIndexerにたいして検索をします。
Searchheadの作業
それではSearchheadから設定をしていきます。SearchheadにWebブラウザでアクセスしてください。Webコンソール(正確には「Splunk Web」と言います)はhttps://[Your host/ip]:8000です。ログインしたら画面右上の[設定]から[分散サーチ]にアクセスします。ここで少し脱線しますが、設定の流れについて、日本語で解説をしています。ブラウザの環境によっては英語で表示されると思います。その場合、URIを"https://[your host/ip]:8000/ja-JP/app/launcher/home"と、太字の部分をen-USからja-JPへと書き換えてください。

作業: サーチピアの追加作業
次に「サーチピア」の追加を行います。[新規追加]をクリックしてサーチピアを追加します。ここでいう「サーチピア」ですが、これはインデクサーの事を指します(ちょっとややこしいですね)。
その上、[分散サーチの設定]がありますが、ここは特に何もする必要はありません(分散サーチの有効化/無効化設定がありますが、デフォルト有効です)。

新規追加をクリックするとこのような画面が開きます。以下項目をすべて埋めます。ピアURIは通信先です。SplunkとSplunkが相互に通信をするためのポートとして、デフォルトで8089/TCPが開いています(これをS2S通信と言います)。ここではサーチヘッド→インデクサーに通信をさせますが、ピアURIは"https://[インデクサーのIP]:8089"を設定します。スキーマ(https://)を必ず忘れないように入れてください。またその下、分散サーチ認証についてはインデクサーの管理ユーザの認証情報を入力してください。完了しましたら[保存]をクリックします。

無事にサーチピアが追加されますとこのような表示になります。

基本的なのはこれくらいになります。が、これだけだとインスタンスの状態把握が限定的である事や各インスタンスのログの集約ができず、管理ができません。ここから管理系の設定を行っていきます。
作業: SearchheadのMonitoring ConsoleからIndexerを監視する
また新しい言葉がでてきました。"Monitoring Console(MC)"はSplunkにデフォルトでインストールされているAppsになります。AppsはSplunkの話をする際に必ずでてくるキーワードになりますが、大きく二つに分かれます。一つはSplunkに新しいダッシュボードを追加するような、機能追加のもの、もう一つが新しい機能を追加するための設定ファイル群の事をApps(設定だけのものについてはSplunkの世界では”TA(Technical Add-on)”とも呼びます。MCは前者の、まさにアプリケーションの事です。 MCはスプランクのインスタンスを監視するアプリケーションなのですが、Searchheadから他のインスタンスの状態を把握できるように設定をしていきます。この設定はCLIで行います。Searchhead(MC)のコマンドインタフェースから次のコマンドを実行します(実行ユーザはSplunkを実行しているユーザで!)。
/opt/splunk/bin/splunk add search-server [監視対象のIP=ここではIndexer]:8089 -remoteUsername [監視対象の管理者ID] -remotePassword [その管理者のパスワード]次にMonitoring Consoleを設定します。再び`SearchheadのSplunk Webから[設定]→[モニタリングコンソール]→[設定]→[通常セットアップ]をクリックしてMCのセットアップ画面に遷移してください。

このように表示されましたら(注: 上の画像だと[変更内容を適用]が緑になっていますが、デフォルトではグレーです。設定を適用する必要がある際に緑に変化します)画面左の[Mode]を[スタンドアロン]から[分散]に切り替えます(分散をクリック)。そうすると次のような画面が表示されます。

これが表示されましたら[続行]をクリックしてください。この画面が閉じて、MCのモードが分散モードに切り替わります。そうしましたら画面右端の[変更内容を適用]を必ずクリックして設定を適用してください(ここ、忘れやすいポイントです!)。設定が完了してインデクサーが監視できるようになると以下のような画面となります。

上の画面は"サーバーロール"を設定後の状態にしてしまっていますが、概ねこのような画面になります。
解説: サーバーロールについて
ここでサーバーロールの話がでてきましたが、これはここまでご紹介をしてきた「コンポーネント」の最小単位のモノを指しています。Splunkのサーバーには複数の機能が割り当てられているのですが、分散構成の場合、この機能を分散して持たせることになります。今回構築する分散サーチの構成の場合、上の画面のサーバーロールの割り当てが最適です。サーバーロールの設定は画面右のアクションにある[編集]→[サーバーロールの編集]から設定を行います。

Splunkの分散環境を構築する上で一つのテクニックとして、もっとも負荷が集中するインデクサーには最低限の機能(インデクサー、クラスター環境の場合、クラスターマスター)のみ与える、という事があります。今回の構成ではクラスターを使う事はないので、クラスター関係の設定(クラスターマスター、SHCデプロイヤー)は不要。インデクサーにはインデクサーの機能のみを割り当てます。その結果、上画像の「分散モード」の状態がベストとなります。ここで設定をしてしまいましょう。
解説: Knowledge bundle replication/KOsの事
これらの設定を実施することで、SearchheadからSearch peerに対してKnowledge Objects(KOs)の展開が行われます。これをKnowledge bundle replicationと言います。SearchheadにはKOsとしてフィールド、Lookup、Savedsearch、レポート、フィールド抽出の情報等を持っているのですが、検索をする際、インデクサーはこれらの情報をKOsを参照して検索の処理を行います。KOsはSearchheadからIndexerに対して自動的にリプリケーションされます。細かい話になるのでこれ以上詳細を書くとわかりにくくなってしまいますのでこれくらいにしておきましょう。Bundle Replicationのステータスは先ほどの分散サーチの設定画面の他、MCの[サーチ]→[ナレッジバンドル複製]からも見る事ができますので、ご興味があれば確認をしてみてください。
作業: Searchheadで発生する内部のログをIndexerに送る設定
再び作業に戻ります。次に行うのは、Searchheadで発生したログを検索できるように、Indexerに送るための設定します。Splunkの監査ログは"_internal"のように、アンダーバー付きのインデックスに保管されます。分散サーチ環境の場合、SearchheadにはIndexerの機能は持たせていない設計にしています。従ってログの保管と検索ができませんので、サーチピアに内部ログをすべて送り、サーチから検索ができるようにしてあげる必要があります。この作業はconfファイルを書いて行います。Searchheadの”/opt/splunk/etc/system/local/” 配下にoutputs.confファイルを作成して以下の内容の書いてください(もしくは追記)。
[indexAndForward]
index = false
[tcpout]
defaultGroup = my_search_peers
forwardedindex.filter.disable = true
indexAndForward = false
[tcpout:my_search_peers] server = [サーチピアのホストIP]:9997Splunkのoutputs.confファイルはインスタンス外に対して何らかのアクション、例えば外部インスタンスにデータを送信する為の設定ファイルになります。今回はSearch peerに対してデータを送りますので書く必要があります。もう1点注意ですが、Splunkのconfファイルは"default"と”local”ディレクトリに存在しています。ユーザ側でカスタムでconfを書く場合、必ずlocalディレクトリ内で書くことが決まっています。これはconfの優先度に関係しており、defaultよりもlocalディレクトリ内に書かれているconfファイルが優先的に処理をさせるという仕様がある為です。時々defaultにconfファイルを置いている事例を見ますが、Splunkはdefault内には絶対にconfを書かないように言ってますので、注意をしてください。トラブルのもととなります。
上記outputs.confを書きましたら念のため、configのデバッグを行いましょう。confのデバッグは次のコマンドで行います。
/opt/splunk/bin/splunk btool outputs list --debug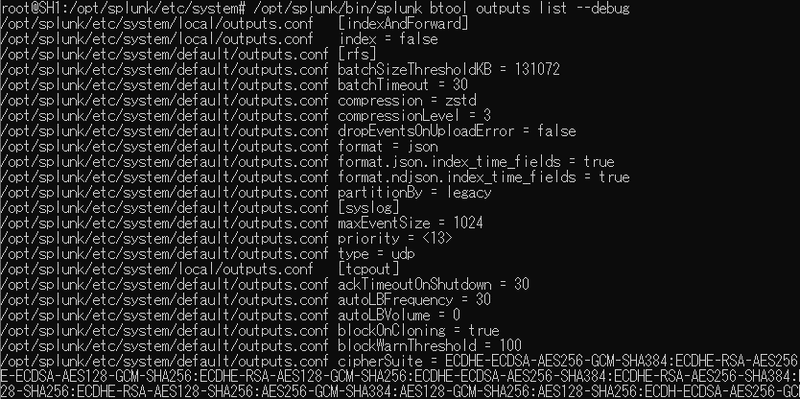
このデバッグを行う事でconfigが読まれる順番を確認することができます。出力結果をみていただくとわかるかと思いますが、基本的にはスタンザ(confファイルに書かれている"[ ]"で書かれているものをスタンザと呼びます)毎にlocal→defaultと読み込んでいる事が判るかと思います。
設定が読み込まれる事が確認できましたので、Splunkを再起動します。
/opt/splunk/bin/splunk restart再起動してしばらく時間が経った後にSearchから”index=_*”で検索をしてみてください。下図のようにhostフィールドに、初期設定時にコマンドで設定したhostnameの値が載ってくれば、設定が成功したことになります。なお同じことをインデクサー以外のすべてのインスタンス(Splunk Enterpriseがインストールされているインスタンス)に対してこれを行う必要がありますが、UFについてはまた別のconfの書き方及びconfファイルの展開手法をしますので、それは次の章で触れたいと思います。

Indexerに対する設定作業
作業: Listenポートの設定
Indexerはログを格納する機能を有しています。この後設定していきますが、UFからデータを受けるのもIndexerの役目です。その為の通信ポートの設定がデフォルトでは設定されていません。ListenポートはSplunkでは9997/TCPを標準の設定としています。Indexerにターミナルで入って以下のコマンドを実行して、Listenを有効化してからSplunkを再起動します。
/opt/splunk/bin/splunk enable listen 9997
/opt/splunk/bin/splunk restartなお、この設定はGUIでは[設定]→[転送と受信]→[データの受信]から確認ができます。また、コマンドで確認する場合、以下コマンド
/opt/splunk/bin/splunk display listenで確認が取れます。GUIがあるのにコマンド?と思われるかもしれません。後述しますが最終的に、IndexerのSplunk Webは無効化してしまいます(Splunkの推奨設定)ので、Indexerについてはコマンドで確認をしていきます。Splunk Webについては起動時に負荷がかかる事や、脆弱性が見つかるケースがある事から、特にIndexerはそもそもGUIは不要ですので、次のコマンドで無効化してしまいましょう。
/opt/splunk/bin/splunk disable webserverUniversal Forwarderを組み込む
解説: Universal Forwarderの設定の展開について
UFの設定については、Splunkのトポロジーでも書きました、Splunkの管理用コンポーネント、”Deployment Server(DS)”を使って管理をしていくのが最も簡単な方法です。確かに、UFの中で直接confファイルを書いても良いのですが、UFが増えていくと管理が煩雑になってしまいます。その為DSを使ったconfの展開を覚えておいても損はないと思いますので、今回のケースではDSを使ったconfファイルの展開をします。
DSはSearchheadで動かします。Searchheadの章で書いたサーバーロールでSearchheadのデプロイサーバーを有効化しておいてください。
作業: Deployment Serverを使ったconfの展開
それではconfを展開していきます。作業を開始する前にUFの存在をDS
に知ってもらう必要があります。UFに入って以下のコマンドを実行してDSに対してポーリングを行う設定を投入してください。
/opt/splunkforwarder/bin/splunk set deploy-poll [DSのIP、ここではSearchheadのIP]:8089
/opt/splunkforwarder/bin/splunk restartここで再起動は不要なはずですが、念のため?、再起動をしておきます。
正しくforwarderがDSに認識されると、Searchhead(兼DS)の[設定]→[フォワーダー管理]に以下のように管理対象のforwarderが現れます。
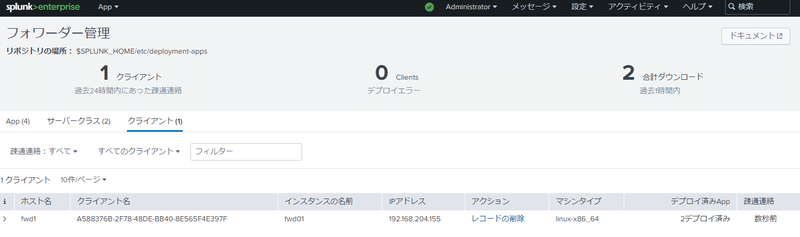
上の図ではすでにAppの展開等を行ってしまった後であるため(キャプチャ忘れ💦)、一部カウンターがあがっている箇所がありますが、概ねこのような画面が表示されます。ついでにMonitoring ConsoleからUFを監視できるように設定をしてしまいます。Monitoring Consoleを立ち上げて、[設定]→[フォワーダーモニターリング設定]をクリックして開きます。デフォルトでは無効化されている監視を有効化して[保存]をクリックして設定を適用しましょう。

設定が正常に反映され、しばらく時間が経つと、Monitoring ConsoleからUFのインスタンス情報を見る事ができるようになります。

さて、前準備ができました。それではConfの展開を行っていきます。まずはUFに対してデータを送信するための設定を入れて行きましょう。外部にデータを送信する場合は"outputs.conf"を使用します。このoutputs.confをSearchhead(兼DS)に作成します。DSでUFに対してconfを展開する場合、以下のディレクトリにフォルダ/ファイルを作成します。
/opt/splunk/etc/deployment-apps/実際にAppsを作成した際のディレクトリ・ファイル構成を例示します。すみません、自分で作業をした結果、いろんなAppsフォルダができてしまったため、一部抜粋をしますが、indexerにデータを送るためのoutputs.confはdeployment-apps配下のuf_base/local/outputs.confに作成をしています。

この内容がそのままUFのAppsディレクトリ配下に展開されます。outputs.confの中身ですが、以下のようになります。
[tcpout]
defaultGroup = my_indexer
[tcpout:my_indexer]
server = [IndexerのIP]:9997通信先のポート番号については先にIndexerの項目で設定をしましたね。さて、それではこのconfをDSを使って展開します。SearchheadのSplunk Webにアクセスして[設定]→[フォワーダー管理]をクリックします。

私のミスでforwarder用のサーバーに同じホスト名(こちらはOS上で設定したホスト名)が出来てしまっていますが…これからfwd02のインスタンスに対してベースとなる"uf_base"のconfigを適用します。まずはインスタンスを管理するための箱となる”サーバークラス”を作成していきます。
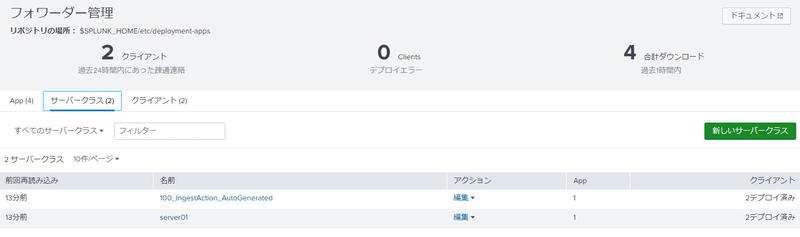
[新しいサーバークラス]をクリックします。

なんでもいいので名前を付けましょう。一応わかりやすくしたほうがいいです(笑)。

[Appの追加]をクリックします。

ここを見ると左側に先ほど作成したディレクトリ[uf_base]があるのがわかります。改めてSearchheadのdeployment-appsディレクトリを見てみます。

このフォルダがそのままAppとしてAppの編集画面に載っている事が解かるかと思います(Appは一般的にはアプリケーションですが、Splunkの世界の場合、設定ファイルの管理の単位の事も指します)。それでは基本設定を投入した「uf_base」を展開しましょう。"uf_base"を選択して[保存]をクリックしてください。

保存をクリックすると次のような画面になります。

これだけだと、インストールするAppを指定しただけの状態です。次にこのサーバークラスにこのAppをインストールするクライアントを指定します。[クライアントの追加]をクリックします。

ここでは追加対象となるインスタンスを選びます。インスタンスの洗濯は画面上部の[含める]や[除外]の条件に記入して追加します。

条件を記入したら[プレビュー]をクリックして、自分が設定した条件に当てはまる端末が選択されているか、確認をします。選択が成功していると、画面下部のクライアント一覧の左端[一致]にチェックマークが入ります。問題なさそうですので[保存]をクリックします。

はい、これで完了です。あとは自動的にAppがUFに展開されます。念のため、フォワーダー管理の画面に戻ります。「1デプロイ済」となっており、成功したように見えます。

念のため、UFをインストールしているホストに繋いで/opt/splunkforwarder/etc/apps/フォルダ配下をみてみましょう。

uf_baseフォルダが作成されている事がわかると思います。中には先ほど作成したoutputs.confが格納されています。確認のため、btoolコマンドを使いconfのデバッグをかけてみます。

はい、無事に読み込まれている事が確認できました。無事に追加できた場合、UFから内部の監査ログ等が送付されてきます。サーチからindex=_* (下図の例では_internalで内部ログを具体的にしています)で検索を行い、正常にログが送られてきている事を確認してください。もし確認できない場合、少し時間をおいて再度確認。それでもだめならUFを手動で再起動をしてみても良いかもしれません。

おわりに
以上でSplunkの分散サーチ環境の基本的な構築の方法について解説をしました。Splunkを使ったことが無い人向けも考えてやや冗長な説明となりましたが、Splunkの分散サーチ構成の理解の一助になれば幸いです。このあと基本的なデータの追加手順についても解説をしたいと思います。ご期待ください!
これまでの記事については以下をご参照ください。
この記事が気に入ったらサポートをしてみませんか?