
Splunkの分散サーチ環境の構築(前編)

はじめに
実に2年ぶりにBlogを書いてみようかと思います。私自身の変化として、セキュリティを仕事にはしていましたが、現在は専業ではなく、これまでの経験を生かして、セキュリティを主眼としてシステムの利活用をアドバイスする仕事へと変わりました。
さてさて、そんなセキュリティの現場に関わらず、データ分析の現場では、多くの所でSplunkが稼働しています。Splunkを利活用するにあたり、ほとんどの方は「SPLがー」となりますが、SPL(Splunkで使われる検索の言語)については様々な情報があふれていて、ググればある程度分かるのでは?。他方、そのシステムについては知られていない事が多い事が現状です。特にSplunkをスタンドアロンで使うならまだしも(スタンドアロンはインストールするだけで動きます)、分散構成となると途端に情報が限られてきます。今回はそのSplunkの分散構成の基本を、実際の構築を通して解説していきたいと思います。
Splunkの基本的な構成要素
Splunkを知るうえでSplunkの構成要素の理解は欠かせません。Splunkを構成するコンポーネントは「Forwarder」「Indexer」「Searchhead」になります。
これらのコンポーネントは、「サーチング=検索する」「パーシング=データを解析する」「インデクシング=データをインデックス化する」「インプット=データを収集Splunkに取り込む」と言った機能を持っています。それぞれの機能とコンポーネントは下図のマッピングは以下となります。

セキュリティインシデントが発生して、急遽ログを分析する基盤を立ち上げなければ!となった時にスタンドアロンでSplunkを構築するケースはこのような構成、これが最小構成になります。そして一般的に業務で使う場合の最小構成は次のようになるのではないかと思います。これが分散構成の最小単位となるのではないかと思います。

ここで、これまで出てこなかった「Deployment Server(DS)」が出てきますが、これはForwarderを管理するためのコンポネントになります。DSはあっても無くても動きますが、無い場合、confの管理が煩雑になるので導入は強く推奨します。DSは通常(このケースの場合)、Searchheadと同居させてしまうのが良いかと思います。もっと大規模になった場合、ライセンス管理のコンポーネント(License Manager)等、負荷がかからない管理系のコンポネントと同居させるのが推奨です。
そして、次が今回の本題の分散構成です。SplunkではDistributed Searchと呼んでいます。以下リンクで公式ドキュメントによる解説がされています。
Splunkのドキュメントではサーチヘッドクラスターやインデクサークラスターについて言及されていますが、クラスター化の要素を取り除くと以下のような構成になります。
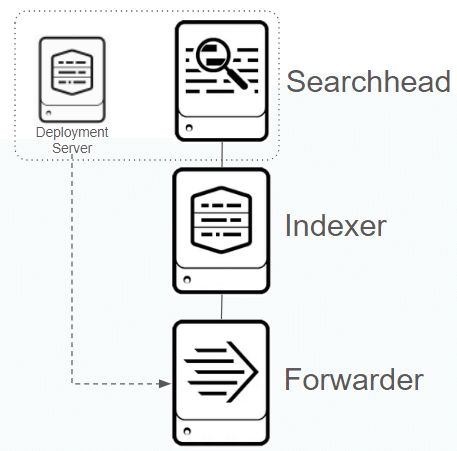
もちろん、ここまでやったらクラスター組んじゃえよ!、と言う話もありますが、クラスターを組むとなると、それなりに複雑な設定が必要となってきます。従ってまずは分散構成の基本、これを目指して行きたいと思います。なお、Splunkに詳しい方はお気づきだと思いますが、ログの取り込みについては別途、Splunk Forwarderを用意する必要はありません。Indexer内のディレクトリを監視させる等をすればデータを取り込む事も可能ですが、今回はSplunkのスケーラブルな構成の最小構成から、Splunkを学ぶことが目的のため、Forwarderを建てています。ご了承ください。
Forwarderについて
本編に入る前に1点、Forwarderについて書きたいと思います。Forwarderは2種類存在しています。一つがUniversal Forwarder(通称: UF)、二つ目にHeavy Weight Forwarder(通称: Heavy Forwarder: HF)です。HFと呼ばれるものの実態はSplunk Enterprise(ソフトウェア版のSplunk)の事を指します。Forwarderが持つログ収集・転送機能の他にIndexingや、ログの加工(ログの特定の文字列をマスクする)、ルーティング等ができます。実態はSplunk Enterpriseそのものなので、高機能です。ただし、HFはSplunk Enterpriseそのものであることから、負荷がかかる事もあり、他のサーバーとの共有はお勧めしません。
一方のUFはログの収集と転送に特化しています。従って、例えばWindows/Linuxホストからログを収集する場合、サーバーにUFをインストールして、UFの機能を使ってログを収集してUFがIndexerにログを転送する、といった事が、システム影響(負荷)を極小化した上で実現可能です。
この辺の特徴を知ったうえでシステムを設計してください。今回のBlogではUFを使った構成について、解説をします。なお、フォワーダーの種類に関するSplunk docsについては以下Uにありますので、是非一度見てみてください。
Splunkのライセンスについて
Splunk Enterpriseのライセンスについては5つの種類にわけられます。詳細の解説は省きますが、今回の検証で使用するライセンスはEnterpriseトライアルライセンスです。これは試用版のライセンスとなります。Splunkにはフリー版のライセンスもありますが、フリー版のライセンスは分散環境には対応していませんの注意してください(フリー版はスタンドアロン用かつ一日あたり500MB未満のライセンス)。
Enterpriseライセンス
このライセンスは複数ユーザー、分散デプロイのサポート、アラート、ロールベースのセキュリティ、シングルサインオン、スケジュールしたPDF配信、無制限データ等を使用可能なライセンスです。平たく言うと、ライセンス費用を支払ったユーザに対するライセンスで、基本的には制限がないライセンスです。ただし、SplunkのライセンスはIngest課金(データの取り込む量課金)になっています。複数の条件が重なりライセンス違反の状態となると検索ができなくなりますのでご注意を。
https://docs.splunk.com/Documentation/Splunk/latest/Admin/Aboutlicenseviolations
フォワーダーライセンス
Splunkをフォワーダー(Heavy Forwarder)として設定する場合に、このグループを使用します。
フリーライセンス
Splunk Freeの実行時にこのグループを使用します。このライセンスには認証もユーザーおよびロールの管理もなく、インデックスボリュームは、1日当たり500 MBです。
Enterpriseトライアルライセンス
ダウンロードトライアル版です。今回の分散サーチ環境を試験的に構築する場合、このライセンスが必要です。なお、他のライセンスに切り替えると、トライアル版に戻すことはできません。Enterpriseライセンスをインストールするか、Splunk Freeに切り替える必要があります。
次の章に向けて
ここまでで、Splunkの基本的なトポロジーやコンポネント、ライセンスについて説明しました。スタンドアロン構成ならなやむことはないのですが、分散サーチ環境を構築するとなるとライセンスを意識することが必須となります。分散サーチ環境は基本的には有償ライセンスになるので、なかなか構築する機会はないと思いますが…
さて、次の章では実際に各コンポーネントをインストールしていく作業のご紹介をします。
この記事が気に入ったらサポートをしてみませんか?