[技術日誌]地域メッシュコードを判定する&なんj論文レビュー

座標情報から地域メッシュコードを判定する
地域メッシュコードとは
統計に利用するために、緯度・経度に基づいて地域をほぼ同じ大きさの網の目(メッシュ)に分けたものである。メッシュを識別するためのコードを地域メッシュコードと言う。
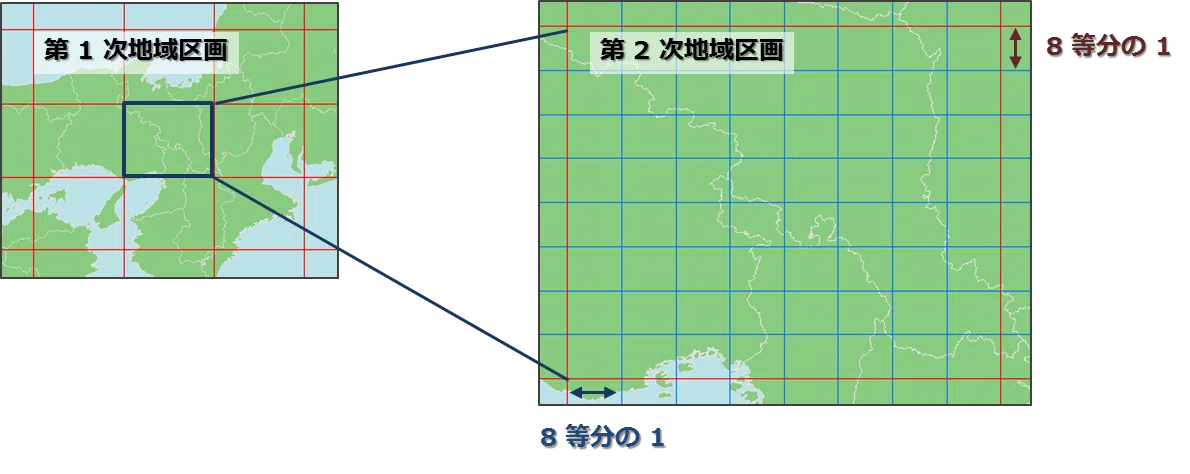
1次メッシュコード
第1次メッシュ(一次メッシュ、正式名称は第1次地域区画)は20万分の1地勢図の1図葉の区画を1単位区画としたもので、緯度差は40分、経度差は1度となっている。1辺の長さは約80kmである。
1次メッシュコード
4桁の数字で、上2桁が緯度(1.5倍して分以下を切り上げたもの)、下2桁が経度(下2桁)を表す。1次メッシュコードはメッシュの南西端の緯度経度を用いて次式で算出される:緯度をlat[度]、経度をlon[度]とすると、(lat×1.5×100)+(lon−100)
例:
(35.6895, 139.6917) の1次メッシュコードは5339(53-39)
・35.6895 * ( 1.5 ) = 53.53425 → 53
・139.6917 - 100 = 39.6917 → 39
2次メッシュコード
第2次メッシュ(二次メッシュ、正式名称は第2次地域区画)は第1次メッシュを緯線方向及び経線方向に8等分してできる区域で、2万5千分の1地形図の1図葉の区画に対応する。緯度差は5分、経度差は7分30秒で、1辺の長さは約10kmである。
2次メッシュコード
2桁の数字で、上1桁が緯度方向、下1桁が経度方向を表す。これに1次メッシュコードを合せて5339-23のように表す。
例題:
(35.6895, 139.6917) の2次メッシュコードは533945
(左から4番目までの数字は1次メッシュコード)
まず、1次メッシュの緯度差は40分、経度差は1度より、1次メッシュにおける余りを求める。
この場合は、緯度経度の単位を度から分に変換すると、計算しやすい
・35.6895 * 60 % 40 = 21.37
・139.6917 * 60 % 60 = 41.502
そして、2次メッシュの緯度差は5分、経度差は7分30秒より2次メッシュコードを余りは切り捨てて算出する。
・21.37 // 5 = 4
・41.502 // 7.5 = 5
3次メッシュコード
第3次メッシュ(三次メッシュ、正式名称は基準地域メッシュないし第3次地域区画)は第2次メッシュを緯線方向及び経線方向に10等分してできる区域である。緯度差は30秒、経度差は45秒で、1辺の長さは約1kmである。
3次メッシュコード
2次メッシュコードと同様に2桁の数字で、上1桁が緯度方向、下1桁が経度方向を表す。これに1次・2次メッシュコードを合せて5339-23-43のように表す。
例題:
(35.6895, 139.6917) の2次メッシュコードは53394525
(左から4番目までの数字は1次メッシュコード、左から5・6番目の数字は2次メッシュコード)
まず、2次メッシュの緯度差は5分、経度差は7分30秒より、1次メッシュにおける余りを求める。
この場合は、緯度経度の単位を度から秒に変換すると、計算しやすい
・35.6895 * 60 * 60 % 300 = 82.2
・139.6917 * 60 * 60 % 450 = 240.12
そして、2次メッシュの緯度差は30秒、経度差は45秒より3次メッシュコードを余りは切り捨てて算出する。
・82.2 // 30 = 2
・240.12 // 45 = 5
Pythonコード
def calculate_mesh_code(latitude, longitude):
# 上2桁が緯度(1.5倍して分以下を切り上げたもの)、下2桁が経度(下2桁)
# 緯度差は40分、経度差は1度
lat_base = int(latitude * 1.5)
lon_base = int(longitude - 100)
# 度から分に変換
# 緯度差は5分、経度差は7分30秒
p = int((latitude * 60 % 40) // 5)
q = int(longitude * 60 % 60 // 7.5)
# 度から分に変換
# 緯度差は30秒、経度差は45秒
r = int((latitude * 60 * 60 % 300) // 30)
s = int((longitude * 60 * 60 % 450) // 45)
return f"{lat_base:02d}{lon_base:02d}{p}{q}{r}{s}"
# ユーザー入力
lat = float(input("緯度を入力してください(例: 35.6895): "))
lon = float(input("経度を入力してください(例: 139.6917): "))
# メッシュコードの計算と表示
mesh_code = calculate_mesh_code(lat, lon)
print(f"地域メッシュコード: {mesh_code}")
# 緯度を入力してください(例: 35.6895): 35.6895
# 経度を入力してください(例: 139.6917): 139.6917
# 地域メッシュコード: 53394525なんj論文レビュー
AI 科学者: 完全に自動化されたオープンエンドの科学的発見に向けて
SOTA:https://paperswithcode.com/paper/the-ai-scientist-towards-fully-automated-open
Here's a creative imaginary 2ch thread discussing the paper in Nanj style:
1 名前:風吹けば名無し[] 投稿日:2024/08/21(水) 18:23:45.67 ID:abcd1234
ワイ、この論文読んだんやが、グロッキングってなんやねん
誰か詳しく説明してクレメンス
2 名前:機械学習研究者 ◆ML1234abc [] 投稿日:2024/08/21(水) 18:25:12.34 ID:efgh5678
>>1
グロッキングは、ニューラルネットワークが長時間の学習後に突然汎化能力を獲得する現象やで
この論文はデータ拡張でそれを加速させる手法を提案しとるんや
3 名前:風吹けば名無し[] 投稿日:2024/08/21(水) 18:26:59.01 ID:ijkl9012
へー面白そうやな
でもデータ拡張ってよく聞くけど、数学の演算に使うのは珍しくない?
4 名前:数学者 ◆MATH9876 [] 投稿日:2024/08/21(水) 18:28:37.89 ID:mnop3456
>>3
そうやな。普通、データ拡張は画像処理とかで使われるんや
数学演算、特にモジュラー算術に応用するのは斬新やと思うで
5 名前:深層学習エンジニア[] 投稿日:2024/08/21(水) 18:30:22.56 ID:qrst7890
オペランドの反転と否定を使ってるんは面白いアプローチやな
特に除算でうまくいってるのが印象的や
6 名前:AI倫理学者 ◆ETHICS123 [] 投稿日:2024/08/21(水) 18:32:48.23 ID:uvwx1357
でも、こういったデータ拡張技術を現実世界の重要なアプリケーションに適用する際の倫理的な懸念については全く触れられてへんな
その辺りの議論も必要やと思うで
7 名前:風吹けば名無し[] 投稿日:2024/08/21(水) 18:34:15.90 ID:yzab2468
>>6
倫理的な懸念って例えばどんなんがあるんや?
8 名前:AI倫理学者 ◆ETHICS123 [] 投稿日:2024/08/21(水) 18:36:03.45 ID:uvwx1357
>>7
例えば、この手法を金融や医療のAIシステムに使った場合、拡張されたデータに基づいて予測や判断をするわけやから、その結果の信頼性や公平性にどう影響するかという問題があるんや
9 名前:機械学習研究者 ◆ML1234abc [] 投稿日:2024/08/21(水) 18:38:29.78 ID:efgh5678
>>8
確かにその通りや。ただ、この研究はあくまで基礎研究の段階やから、そこまで踏み込んでへんのかもしれへんな
今後の課題として触れるべきやったかもしれん
10 名前:統計学者[] 投稿日:2024/08/21(水) 18:40:55.12 ID:cdef9876
ワイが気になるのは、異なる拡張確率の影響やな
15%と30%で結果が違うって書いてあるけど、もっと細かく調べる必要があると思うで
11 名前:プログラマー[] 投稿日:2024/08/21(水) 18:42:37.89 ID:ghij3456
実装の詳細がもうちょい欲しかったな
特にデータ拡張の具体的なコードが見たかったわ
12 名前:認知科学者 ◆COGNITIVE [] 投稿日:2024/08/21(水) 18:44:52.01 ID:klmn7890
グロッキング現象自体の理論的な説明がもっと欲しいな
データ拡張がなぜこれを促進するのか、認知的な観点からの考察があれば面白かったと思うで
13 名前:風吹けば名無し[] 投稿日:2024/08/21(水) 18:46:18.67 ID:opqr1234
なんか難しそうやな...
ワイにはさっぱりわからんわ
14 名前:機械学習研究者 ◆ML1234abc [] 投稿日:2024/08/21(水) 18:48:03.45 ID:efgh5678
>>13
確かに専門的な内容やけど、要はAIの学習を工夫して効率よくできるようにする研究なんや
日々の勉強でも、問題の見方を変えたり逆から考えたりすると理解が深まるやろ?
それと似たようなことをAIの学習でもやってみた、って感じやな
15 名前:計算機科学者[] 投稿日:2024/08/21(水) 18:50:29.12 ID:stuv5678
他のニューラルネットワークアーキテクチャでも同じような結果が得られるんかな?
トランスフォーマー以外でも試してみる価値はあると思うで
16 名前:数学教育者 ◆MATHEDU [] 投稿日:2024/08/21(水) 18:52:41.89 ID:wxyz9012
この研究結果を数学教育に応用できる可能性もあるんちゃうか?
AIを使った個別指導システムの開発なんかに役立つかもしれんな
17 名前:風吹けば名無し[] 投稿日:2024/08/21(水) 18:54:07.56 ID:abcd5678
>>14
なるほど!そう言われるとちょっとわかった気がするわ
ありがとうやで!
18 名前:機械学習研究者 ◆ML1234abc [] 投稿日:2024/08/21(水) 18:55:52.23 ID:efgh5678
>>17
ええんやで!
こういう研究を重ねていくことで、AIがより効率的に学習できるようになって、将来はもっと賢いAIが作れるかもしれんのや
19 名前:哲学者 ◆PHILO1234 [] 投稿日:2024/08/21(水) 18:57:38.90 ID:ijkl3456
でもな、AIが効率的に学習するっていうのは、本当の「理解」につながるんかっていう疑問もあるんや
人間の学習プロセスとの違いについても考える必要があるんちゃうか?
20 名前:機械学習研究者 ◆ML1234abc [] 投稿日:2024/08/21(水) 18:59:25.67 ID:efgh5678
>>19
おっしゃる通りや。AIの「理解」と人間の理解の違いは重要な研究テーマやな
この論文はあくまでAIの学習効率を上げる手法の提案やけど、その先にある「理解」の本質に迫る研究も必要やと思うで
21 名前:認知科学者 ◆COGNITIVE [] 投稿日:2024/08/21(水) 19:01:13.45 ID:klmn7890
>>19
>>20
その議論おもろいな。AIの「理解」と人間の理解の違いを考えると、このグロッキング現象自体が人間の「アハ体験」みたいなもんなんちゃうかと思えてくるわ
22 名前:風吹けば名無し[] 投稿日:2024/08/21(水) 19:03:02.12 ID:mnop5678
アハ体験って何や?
23 名前:認知科学者 ◆COGNITIVE [] 投稿日:2024/08/21(水) 19:04:48.89 ID:klmn7890
>>22
アハ体験っていうのは、突然何かを理解したり問題が解決したりする瞬間のことやで
「あ、そうか!」って急に分かる感じやな
グロッキングもAIがそういう状態になってる可能性があるんや
24 名前:深層学習エンジニア[] 投稿日:2024/08/21(水) 19:06:37.56 ID:qrst7890
でもそう考えると、このデータ拡張手法って人間の学習にも応用できそうやな
例えば数学の問題を逆から解いてみるとか、負の数で考えてみるとか
25 名前:数学教育者 ◆MATHEDU [] 投稿日:2024/08/21(水) 19:08:25.23 ID:wxyz9012
>>24
それええな!実際、そういう方法は数学教育でも使われとるで
この研究はそういう教育方法の有効性を裏付ける結果にもなっとるんかもしれんな
26 名前:AI倫理学者 ◆ETHICS123 [] 投稿日:2024/08/21(水) 19:10:11.90 ID:uvwx1357
でもな、人間の学習とAIの学習を安易に結びつけるのも危険やと思うで
AIの学習プロセスを人間化して解釈しすぎると、AIの限界を見誤る可能性もあるんちゃうか
27 名前:統計学者[] 投稿日:2024/08/21(水) 19:12:03.67 ID:cdef9876
>>26
確かにその通りや。AIの学習と人間の学習の類似性を議論するなら、もっと厳密な統計的検証が必要やと思うわ
28 名前:プログラマー[] 投稿日:2024/08/21(水) 19:13:52.34 ID:ghij3456
ワイ的には、この手法を他のタスクにも適用してみたいな
自然言語処理とかでも似たような効果があるんちゃうか?
29 名前:機械学習研究者 ◆ML1234abc [] 投稿日:2024/08/21(水) 19:15:39.01 ID:efgh5678
>>28
おもろい発想やな!確かに自然言語処理でも文の構造を変えたりする拡張はあるけど、この研究の知見を活かせば新しいアプローチが見つかるかもしれんな
30 名前:風吹けば名無し[] 投稿日:2024/08/21(水) 19:17:25.78 ID:stuv1234
なんかみんな凄いな...
ワイにはまだ難しいけど、AIの研究って奥が深いんやな
31 名前:哲学者 ◆PHILO1234 [] 投稿日:2024/08/21(水) 19:19:14.45 ID:ijkl3456
結局のところ、この研究はAIの学習プロセスをより効率的にする方法を見つけただけやけど、それが本当の「理解」や「知能」につながるかはまだ分からんのやな
これからのAI研究では、効率だけやなく、理解の質についても深く考えていく必要があるんちゃうかな
32 名前:機械学習研究者 ◆ML1234abc [] 投稿日:2024/08/21(水) 19:21:03.12 ID:efgh5678
>>31
その通りや。効率と理解の質、両方を追求していくのが今後の課題やな
この論文はその道筋の一つを示したもんやと思うで
33 名前:風吹けば名無し[] 投稿日:2024/08/21(水) 19:22:48.89 ID:wxyz5678
なんやかんや言うても、AIはどんどん賢くなっていくんやろな
ちょっと怖いような、楽しみなような...
34 名前:AI倫理学者 ◆ETHICS123 [] 投稿日:2024/08/21(水) 19:24:37.56 ID:uvwx1357
>>33
そやな。だからこそ、AIの発展と並行して倫理的な議論も深めていく必要があるんや
技術の進歩と人間社会のバランスを取るのが、これからの大きな課題になるで
35 名前:機械学習研究者 ◆ML1234abc [] 投稿日:2024/08/21(水) 19:26:25.23 ID:efgh5678
みんな、ええ議論ができたと思うで
この論文を軸に、AIの学習、人間の学習、倫理、哲学まで話が広がったな
こういう多角的な視点が、これからのAI研究には必要なんやと改めて感じたわ
LongWriter: 長いコンテキストの LLM から 10,000 語以上の単語生成を実現
SOTA:https://paperswithcode.com/paper/longwriter-unleashing-10000-word-generation
1 名前:風吹けば名無し[sage] 投稿日:2024/08/21(水) 09:13:45.12 ID:a1b2c3d4
ワイ、この論文読んだんやけど長文生成能力のブレイクスルーやと思うで
https://arxiv.org/abs/2408.07055
2 名前:風吹けば名無し[sage] 投稿日:2024/08/21(水) 09:15:23.45 ID:e5f6g7h8
おっ、面白そうやな。要約してクレメンス
3 名前:風吹けば名無し[sage] 投稿日:2024/08/21(水) 09:17:11.67 ID:i9j0k1l2
ワイが要約したるで
・現在のLLMは長い入力は処理できるけど、出力は2000語くらいで止まる
・AgentWriteってのを使って長い出力のデータセット作った
・それで学習させたら1万語以上の出力ができるようになった
・DPOってので更に質も上がった
4 名前:NLP研究者 ◆abcd123456[sage] 投稿日:2024/08/21(水) 09:20:45.89 ID:m3n4o5p6
興味深い研究やね。特にAgentWriteの手法は革新的や。
長い出力を生成するタスクを小さなサブタスクに分解して、
既存のLLMで長文を生成するアプローチは斬新やわ。
5 名前:風吹けば名無し[sage] 投稿日:2024/08/21(水) 09:22:33.21 ID:q7r8s9t0
>>4
ほんまか?ワイには普通に思えるんやが
6 名前:機械学習エンジニア[sage] 投稿日:2024/08/21(水) 09:25:17.54 ID:u1v2w3x4
>>5
いや、これ結構すごいで。今までのLLMの限界を突破する方法を示したんや。
特に、SFTデータの出力長が生成長の上限になってるって発見は重要やで。
7 名前:NLPの学部生[sage] 投稿日:2024/08/21(水) 09:27:42.98 ID:y5z6a7b8
すまん、ワイにはちょっと難しすぎるわ。SFTってなんや?
8 名前:機械学習研究者[sage] 投稿日:2024/08/21(水) 09:30:05.32 ID:c9d0e1f2
>>7
SFTはSupervised Fine-Tuningの略やで。要は教師あり学習でモデルを微調整することや。
この研究では、長い出力のデータでSFTすることで、モデルの出力長を伸ばしたんや。
9 名前:言語モデル開発者[sage] 投稿日:2024/08/21(水) 09:32:50.76 ID:g3h4i5j6
個人的に面白いと思ったのは、DPOを使って更に性能向上させてる点やな。
Direct Preference Optimizationは最近注目されてる手法やけど、
長文生成タスクでもうまく機能するんやな。
10 名前:風吹けば名無し[sage] 投稿日:2024/08/21(水) 09:35:22.09 ID:k7l8m9n0
なるほどなぁ。ワイにはさっぱりやけど凄そうやな
11 名前:AI倫理学者[sage] 投稿日:2024/08/21(水) 09:38:14.43 ID:o1p2q3r4
技術的には素晴らしい成果やけど、これによって大量の偽情報が生成される可能性も高まるよな。
長文になればなるほど、人間が全てを検証するのは難しくなる。
この技術の応用には慎重になるべきやと思うで。
12 名前:風吹けば名無し[sage] 投稿日:2024/08/21(水) 09:40:37.65 ID:s5t6u7v8
>>11
それな。技術の進歩はええけど、悪用されんか心配やわ
13 名前:自然言語処理の教授[sage] 投稿日:2024/08/21(水) 09:43:09.21 ID:w9x0y1z2
確かに倫理的な懸念はあるけど、この技術自体は素晴らしいと思うで。
長文生成能力の向上は、要約や文書作成支援など、多くの応用可能性がある。
大事なのは、この技術をどう使うかという我々人間の側やな。
14 名前:AI産業アナリスト[sage] 投稿日:2024/08/21(水) 09:46:28.54 ID:a3b4c5d6
ビジネス的な観点から見ても、これは大きなブレイクスルーやと思う。
長文生成能力の向上は、コンテンツ作成や顧客サポートなど、
様々な産業に影響を与える可能性があるで。
15 名前:プロンプトエンジニア[sage] 投稿日:2024/08/21(水) 09:49:52.87 ID:e7f8g9h0
ワイ的に面白いのは、AgentWriteの「計画」ステップやな。
人間の文章作成プロセスを模倣してるみたいで、
これはプロンプトエンジニアリングにも応用できそうや。
16 名前:コグニティブサイエンス研究者[sage] 投稿日:2024/08/21(水) 09:52:36.10 ID:i1j2k3l4
>>15
同感や。AIの思考プロセスを人間に近づけることで、
より自然な文章生成ができるようになるんやろうな。
これは認知科学的にも興味深い研究やと思うで。
17 名前:NLPの修士課程学生[sage] 投稿日:2024/08/21(水) 09:55:19.43 ID:m5n6o7p8
すまんが、ワイにはまだ難しいわ。でも勉強になったで。
将来はこういう研究できるようになりたいンゴ...
18 名前:風吹けば名無し[sage] 投稿日:2024/08/21(水) 09:57:42.76 ID:q9r0s1t2
ワイらには難しすぎる話やけど、AIの進化はどんどん進んでるんやなぁ
ちょっと怖いけど、楽しみでもあるわ
DeepSeek-Prover-V1.5: 強化学習とモンテカルロ木探索のための証明アシスタントフィードバックの活用
SOTA:https://paperswithcode.com/paper/deepseek-prover-v1-5-harnessing-proof
Here's a creative imaginary 2ch-style thread discussing the paper, with various experts and beginners:
1 名前:数学系無職 ◆MaTH1nEmP1 [sage] :2024/08/22(木) 09:15:23.12 ID:MaTH0000
DeepSeek-Prover-V1.5の論文きたで
https://arxiv.org/abs/2408.08152
miniF2Fのテストセットで63.5%、ProofNetで25.3%達成したらしい
2 名前:AI研究者 ◆AI12345678 :2024/08/22(木) 09:17:45.67 ID:AIAI1111
おっ、またDeepSeekか。前のV1からどれくらい進歩したんやろ
3 名前:論理学者 ◆LogiC98765 :2024/08/22(木) 09:20:12.34 ID:LOGI2222
ほう、RMaxTSってのが面白そうやな。探索と生成のバランス取るのは難しいんやが
4 名前:数学初心者 :2024/08/22(木) 09:22:55.89 ID:NUBI3333
なんか難しそう...数式ばっかりで頭痛くなってきた
5 名前:機械学習エンジニア ◆ML987654ML :2024/08/22(木) 09:25:33.21 ID:MLEN4444
>>4
初心者にはちょっと難しいかもね。でも基本的には、AIが数学の証明を自動でやろうとしてるんだよ
6 名前:計算論理学者 ◆CompLog123 :2024/08/22(木) 09:28:17.56 ID:CLOG5555
Monte Carlo Tree Searchを使ってるのが良いね。探索空間が広いからこそ効果的やろ
7 名前:数学教育者 ◆MathEdu456 :2024/08/22(木) 09:31:42.90 ID:MEDU6666
こういうAIの発展で、数学教育はどう変わっていくんやろか。証明の作り方を教えるのも変わってくるかもしれんな
8 名前:哲学者 ◆PhiLo789Ph :2024/08/22(木) 09:34:28.73 ID:PHIL7777
AIが数学的真理を発見するようになったら、数学の本質って何なんやろか。人間の直感はまだ重要なんかな
9 名前:統計学者 ◆StaTs321St :2024/08/22(木) 09:37:15.45 ID:STAT8888
サンプル効率がかなり良くなってるな。RMaxTSの効果大きいんやろうけど、もっと詳しく知りたいわ
10 名前:プログラマー ◆PRoG654321 :2024/08/22(木) 09:40:03.12 ID:PROG9999
実装の詳細が気になるな。並列化とかどうやってるんやろ
11 名前:数学者 ◆MATH111111 :2024/08/22(木) 09:42:51.34 ID:MATH1010
miniF2FとProofNetの結果、かなり良くなってるな。でも人間レベルまでまだ道のりは長そうや
12 名前:認知科学者 ◆CogSci7890 :2024/08/22(木) 09:45:37.89 ID:COGS1111
AIの証明と人間の証明プロセスの違いが興味深いわ。AIはどこまで「理解」してるんやろか
13 名前:数学系学生 :2024/08/22(木) 09:48:22.56 ID:GAKU1212
すごそう...でも具体的にどんな定理が証明できるようになったんやろ?
14 名前:計算機科学者 ◆CompSci456 :2024/08/22(木) 09:51:09.23 ID:COMP1313
>>13
論文の付録に具体例があるで。例えば、aime_1983_p9という問題とかな。高校数学レベルの問題やけど、AIがちゃんと証明できてる
15 名前:数理論理学者 ◆MathLog789 :2024/08/22(木) 09:54:33.78 ID:MLOG1414
Chain-of-Thoughtの手法を形式的証明に適用してるのが面白いな。自然言語での推論と形式的証明をつなげる試みや
16 名前:情報理論研究者 ◆InfoTh3ory :2024/08/22(木) 09:57:18.45 ID:INFO1515
探索と生成のバランス、まさに情報理論の観点から見ても興味深い。エントロピーと探索効率の関係とかもっと掘り下げて欲しいわ
17 名前:数学系無職 ◆MaTH1nEmP1 [sage] :2024/08/22(木) 10:00:05.67 ID:MaTH0000
みんな色んな視点があって勉強になるわ。AIと数学の未来、楽しみやな
18 名前:量子計算研究者 ◆QuanComp22 :2024/08/22(木) 10:03:42.89 ID:QUAN1616
量子コンピューターと組み合わせたらどうなるんやろか。探索空間爆発的に広がりそうやけど
19 名前:数学史研究者 ◆MathHist33 :2024/08/22(木) 10:06:27.34 ID:HIST1717
歴史的に見ても画期的やな。コンピューターによる定理証明の夢、ようやく現実味を帯びてきた感じやわ
20 名前:機械学習エンジニア ◆ML987654ML :2024/08/22(木) 10:09:15.56 ID:MLEN4444
>>18
量子版のMonte Carlo Tree Searchとか面白そうやな。でも実装難しそう...
21 名前:数学教育者 ◆MathEdu456 :2024/08/22(木) 10:12:03.23 ID:MEDU6666
>>7の続きやけど、こういうAIを使って、生徒の証明の誤りを指摘したり、ヒント出したりできそうやな
22 名前:論理学者 ◆LogiC98765 :2024/08/22(木) 10:14:51.78 ID:LOGI2222
>>21
それ面白いな。でもAIに頼りすぎると、人間の論理的思考力が衰えないか心配や
23 名前:AI倫理学者 ◆AIEthics11 :2024/08/22(木) 10:17:39.45 ID:ETHI1818
みんな技術的な話ばっかりやけど、こういうAIが発展することで、数学者の仕事はどうなるんやろ。倫理的な議論も必要やと思うで
24 名前:数学系無職 ◆MaTH1nEmP1 [sage] :2024/08/22(木) 10:20:25.12 ID:MaTH0000
>>23
確かに重要な指摘や。AIと人間の共存、これからの大きなテーマになりそうやな
25 名前:プログラマー ◆PRoG654321 :2024/08/22(木) 10:23:13.67 ID:PROG9999
技術的な話に戻るけど、このシステムのスケーラビリティはどうなんやろ。もっと複雑な定理にも対応できるんかな
26 名前:計算論理学者 ◆CompLog123 :2024/08/22(木) 10:26:01.34 ID:CLOG5555
>>25
良い質問や。論文見る限り、まだ高校〜学部レベルの問題が中心みたいやけど、将来的にはもっと難しい定理にも挑戦していくんやろな
27 名前:数学初心者 :2024/08/22(木) 10:28:49.89 ID:NUBI3333
なんか議論についていけへん...でもAIが数学の問題解いてくれるのは便利そう
28 名前:統計学者 ◆StaTs321St :2024/08/22(木) 10:31:37.56 ID:STAT8888
>>27
心配せんでええで。こういう技術が発展すれば、将来的には数学の学習支援にも使えるようになるかもしれんで
29 名前:数理論理学者 ◆MathLog789 :2024/08/22(木) 10:34:25.23 ID:MLOG1414
論文の中で、Reinforcement Learningを使ってるのも興味深いな。証明のフィードバックを報酬として学習させてるわけや
30 名前:認知科学者 ◆CogSci7890 :2024/08/22(木) 10:37:13.78 ID:COGS1111
>>29
そうそう。人間の数学者も似たようなプロセスで学習してるわけやしな。AIの学習プロセスと人間の学習プロセスの類似点と相違点、もっと研究せなあかんわ
ControlNeXt: 画像とビデオ生成のための強力で効率的な制御
SOTA:https://paperswithcode.com/paper/controlnext-powerful-and-efficient-control
新しいAI画像生成技術「ControlNeXt」について語るスレ
1 名無しさん@お腹いっぱい。 2024/08/22(木) 09:15:23.12 ID:aB3cD4eF
ControlNeXtっちゅう新しい画像生成AI技術が出たらしいで
効率的で汎用性が高いらしいんやが、どうなんやろ
2 画像生成マスター 2024/08/22(木) 09:17:45.67 ID:gH5iJ6kL
まず注目すべきは、既存モデルへの影響を最小限に抑えつつ制御能力を追加している点やな
これによって、既存のLoRAウェイトとの互換性も保たれてる
3 AIリサーチャー 2024/08/22(木) 09:20:12.34 ID:mN7oP8qR
Cross Normalizationという新しい正規化手法も興味深いわ
学習の収束性向上に貢献してそうやね
4 機械学習初心者A 2024/08/22(木) 09:22:56.78 ID:sT9uV0wX
えっと、LoRAってなんですか?よく分からないです...
5 親切な上級者 2024/08/22(木) 09:25:33.21 ID:yZ1aB2cD
>>4
LoRAは「Low-Rank Adaptation」の略やで
大規模モデルを効率的に微調整する手法や
新しいタスクや領域に適応させるのに使うんや
6 効率化専門家 2024/08/22(木) 09:28:17.89 ID:eF3gH4iJ
論文の表1見たけど、学習可能パラメータ数大幅に削減できてるな
SD1.5で361Mから30Mに、SDXLで1251Mから108Mに減ってる
これは計算コスト的にもメモリ的にも大きいメリットやで
7 映像生成研究者 2024/08/22(木) 09:31:42.56 ID:kL5mN6oP
ビデオ生成にも応用できるのが面白いね
Stable Video Diffusionと組み合わせた結果が気になる
8 AIアーティスト 2024/08/22(木) 09:34:25.13 ID:qR7sT8uV
プラグアンドプレイ的に使えるのが魅力的やわ
既存のモデルやLoRAウェイトと組み合わせて、トレーニング無しで新しいスタイル作れるのええな
9 機械学習初心者B 2024/08/22(木) 09:37:10.47 ID:wX9yZ0aB
すごそうですね!でも「Cross Normalization」ってどういう仕組みなんですか?
10 数学者 2024/08/22(木) 09:40:33.82 ID:cD1eF2gH
>>9
簡単に言うと、2つの異なる特徴量の分布を揃える手法やな
メイン枝の平均と分散を使って制御枝の特徴を正規化するんや
これにより、新旧のパラメータがうまく協調できるようになる
11 性能評価専門家 2024/08/22(木) 09:43:56.29 ID:iJ3kL4mN
図3の収束性のグラフ見たけど、ControlNeXtの方が早く収束してるな
数百ステップで制御能力学習できてるのは印象的や
12 AIエシックス研究者 2024/08/22(木) 09:46:42.71 ID:oP5qR6sT
効率化は素晴らしいけど、生成AIの悪用リスクも考慮せなあかんで
論文最後にも触れられてるけど、人間の健康や幸福に害を与える可能性のあるものは生成せんようにしてるらしいわ
13 計算機アーキテクト 2024/08/22(木) 09:49:27.15 ID:uV7wX8yZ
推論時間も大幅に改善されてるな
表2見ると、ControlNetと比べてSD1.5で22.6%、SDXLで18.8%、SVDで25.4%も速くなってる
これは実用面でかなりのアドバンテージやで
14 AIトレンドウォッチャー 2024/08/22(木) 09:52:13.58 ID:aB9cD0eF
こういう効率化技術は今後どんどん重要になってくるやろなぁ
計算資源の制約がある中で、より高度な制御を実現していく流れは加速しそうや
15 画像処理エキスパート 2024/08/22(木) 09:55:40.23 ID:gH1iJ2kL
図5-7の生成例を見ると、マスク、深度、エッジ、ポーズなど多様な制御に対応できてるのが分かるな
汎用性高いわ
16 機械学習フレームワーク開発者 2024/08/22(木) 09:58:26.87 ID:mN3oP4qR
実装の観点から見ても、既存のフレームワークに組み込みやすそうやな
アーキテクチャの一貫性を保ってるのがええわ
17 名無しさん@お腹いっぱい。 2024/08/22(木) 10:01:15.42 ID:sT5uV6wX
なるほど、みんなの意見聞いてるとControlNeXtすごそうやな
効率的で汎用性高くて、既存技術との親和性も高いと
人工知能の発展ってほんま凄いわ
18 深層学習理論家 2024/08/22(木) 10:04:32.19 ID:yZ7aB8cD
理論的な観点から見ると、このControlNeXtのアプローチは非常に興味深いね
特に、大規模事前学習モデルの一部のみを微調整する手法は、過学習や破滅的忘却の問題に対する良い解決策になりそうだ
19 GPU最適化エンジニア 2024/08/22(木) 10:07:48.56 ID:eF9gH0iJ
メモリ効率が大幅に改善されてるのは、GPU利用の観点からも素晴らしいわ
高解像度や長尺の動画生成時にボトルネックになりがちやったからな
20 名無しさん@お腹いっぱい。 2024/08/22(木) 10:10:23.81 ID:kL1mN2oP
ほえー、みんな詳しいなぁ
ワイにも使えるんかな?
21 AIデモクリエイター 2024/08/22(木) 10:13:15.47 ID:qR3sT4uV
>>20
プラグアンドプレイで使えるって書いてあるし、技術に詳しくなくても使えそうやで
既存のStable Diffusionとか使ったことあるなら、それの拡張って感じやね
22 オープンソースコミュニティリーダー 2024/08/22(木) 10:16:42.35 ID:wX5yZ6aB
これ、オープンソース化されたら面白いことになりそうやな
コミュニティベースでさらなる改良や応用が進みそう
23 AIスタートアップCEO 2024/08/22(木) 10:19:27.92 ID:cD7eF8gH
ビジネス的な観点から見ても、この技術は大きな可能性を秘めてるわ
効率化によるコスト削減と、高品質な制御付き生成の両立は魅力的やで
24 法律専門家 2024/08/22(木) 10:22:15.68 ID:iJ9kL0mN
生成AI技術の進化に伴って、著作権や肖像権の問題も複雑化してくるやろなぁ
より精密な制御が可能になると、既存の作品や人物に酷似したものを生成できてしまう可能性もある
25 AI教育者 2024/08/22(木) 10:25:43.21 ID:oP1qR2sT
この技術、教育現場でも活用できそうやな
学生がAIモデルの仕組みを理解する上で、シンプルで効率的なアーキテクチャは良い教材になりそう
26 クリエイティブディレクター 2024/08/22(木) 10:28:36.79 ID:uV3wX4yZ
デザインやアート制作の現場でも、このControlNeXtは重宝されそうやわ
細かい制御ができるってことは、クリエイターの意図をより正確に反映できるってことやからな
27 名無しさん@お腹いっぱい。 2024/08/22(木) 10:31:22.45 ID:aB5cD6eF
なんか色んな分野に影響ありそうやな
AIってほんまに世の中変えてっとるわ
MixTex: 明確な認識は実際のデータだけに頼るべきではない
SOTA:https://paperswithcode.com/paper/unambiguous-recognition-should-not-rely
1 名前:風吹けば名無し[] 投稿日:2024/07/10(水) 08:23:45.67 ID:nanj1234
MixTexってなんや?誰か簡単に説明してクレメンス
2 名前:風吹けば名無し[sage] 投稿日:2024/07/10(水) 08:25:12.34 ID:ocr5678
MixTexは多言語対応のLaTeX OCRシステムやで
疑似データと本物のデータを混ぜて学習させてるんや
3 名前:LaTeX博士[] 投稿日:2024/07/10(水) 08:27:30.21 ID:tex9876
面白い approach やな。普通の OCR と違って数式や表も認識できるのがミソやで
4 名前:AI研究者[] 投稿日:2024/07/10(水) 08:30:45.98 ID:ai4321
Swin Transformer と RoBERTa の組み合わせが効いとるんやろな
エンコーダとデコーダのバランス取れとるし
5 名前:風吹けば名無し[] 投稿日:2024/07/10(水) 08:32:11.11 ID:nanj5555
>>1
ワイにも分かるように説明してクレメンス
6 名前:機械学習エンジニア[] 投稿日:2024/07/10(水) 08:35:23.45 ID:ml7890
>>5
簡単に言うと、数式や表が入った文書の画像から自動でLaTeXコードを生成するシステムや
しかも7ヶ国語に対応しとるんや
7 名前:統計学者[] 投稿日:2024/07/10(水) 08:38:56.78 ID:stats1111
データセットの作り方が斬新やな
本物と偽物を混ぜるのはバイアス軽減に効果ありそう
8 名前:コンピュータビジョン専門家[] 投稿日:2024/07/10(水) 08:41:32.10 ID:cv2222
手書き文字への対応もええな
データ拡張の手法もうまいこと使とる
9 名前:自然言語処理研究者[] 投稿日:2024/07/10(水) 08:44:17.89 ID:nlp3333
RoBERTaのデコーダを小さくしとるのが興味深いわ
文脈に頼りすぎんようにしとるんやろな
10 名前:風吹けば名無し[] 投稿日:2024/07/10(水) 08:46:28.76 ID:nanj6666
ほえー、すごそうやな
ワイにはさっぱりやけど
11 名前:数学教師[] 投稿日:2024/07/10(水) 08:49:55.43 ID:math4444
これ、生徒のノート読み取るのに使えそうやな
スペルミスも検出できるっちゅうのがええわ
12 名前:ソフトウェアエンジニア[] 投稿日:2024/07/10(水) 08:52:41.21 ID:se5555
実装の詳細が気になるわ
学習時のハイパーパラメータとか公開してくれへんかな
13 名前:言語学者[] 投稿日:2024/07/10(水) 08:55:37.65 ID:ling6666
7言語対応っちゅうのがすごいな
特に日本語や中国語みたいな非ラテン文字系もいけるんか?
14 名前:OCR研究者[] 投稿日:2024/07/10(水) 08:58:22.98 ID:ocr7777
従来のOCRと比べて、数式や表の認識精度どうなんやろ
ベンチマーク結果が気になるわ
15 名前:風吹けば名無し[] 投稿日:2024/07/10(水) 09:01:14.32 ID:nanj8888
なるほど、よう分からんけどすごいんやな
ワイらにも関係あるんか?
16 名前:教育工学研究者[] 投稿日:2024/07/10(水) 09:04:03.76 ID:edu9999
>>15
これが普及したら、手書きのレポートや試験答案の採点が楽になるかもしれんで
学生にとっても、自分の書いた数式をデジタル化しやすくなるやろ
17 名前:LaTeX開発者[] 投稿日:2024/07/10(水) 09:07:25.54 ID:latex1010
LaTeXユーザーにとっては朗報やな
手書きの数式をさっとLaTeXに変換できるのは便利やで
18 名前:風吹けば名無し[] 投稿日:2024/07/10(水) 09:10:18.90 ID:nanj1111
ふむふむ、なんかすごそうやな
ワイも勉強頑張ろうかな
BMX: エントロピー重み付け類似度と意味強化語彙検索
SOTA:https://paperswithcode.com/paper/bmx-entropy-weighted-similarity-and-semantic
1 名前:風吹けば名無し[] 投稿日:2024/08/22(木) 09:23:45.67 ID:aBc123De0
BMXとかいう新しい検索アルゴリズムが出たらしいで
論文: https://arxiv.org/abs/2408.06643
2 名前:情報検索研究者 ◆eXpErT1234[] 投稿日:2024/08/22(木) 09:25:12.34 ID:fGh456Ij7
ほう、面白そうやな。BM25の拡張版か。エントロピー重み付き類似度とか使っとるんか。
3 名前:機械学習エンジニア[] 投稿日:2024/08/22(木) 09:27:56.78 ID:kLm789No9
へぇ、クエリ拡張も入れてるんか。LLM使ってるのが現代的やな。
4 名前:データサイエンティスト[] 投稿日:2024/08/22(木) 09:30:23.45 ID:pQr012St3
BEIRベンチマークの結果見たけど、従来のBM25より全体的に良さそうやな。
5 名前:自然言語処理研究者[] 投稿日:2024/08/22(木) 09:33:45.67 ID:uVw345Xy6
長文検索のLoCoベンチマークでも良い成績出してるのが印象的やわ。
6 名前:検索エンジン開発者[] 投稿日:2024/08/22(木) 09:36:12.34 ID:zAb678Cd9
実装がBaguetterってライブラリで公開されてるんか。試してみるか。
7 名前:初学者A[] 投稿日:2024/08/22(木) 09:38:56.78 ID:eFg901Hi2
ちょっと待って、BMXってなんや?BM25との違いがよくわからんのやけど
8 名前:情報検索研究者 ◆eXpErT1234[] 投稿日:2024/08/22(木) 09:41:23.45 ID:fGh456Ij7
>>7
簡単に言うと、BM25の改良版やな。クエリと文書の類似度を考慮したり、意味的な拡張を入れたりしてる。
9 名前:AI研究者[] 投稿日:2024/08/22(木) 09:44:45.67 ID:jKl234Mn5
多言語での性能も報告されてるな。日本語でも使えそうか?
10 名前:ウェブ開発者[] 投稿日:2024/08/22(木) 09:47:12.34 ID:oPq567Rs8
実装の効率性も気になるな。Figure 1見る限り、BMXはBM25とそんなに変わらんみたいやけど。
11 名前:初学者B[] 投稿日:2024/08/22(木) 09:49:56.78 ID:tUv890Wx1
エントロピー重み付き類似度ってなんや?むずかしそう...
12 名前:統計学者[] 投稿日:2024/08/22(木) 09:52:23.45 ID:yZa123Bc4
>>11
簡単に言えば、クエリの各単語の情報量を考慮して重要度を決めてるんや。珍しい単語ほど重要視されるイメージや。
13 名前:検索アルゴリズム専門家[] 投稿日:2024/08/22(木) 09:55:45.67 ID:dEf456Gh7
正規化されたスコアを提案してるのも興味深いな。閾値設定が楽になりそうや。
14 名前:情報理論研究者[] 投稿日:2024/08/22(木) 09:58:12.34 ID:iJk789Lm0
エントロピーの使い方がエレガントやな。情報理論の応用として面白い。
15 名前:検索エンジン最適化専門家[] 投稿日:2024/08/22(木) 10:00:56.78 ID:nOp012Qr3
BRIGHTベンチマークでの結果が特に印象的やわ。現実的なシナリオでも強そうやな。
16 名前:計算言語学者[] 投稿日:2024/08/22(木) 10:03:23.45 ID:sTu345Vw6
重み付きクエリ拡張の部分、言語モデルの力をうまく使ってるな。これ、検索の未来を示唆してそうやで。
17 名前:風吹けば名無し[] 投稿日:2024/08/22(木) 10:06:45.67 ID:xYz678Ab9
みんな詳しすぎやろ...でもなんかワクワクするな
18 名前:データベース専門家[] 投稿日:2024/08/22(木) 10:09:12.34 ID:cDe901Fg2
インデックス構造はどうなってるんやろ。従来のインバーテッドインデックスと互換性あるんかな?
19 名前:並列計算研究者[] 投稿日:2024/08/22(木) 10:11:56.78 ID:hIj234Kl5
実装見たけど、並列化の余地ありそうやな。GPUで爆速にできそう。
20 名前:情報検索研究者 ◆eXpErT1234[] 投稿日:2024/08/22(木) 10:14:23.45 ID:fGh456Ij7
>>18
論文読む限り、基本的な構造はBM25と同じみたいやで。互換性はありそう。
21 名前:機械学習エンジニア[] 投稿日:2024/08/22(木) 10:17:45.67 ID:kLm789No9
>>19
GPUか...そうなると大規模データセットでの性能も気になるな
22 名前:初学者A[] 投稿日:2024/08/22(木) 10:20:12.34 ID:eFg901Hi2
みんな凄いな...でもこれ実際どんな場面で使えるんや?
23 名前:検索エンジン開発者[] 投稿日:2024/08/22(木) 10:22:56.78 ID:zAb678Cd9
>>22
ウェブ検索、社内文書検索、eコマースのサイト内検索...応用先は山ほどあるで
24 名前:自然言語処理研究者[] 投稿日:2024/08/22(木) 10:25:23.45 ID:uVw345Xy6
今後の課題は何やろな。さらなる改良の余地はありそうか?
25 名前:AI研究者[] 投稿日:2024/08/22(木) 10:28:45.67 ID:jKl234Mn5
言語モデルとの統合をもっと深めるのが一つの方向性かもな。検索と生成を融合させるみたいな
26 名前:統計学者[] 投稿日:2024/08/22(木) 10:31:12.34 ID:yZa123Bc4
パラメータ調整の自動化も面白そうやな。データセットに応じて最適なα、βを選ぶみたいな
27 名前:情報理論研究者[] 投稿日:2024/08/22(木) 10:33:56.78 ID:iJk789Lm0
エントロピーの計算方法をもっと洗練させる余地もありそうや
28 名前:初学者B[] 投稿日:2024/08/22(木) 10:36:23.45 ID:tUv890Wx1
なんかみんな熱くなってきてない?検索って地味やと思ってたけど奥深いんやな...
29 名前:風吹けば名無し[] 投稿日:2024/08/22(木) 10:39:45.67 ID:mNp012Op3
ワイも勉強始めてみようかな。どこから手をつければええんや?
30 名前:情報検索研究者 ◆eXpErT1234[] 投稿日:2024/08/22(木) 10:42:12.34 ID:fGh456Ij7
>>29
まずはBM25の基本を押さえるのがええで。それからこのBMXの論文読むのもおすすめや。実装もGitHubにあるし、触ってみるのが一番やで。
この記事が気に入ったらサポートをしてみませんか?