
ロックダウンした国を含む上位20カ国+日本の感染者数の推移をPythonで可視化してみた。※チュートリアル付き

こんにちはまにゃpyです。
3月ごろからヨーロッパやアメリカなどを中心に政府強制介入のロックダウンが行われていましたね。
「そういえば、各国のロックダウンの影響はどうなっているだろうか?」
今回作ったのは感染者数が多い上位20カ国のグラフです。Python初学者向けにチュートリアル型式にまとめました。
具体的に作ったのは下記3つ
・20カ国をひとまとめにしたグラフ
・20カ国それぞれの国の日ごとの感染者数の棒グラフ
・20カ国それぞれの国の累積の感染者数のグラフ
元となるデータは厚生労働省のホームページを使いました。
ちなみにデータ取得、整形、グラフ描画まで、使った言語はPythonのみです。
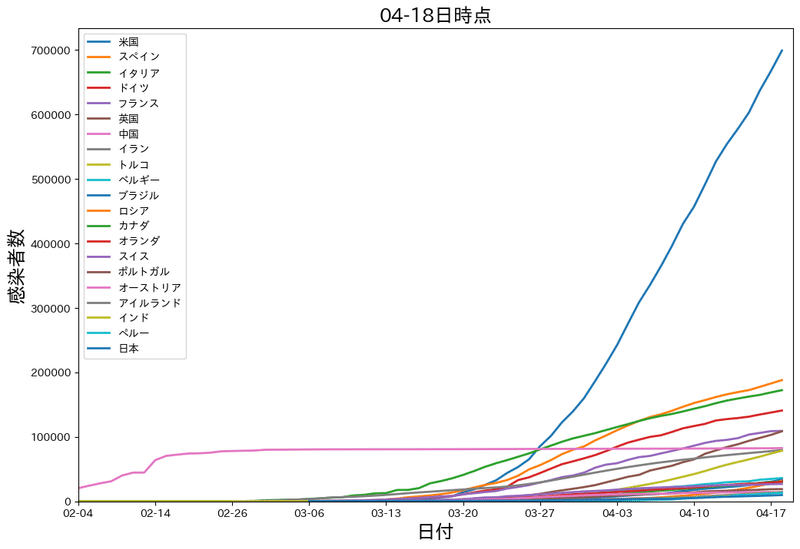
こちらは20カ国の感染者数の伸びをひとまとめにしたグラフです。
各国の感染者数の比較ができます。
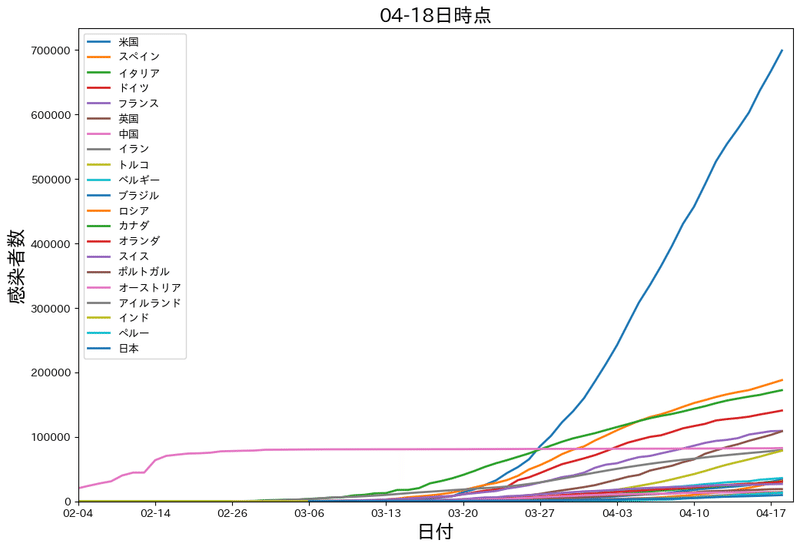
できたグラフを見ると
4月11日のデータでアメリカの感染者数の累計は50万人近くになってました。
それに続いてスペイン、イタリア、ドイツ、フランスとヨーロッパの国が並んでいます。
国ごとの日別推移のグラフ
次に各国の日別の感染者数のグラフをいくつか見ていきます。
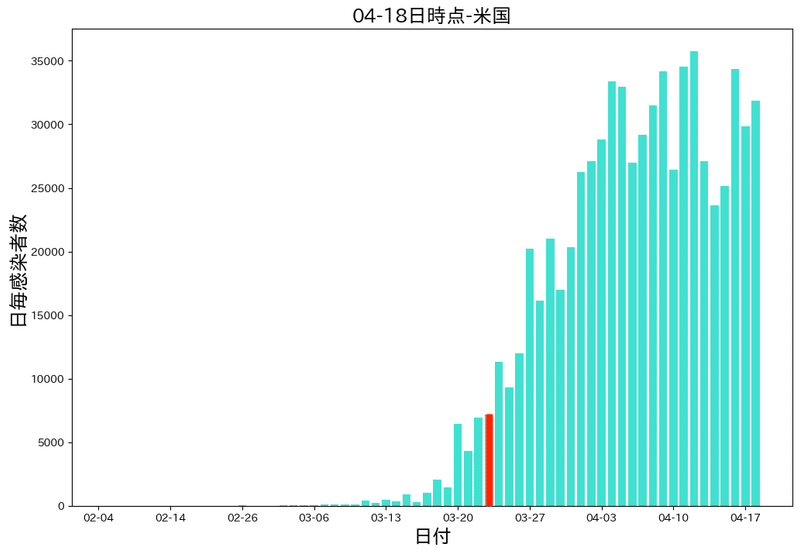
アメリカ(人口3.2億人)ニューヨークのロックダウン:3月23日から
アメリカは日ごとの感染者数が3万超えるなどほかの国と比較するとすごすぎますね。赤い部分がニューヨークがロックダウンされた日です。
ここまで感染者が増えると政府でも制御しきれないのかもしれません。
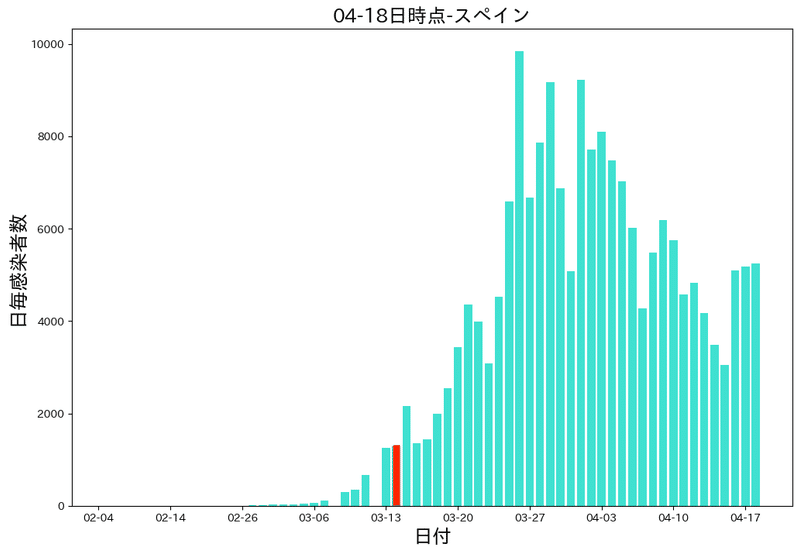
スペイン(人口4700万人)ロックダウン:3月14日から
下はスペインの日別の感染者数のグラフです。赤い部分がロックダウンの日です。
ロックダウンの日付の3月14日以降から感染者は伸びていますが、3月終わりぐらいから感染者が減ってきていますね。
その他の国の分もグラフを作成したのですが、ここではスペースの都合上割愛します。
今回のグラフの具体的なプログラミング部分の解説
さて、今回のグラフはプログラミング言語のPythonのみを使って表示しました。
はじめてJupyter notebookを使う方にも分かりやすいように、ここから、どんな風に書いていったのかを初学者向けにチュートリアル形式で説明していきます。
作るグラフをまず以下のように定めました。
・国別の感染者の累計グラフを表示したい
・上位20カ国の全体のグラフを表示したい
・日別の感染者のグラフを国別に表示したい(20カ国分)
肝心のデータ収集に関しては、
信憑性の高いデータが欲しい→公開データは使わないでできるだけゼロからプログラムを書きたい→厚生労働省からデータを取得
ということで、探してみたところ
厚生労働省のコロナ感染者の日時発表リンクがこちらにありました。↓
https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000121431_00086.html
上のページが日ごとの感染者数のリンクがまとまってていいですね。
まずリンク先のデータをざっと見る
ざっと見たところ、しっかりと表にデータがまとめられているのでデータ取得は簡単に終わりそう。↓

と思っていましたが、いくつか問題点を発見。
表のデータが統一されていなかったり、表がそもそもリンク先になく、テキストだけで書いてあったり。
数字に〇〇名など、余計な漢字がついていたり、中国だけ※がついてたり。↓
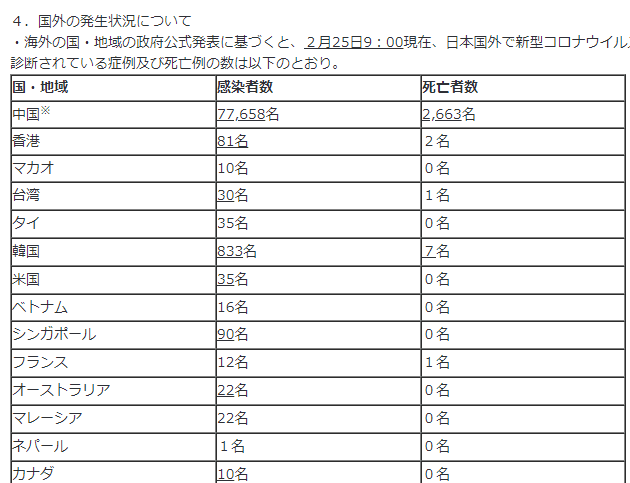
このように、リンク先ごとに表の形式が少しだけバラバラになっており、それを統一する必要がありました。
こういう形でデータ取得の際に型式がバラバラだったり揃っていないことはよくあります。
そのような場合でも一つ一つ場合分けしていけばデータを取り出すことができます。
その他いくつか問題があったのですが、以下のようにそれぞれの問題点を列挙して解決策を一つ一つ考えました。
問題点:表に日付が入っていないので、日付を表に付け足したい
解決策→テキストから日付を拾ってくればOK
問題点:一部に表がないページもある→感染者数、死亡者数などがテキストで書いてある。
解決策→表がないページはテキストからデータを拾ってくればOK
問題点:国数が多すぎるので一つのグラフで表示できない
解決策→感染者数上位20カ国に絞る
問題点:表が国別に分かれてなく、全ての国のデータが一つの表に
まとまっている
解決策→データを元に新たに表を作り直す
このようにまず、それぞれの問題に対して解決できる見通しを立てました。
実際に行なったプログラミングの流れ
以上をふまえたプログラミングする際のざっくりとした流れをまず書き出しておきます。
厚生労働省のURL先のデータ(テーブルデータ、日付)を一つ一つ取得
↓(ここからテーブルデータのあるなしで場合分け)
・テーブルデータがある場合
データの統一、テーブルを再編して国別のテーブルを作る
↓
グラフとして表示
・テーブルデータがない場合
テキストデータから国名、感染者数、死亡者数の取得
↓
テーブルデータにする
↓
グラフとして表示
ざっくりこんな流れでコーディングしていくことに決定しました。
このチュートリアルを読むと得られるもの
この記事を読むと初学者の方が得られるものをざっと紹介します。
urllib.requestモジュールによるスクレイピング
reモジュールによる正規表現の扱い
pandasによる表の扱い
matplotlibによるグラフの表示(棒グラフ、折れ線グラフ)
これらの知識を総動員してグラフを作っていきます。
前提知識
※ProgateでPythonのコースを全て受講していて、pandasやmatplotlibの知識が事前にあったほうが読みやすいです。
Pythonの実行はJupyter Notebookを使っていきます。
今回のプログラムではグラフ描画もあるので、Jupyter Notebookで行うことをおすすめします。

Jupyter notebookはブラウザで使える対話型のWebアプリケーションです。
Pythonでデータ分析やグラフ描画する際によく使われています。
コードを書いて実行ボタン(Run)を押すだけですぐに結果を見ることができるので本当に便利。グラフもコードのすぐ下に表示されます。

しかも上のセルで実行された状態はそのまま保持されるので、下のセルにどんどんコードを追加、実行していって部分的にコードを実行していくことができます。
上のセルでimportしたライブラリは改めてimportする必要はありません。

Jupyter Notebookのインストール
Jupyter NotebookはAnacondaというソフトをインストールするとデータサイエンスを行う環境ごとまるっと用意されるので便利です。
インストール方法は上のリンクから右上のダウンロードのボタンを押してAnacondaをダウンロード、インストールした後に、
ターミナルを開いて
$jupyter notebookと打ち込んでエンターするだけでブラウザでJupyter Notebookが立ち上がります。(Windowsの場合は$を無視して下さい。)
開いた直後はファイルリストのような画面が表示されるので、右上のボタンの「New」をクリックして、「Python3」を選択すれば対話型画面が開けます。
ここからチュートリアル
では、実行環境が整ったのでここからプログラムを解説していきます。
完成したコードは記事の一番最後に記載してあります。
まずは必要なライブラリのインポートです。
ライブラリがないとエラーが出てしまった場合は
pip install で都度インストールしてあげて下さい。
from urllib import request
from urllib.request import urlopen
import urllib.parse
from bs4 import BeautifulSoup
import re
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import datetime as dt
import numpy as np
from tqdm.notebook import tqdm
get_ipython().run_line_magic('matplotlib', 'inline')ここから処理を簡潔にするために関数をいくつか作っていきます。
次はページのソースの取得です。
BeautifulSoupを用いてurlからsoupを取得してパースします。
パースとはプログラムのソースコードやXMLなどの複雑な構造のテキストを解析して、プログラム(Python)の中で扱いやすいデータ構造の集合体に変換するという意味になります。
# 1ページ分の内容取得
def get_page_data(url):
# get html
html = request.urlopen(url)
# set BueatifulSoup
soup = BeautifulSoup(html, "html.parser")
return soupこの一連の操作を get_page_data()関数として定義します。
soupはurlのソースコードそのものみたいなイメージです。
soupを表示させてみるとこんな感じになっています。

ただ、このままではPythonで扱いにくいので、"html.parser"の部分でパースしてPythonで扱いやすいデータ構造に変換しています。
補足説明
ここで、Pythonでよく扱うデータフレームというデータ型について説明しておきます。
Pythonでは表形式のデータ型のことをDataFrame(データフレーム)と言う名称で呼びます。
1行や1列の場合はSeries(シリーズ)と言います。このDataFrameやSeriesを扱えるのがpandasというライブラリです。
DataFrameの行の見出し(行ラベル)をindex(インデックス)、列の見出し(列ラベル)をcolumns(カラム)と言います。
テーブルデータのある、なしで場合分け
次はテーブルデータがurl先にあるかどうかで場合分けしていきます。
テーブルデータが存在する場合は
日付をテーブルに追加+〇〇名の部分の「名」をなくすなどしてテーブルを統一していきます。
## テーブルデータがある場合
# 取得対象のテーブルか判定
def get_table_data(url,day):
for table_data in pd.read_html(url,header=0):
if '国・地域' in table_data.columns:
table_data.columns = ['国・地域','感染者','死亡者']
table_data.loc[:,'国・地域']=table_data['国・地域'].str.replace('※','')
table_data.loc[:,'日付'] = day
table_data = table_data[['日付','国・地域','感染者','死亡者']]
try:
table_data.loc[:,'感染者'] = table_data['感染者'].str.replace('名','')
table_data.loc[:,'死亡者'] = table_data['死亡者'].str.replace('名','')
table_data.loc[:,'感染者'] = table_data['感染者'].str.replace(',','')
table_data.loc[:,'死亡者'] = table_data['死亡者'].str.replace(',','')
table_data.loc[:,'感染者'] = table_data['感染者'].astype(int)
table_data.loc[:,'死亡者'] = table_data['死亡者'].astype(int)
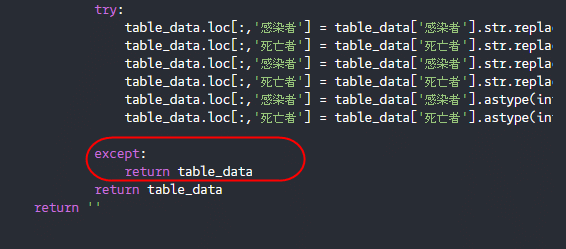
except:
return table_data
return table_data
return ''一連の操作をget_table_data()関数として定義しています。
一つ一つの行をもう少し細かく解説していきます。
for table_data in pd.read_html(url,header=0):上記の部分ですが、pandasでは、pd.read_html(url)と記述するだけでurl中のテーブルデータを取得できます。とても便利ですね。
url中にtableタグがあればそのテーブルを全て取得します。
header=0は1行目が見出し(header)で有ることを指定しています。
ただ、urlの中にテーブルデータが複数ある場合があるので、pd.read_html(url)で得られるデータはリスト形式になります。
そのリストに入っているテーブルデータを使ってfor文を回していきます。
for table_data in pd.read_html(url,header=0):
if '国・地域' in table_data.columns:上の部分では、取得したテーブルから列ラベル(columns)に「国・地域」という文字列が入っているものかどうかを判別しています。
つまり、こういうテーブルを取得していきます↓
この判別をしている理由は、urlの中には、下記のような表も出てきて、それらを除外したいからです。

次に条件に合ったテーブルデータに日付をつけていきます。
table_data.columns = ['国・地域','感染者','死亡者']
table_data.loc[:,'国・地域']=table_data['国・地域'].str.replace('※','')
table_data.loc[:,'日付'] = day
table_data = table_data[['日付','国・地域','感染者','死亡者']]ここではpandasの.locを使ってテーブルの一部だけを取り出すスライスという操作を使っています。
.loc[1]で1行目を取り出す。.loc[2:5]で2行目から5行目を取り出す。
.loc[:,5]で5列目を取り出す。などの操作ができます。
.loc[:,'国・地域']上記で'国・地域'の列だけを取り出すことができます。
国・地域の列には※がついているデータがあり、※はいらないので
.str.replace('※','')で置換して消します。
.str.replace('A','B')はAをBに置換するという意味です。
table_data.loc[:,'日付'] = day日付の列を作り、日付データを代入しています。
table_data = table_data[['日付','国・地域','感染者','死亡者']] 次に[’日付']の列と['国・地域','感染者','死亡者']
を合体させたテーブルを作っています。
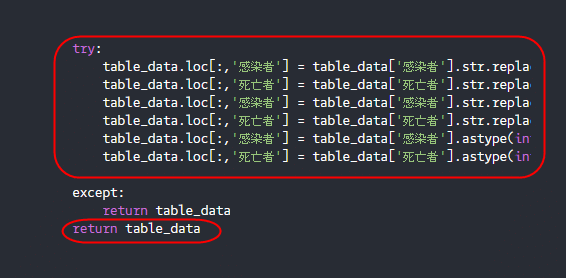
try-except文
try:
table_data.loc[:,'感染者'] = table_data['感染者'].str.replace('名','')
table_data.loc[:,'死亡者'] = table_data['死亡者'].str.replace('名','')
table_data.loc[:,'感染者'] = table_data['感染者'].str.replace(',','')
table_data.loc[:,'死亡者'] = table_data['死亡者'].str.replace(',','')
table_data.loc[:,'感染者'] = table_data['感染者'].astype(int)
table_data.loc[:,'死亡者'] = table_data['死亡者'].astype(int)
except:
return table_data
return table_dataここでは”名”や数字のコンマなどの文字列を削除してデータの表示形式を統一していっています。
あと、.astype(int)で、感染者数と死亡者数をint型(整数)に変換しています。
try-except文の部分では、
tryでテーブルのデータの表記を統一→整形したテーブルデータを渡す
例外があればテーブルデータをそのまま渡すという形になっています。
ここまでの流れをget_table_data()という関数を定義してひとまとめにしています。
テーブルデータがない場合
## テーブルデータがない場合
def get_not_table_data(soup,day):
row_data_list = []
for i in range(len(soup.find_all(name='p'))):
append_data = re.findall(r'・\D*感染者.\d*名.*死亡者\d*名',soup.find_all(name='p')[i].get_text().replace(',',''))
if len(append_data)!=0:
row_data = append_data
for i in row_data:
country = re.search(r'・(.*):',i).group(1)
infected = re.search(r'感染者\D?(\d*)名',i).group(1)
deaths = re.search(r'死亡者\D?(\d+)名',i).group(1)
row_data_list.append([day,country,int(infected),int(deaths)])
return row_data_listテーブルデータがない場合はテキストからデータを取得していきます。
具体的には下記のようになっているところから欲しい情報を取っていきます。

まず soup.find_all(name='p') でsoupの中からpタグのある段落を全て探して集めます。find_allのデータ形式はリストになります。
具体的には下記のような形でpタグで囲まれた段落だけを集めたリストを作っています。

その作ったリストの要素数をlen()で取得し、その要素数でfor文を回していきます。
append_data = re.findall(r'・\D*感染者.\d*名.*死亡者\d*名',soup.find_all(name='p')[i].get_text().replace(',',''))ここでは re.findall(パターン,テキスト)を使っています。
参考:正規表現とreモジュールについて→https://hashikake.com/RegEx
この操作でテキストの中からパターンに当てはまるすべての部分文字列をリストにして返してくれます。
具体的にpタグで囲まれた段落 soup.find_all(name='p')[i] の中から.get_text()でテキストだけを抜き出して、正規表現パターンである
・\D*感染者.\d*名.*死亡者\d*名 に当てはまる部分をre.findall()を使って全て探して、リスト形式で返してappend_dataに代入しています。
append_dataの中身はこのような形になります。

if len(append_data)!=0:
row_data = append_dataさらに、append_dataが0じゃない場合、つまり
・タイ:感染者19名、死亡者0名。
↑こういう形のものが存在する場合は append_dataをrow_dataとします。
for i in row_data:
country = re.search(r'・(.*):',i).group(1)
infected = re.search(r'感染者\D?(\d*)名',i).group(1)
deaths = re.search(r'死亡者\D?(\d+)名',i).group(1)
row_data_list.append([day,country,int(infected),int(deaths)])先ほど取得したrow_dataは下のような形のリストなんですが、そこからfor文で一行一行取り出して、国名と感染者数と死亡者数のパターンを正規表現で探して取得しています。
.group(1)となっているものは正規表現のグルーピングと言われるもので
re.search(r'感染者\D?(\d*)名',i)の中の括弧で囲まれている部分。つまり今回だと \d* だけを取り出すことが可能です。
グルーピングに関しては下でも詳しく解説しています。
参考:Pythonの正規表現ではじめに覚えるべき3大パターン
row_data_list.append([day,country,int(infected),int(deaths)])その次のこちらですが、先ほど取得した国名、感染者数、死亡者数と日付のデータ(day)をリスト形式でまとめてrow_data_listの空のリストに入れていっています。
そして、ここまでの流れでget_not_table_data()という関数で一つにまとめています。
plot用のテーブルデータ作成のための関数
## plotデータ作成
def make_plot_data(data_list):
plt_data = pd.DataFrame(["","","",""]).T
plt_data.columns = ['日付','国・地域','感染者','死亡者']
for num,i in enumerate(data_list):
if len(i)>0:
plt_data=plt_data.append(i)
else:
print(num)
plt_data = plt_data.loc[~((plt_data['国・地域']=='その他')|(plt_data['国・地域']=='計'))]
plt_data = plt_data.iloc[1:].reset_index(drop=True)
return plt_dataここでは、全ての国のデータフレームを結合するmake_plot_data関数というものを定義しています。
plt_data = pd.DataFrame(["","","",""]).T上の部分で列数が4つの空のDataFrameを作ります。pd.DataFrame(["","","",""])で作ると4行、1列になるので、.Tで行、列の入れ替えをしています。

for num,i in enumerate(data_list):
if len(i)>0:
plt_data=plt_data.append(i)
else:
print(num)次はfor文を使って国ごとのデータフレームを結合していきます。
enumerate()関数でリストなどのイテラブルオブジェクトからindexと要素を同時に取り出してfor文を回すことができます。
・データフレームの行数が>0の場合
len(i)はデータフレームの行数となります。len(i)>0つまり、表がある場合
if len(i)>0:
plt_data=plt_data.append(i).append()を使って空のplt_dataに表をどんどん結合していきます。
・データフレームの行数が0の場合
データフレームの行数が0の場合はprint(num)でindexを返します。
ここまでは関数の定義でしたが、次からは実際のデータを抜き出す部分に行きます。
次の行では、結合してできた表からデータとして必要のない行を除外する作業です。
plt_data = plt_data.loc[~((plt_data['国・地域']=='その他')|(plt_data['国・地域']=='計'))]国・地域の列がその他になっている場合と、国・地域の列が計になっている部分以外を取り出しています。
URLからURLリストと日付リストを抜き出す
url = "https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000121431_00086.html"
# get html
html = request.urlopen(url)
# set BueatifulSoup
soup = BeautifulSoup(html, "html.parser")
# 取得対象URL/日付取得
links =[atag.get('href') for atag in soup.find_all(name=lambda x: x.name=="a" and "新型コロナウイルス感染症の" in x.text and "状況" in x.text)]
days = [atag.get_text() for atag in soup.find_all(name=lambda x: x.name=="a" and "新型コロナウイルス感染症の" in x.text and "状況" in x.text)]
days = [[((re.search(r'\d+月',i)).group()).replace('月',''),((re.search(r'\d+日',i)).group()).replace('日','')] for i in titles]
days = [dt.date(dt.datetime.today().year,int(i[0]),int(i[1])) for i in days]ここは厚生労働省のページからurlと日付のリストを作っている部分です。
url = "https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000121431_00086.html"
# get html
html = request.urlopen(url)
# set BueatifulSoup
soup = BeautifulSoup(html, "html.parser")ここまででurlの
https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000121431_00086.html
からBeautifulSoupを用いてurlからsoupを取得してパースします。
soupはソースコードのようなイメージです。
次にこちらの行です。
links =[atag.get('href') for atag in soup.find_all(name=lambda x: x.name=="a" and "新型コロナウイルス感染症の" in x.text and "状況" in x.text)]
まず下記のリスト内包表記を使っています。まずここでは下記のようにリストの内包表記を使っています。
[式 for 変数 in リストなどのイテラブルオブジェクト]リストの内包表記の中で、lambda式を使っているので解説していきます。
・lambda式について
ラムダ式は無名の関数を定義できる式で、
lambda 引数: 返り値のように書きます。
これは、通常の関数だと
def func(引数):
return 返り値と同じ意味です。ただ、こちらはfuncという名前の関数となるのに対して
lambda 引数: 返り値 の場合は無名の関数になります。
lamda式は下記のように書くこともできます。これはfuncという関数を定義しているのと同じです。
func = lamda 引数: 返り値soup.find_all(name = lambda x: x.name=='a')の部分は
xの中からaタグ要素を全部探してリスト形式で返してくれます。
更に、下記のようにするとaタグ要素の中でも"新型コロナウィルス感染症の"と"状況"という言葉が入ったものを全て探してリスト形式で返します。
soup.find_all(name=lambda x: x.name=="a" and "新型コロナウイルス感染症の" in x.text and "状況" in x.text)次にそのリストの中身をatagに一つ一つ代入して、atagからurlを取得してlinksというリストを作成しています。
links =[atag.get('href') for atag in soup.find_all(name=lambda x: x.name=="a" and "新型コロナウイルス感染症の" in x.text and "状況" in x.text)]同様に、次の行の
days = [atag.get_text() for atag in soup.find_all(name=lambda x: x.name=="a" and "新型コロナウイルス感染症の" in x.text and "状況" in x.text)]では、同条件でaタグをリストにして集めてそのaタグからテキスト部分のみを集めてdaysという名前のリストにしています。
print(days)して具体的に見ると下記のようにテキストのリストになっています。

次に下記の行ですが、daysのリストから◯月と□日という部分を探し出して月と日を削除して[3, 4]のようなリストを集めたリストをdaysとしています。
days = [[((re.search(r'\d+月',i)).group()).replace('月',''),((re.search(r'\d+日',i)).group()).replace('日','')] for i in days]つまり、月と日の数字だけを要素に持つリストのリストを作ったということですね。
print(days) して具体的に中身を見ると

のような形になっています。この時点では数字は文字列になっていますね。
・datetimeについて
datetimeはdtとしてimportしたのでした。(import datetime as dt)
dt.datetime.today() で出力が
datetime.datetime(2020, 4, 18, 19, 57, 40, 711594)
という風に現在の西暦、日付、時刻を取り出すことができます。
dt.datetime.today().year で 2020となり、現在の西暦を取り出せます。
下の行では、dt.datetime.today().yearで現在の西暦である2020を入れています。
days = [dt.date(dt.datetime.today().year,int(i[0]),int(i[1])) for i in days]下記の部分ですが、
dt.date(dt.datetime.today().year,int(i[0]),int(i[1]))一般的に
datetime.date(2020, 5, 6)で 2020-05-06
という日付型のオブジェクトを作成することができます。
下の部分でもdt.tateの要素として
dt.datetime.today().year と int(i[0])と int(i[1]) を並べているので
dt.date(dt.datetime.today().year,int(i[0]),int(i[1]))2020-05-06のような日付型のオブジェクトを返します。
つまり、daysは最終的に2020-03-26の形のような日付型オブジェクトを要素に持つリストとなります。
print(days) してdaysの中身を見ると次のようなリストになっています。

urlに表がある場合、ない場合に分けて日付を入れた表の作成
# データ取得
data_list = []
# for i,d in zip(tqdm_notebook(links,desc='進捗', leave=True),days):
for i,d in zip(tqdm(links,desc='進捗', leave=True),days):
data = get_table_data(i,d)
if len(data) == 0:
data = get_not_table_data(get_page_data(i),d)
data = pd.DataFrame(data)
data.columns = ['日付','国・地域','感染者','死亡者']
data_list.append(data)ここでは日付、国・地域、感染者、死亡者を列に持つ表をurlに表があるかないかで場合分けして作成していっています。
・tqdmで進捗状況のバーの表示
tqdmモジュールで進捗状況をステータスバーで表示することができます。
基本の使い方は次のような感じです。
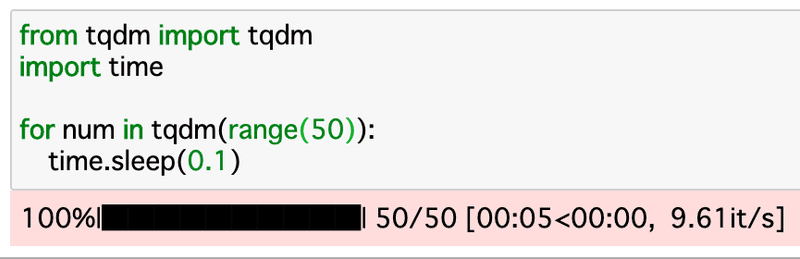
上記は0.1秒のスリープを50回繰り返すだけのプログラムです。
基本的には上記のように、tqdmはfor文のイテレータオブジェクト引数に取ります。
今回のはこちらです。こちらではtqdmはlinksを引数としています。
for i,d in zip(tqdm(links,desc='進捗', leave=True),days)オプションでdescとleaveを使っています。
desc='**' でプログレスバーの名前を表示
leave = True ここはプログレスバーが100%に達した時の挙動です。
Trueならそのまま。Falseならプログレスバーが削除されます。
・zip関数について
zip関数はfor文の中で複数のシーケンスオブジェクトを同時にループできます。
例えば下記だとrange(5)とlinksからそれぞれaとbに一つずつ値を取り出して
その和を表示しています。やっていることはシンプルですね。

つまり下だと
for i,d in zip(tqdm(links,desc='進捗', leave=True),days)linksとdaysから値を一つずつ取り出してiとdにそれぞれ入ってfor文以下の処理をしていきます。
for文以下の処理について見ていきます。
data = get_table_data(i,d)
if len(data) == 0:
data = get_not_table_data(get_page_data(i),d)
data = pd.DataFrame(data)
data.columns = ['日付','国・地域','感染者','死亡者']
data_list.append(data)・urlに表がある場合
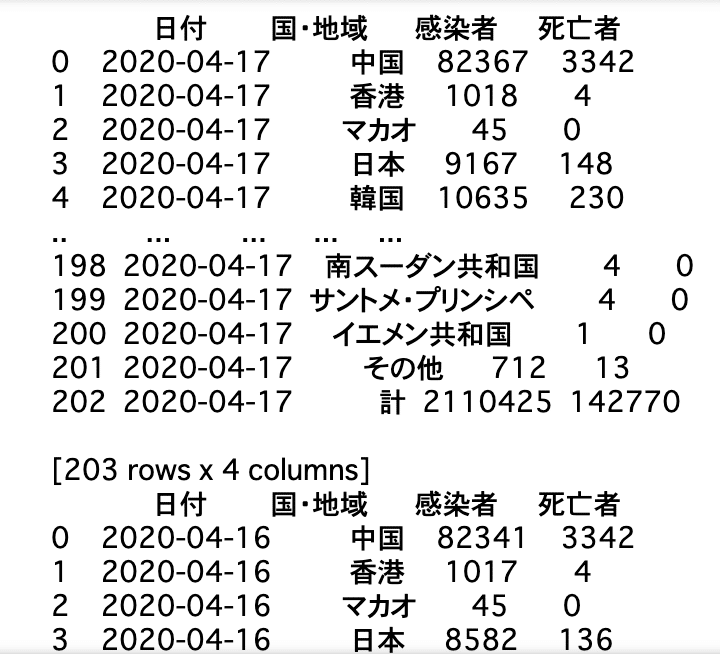
data = get_table_data(i,d)
こちらはurlの中に表がある場合の関数であるget_table_data関数を使っています。
'国・地域','感染者','死亡者'という列の表と、日付の列を組み合わせて新たに表を作っています。
print(data)で見てみると下記のような形の表を作っています。
・urlに表がない場合
if len(data) == 0:
data = get_not_table_data(get_page_data(i),d)
data = pd.DataFrame(data)
data.columns = ['日付','国・地域','感染者','死亡者']次に上記ですが、
len(data) == 0:
つまり、表の行数が0である、すなわちurlに表がない場合
get_not_table_data関数を使ってurlに表がない場合の処理をしていきます。
urlのテキスト本文中から日付、国・地域・感染者・死亡者のデータを取ってきて表を作っていきます。
data = get_not_table_data(get_page_data(i),d)ここでprint(data)を見てみると下記のようにリストの中に国ごとにリストが入っています。

これを下記で表にして、列名を付けます。
data = pd.DataFrame(data)
data.columns = ['日付','国・地域','感染者','死亡者']ここでもprint(data)で見てみると下のような表がちゃんと出来ていますね。

次に最後の行ですが、
data_list.append(data)data_listという空のリストに出来た表をどんどん入れていきます。
つまり、data_listは表が入ったリストになります。
感染者数上位20カ国+日本を抽出
次はグラフplot用のテーブルデータの作成と、
感染者数上位20カ国+日本を抽出していきます。
# plot用テーブルデータ作成
plt_data = make_plot_data(data_list)
# 上位20カ国+日本取得
top_20 = list(plt_data.query('日付==@plt_data.日付.max()').sort_values(by='感染者',ascending=False)['国・地域'].iloc[:20])
top_20.append('日本')まず、あらかじめ作ってあるmake_plot_data()関数を使ってdata_listのリストに入っている表を全て結合した表を作ります。
print(plt_data)してみると下のように8317行の結合された表が出来ています。

これで表の結合は終わりです。
次は感染者数上位20カ国の抽出です。
##上位20カ国+日本取得
top_20 = list(plt_data.query('日付==@plt_data.日付.max()').sort_values(by='感染者',ascending=False)['国・地域'].iloc[:20])まず下の部分についてですが
plt_data.query('日付==@plt_data.日付.max()')ここではpandasのquery()メソッドを使っています。
あるDataFrameのdfがあった時に
df.query('条件式')で条件に当てはまるDataFrameの一部を取り出せます。
今回の条件は
日付==@plt_data.日付.max()となっているので、plt_dataの日付が最大。
つまり一番最近の日付=今日の日付の部分を取り出すということです。
具体的にprintすると下の表を取り出します。
(これを書いている日が4月18日)

上を見ると感染者数順になっておらずindex順になっていることが分かります。
次にこれを感染者数順に並べ替えます。
.sort_values(by='感染者',ascending=False)使っていくのはpandasのsort_values()メソッドです。
こちらはby='感染者'となっているので、感染者の列の数字で並べ替えを行っています。
数が大きい方を上にしたい(降順にしたい)ので、 ascending=False としています。

感染者数順に並べ替えられました。
plt_data.query('日付==@plt_data.日付.max()').sort_values(by='感染者',ascending=False)['国・地域'].iloc[:20]次に上では['国・地域']列の上から20行までを取り出しています。
このような形になります。

あとは全体をlist()で囲んでtop_20という名前のリストにします。
['米国', 'スペイン', 'イタリア', 'ドイツ', 'フランス', '英国', '中国', 'イラン', 'トルコ', 'ベルギー', 'ブラジル', 'ロシア', 'カナダ', 'オランダ', 'スイス', 'ポルトガル', 'オーストリア', 'アイルランド', 'インド', 'ペルー']
top_20.append('日本')で日本をリストに付け加えます。
top_20 = ['米国', 'スペイン', 'イタリア', 'ドイツ', 'フランス', '英国', '中国', 'イラン', 'トルコ', 'ベルギー', 'ブラジル', 'ロシア', 'カナダ', 'オランダ', 'スイス', 'ポルトガル', 'オーストリア', 'アイルランド', 'インド', 'ペルー', '日本']
感染者数上位20カ国の棒グラフの描画
次はここまでのデータを使ってグラフを描画していきます。
まず感染者数が上位20カ国の棒グラフです。下がそのコードです。
# 各国棒グラフ出力
country_data = [0]*len(top_20)
today = max(days).strftime('%m-%d')
for i in range(len(top_20)):
country_data[i] =plt_data[plt_data['国・地域']==top_20[i]]
plt.style.use('default')
fig = plt.figure(figsize=(12.0, 8.0))
plt.rcParams['font.family'] = 'IPAexGothic'
ax = fig.add_subplot(111)
x = [i for i in range(0,country_data[i].shape[0])]
ax.bar([d.strftime('%m-%d') for d in country_data[i].日付.values[::-1]],country_data[i].感染者.values[::-1],color='mediumseagreen',linewidth=4)
ax.set_title('{}日時点-{}'.format(today,top_20[i]),fontsize=18)
plt.xticks([n for n in range(0,len(x),7)],[d.strftime('%m-%d') for d in country_data[i].日付.values[::-1][::7]])
plt.xlabel('日付',fontsize=18)
plt.ylabel('感染者数',fontsize=18)
plt.show()グラフを書くために準備したplt_dataはこちらでした。
ただ、このデータだと全部の国が混ざっているので、国ごとの棒グラフは書けないです。
ここから国ごとのデータを取り出した表を作り、それをリストに入れるとfor文などでグラフ描画しやすいので、その方向性でいきます。
country_data = [0]*len(top_20)まずtop_20の要素の数だけ0が並んだリストを作ります。
これは別に要素が0でないといけないということはありません。
aであっても大丈夫です。中身は何でもいいので、とりあえずtop_20の要素の数を持つリストを作りたいです。
country_data = ['0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0']
こうなります。この0を一つ一つ国ごとの表に変えていきます。
次に下の部分ですが、
for i in range(len(top_20)):
country_data[i] =plt_data[plt_data['国・地域']==top_20[i]]country_data[i] =plt_data[plt_data['国・地域']==top_20[i]]
の部分で、ptt_dataの中からplt_dataの'国・地域'の列がtop_20[i]に等しい
部分を取り出し、それをcountry_data[i]としています。
具体的には、top_20は下記のリストだったので、
['米国', 'スペイン', 'イタリア', 'ドイツ', 'フランス', '英国', '中国', 'イラン', 'トルコ', 'ベルギー', 'ブラジル', 'ロシア', 'カナダ', 'オランダ', 'スイス', 'ポルトガル', 'オーストリア', 'アイルランド', 'インド', 'ペルー', '日本']
例えば、i=0なら、plt_dataの中から
plt_dataの'国・地域'の列が米国に等しい部分を取り出してそれをcountry_data[0]に代入しています。
実際にcountry_data[0]を見てみるとこうなっています。
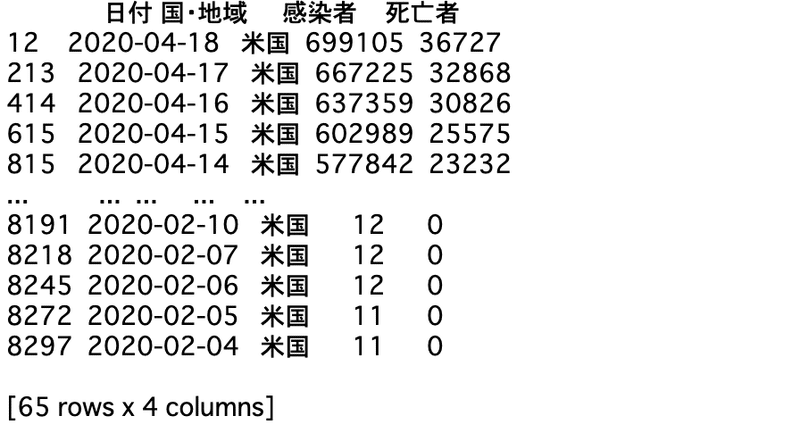
更に、country_dataも見てみるとindex=0だけアメリカの表に変わっていて、残りの要素は0です。

ひとまずこれでアメリカだけの表が手に入りました。これで棒グラフが書けます。
さて、次からは実際にcountry_data[0] すなわち
の棒グラフを書いていきましょう。
・データから棒グラフを書く
plt.style.use('default')
fig = plt.figure(figsize=(12.0, 8.0))
plt.rcParams['font.family'] = 'IPAexGothic'
ax = fig.add_subplot(111)
x = [i for i in range(0,country_data[i].shape[0])]
ax.bar([d.strftime('%m-%d') for d in country_data[i].日付.values[::-1]],country_data[i].感染者.values[::-1],color='mediumseagreen',linewidth=4)
ax.set_title('{}日時点-{}'.format(today,top_20[i]),fontsize=18)
plt.xticks([n for n in range(0,len(x),7)],[d.strftime('%m-%d') for d in country_data[i].日付.values[::-1][::7]])
plt.xlabel('日付',fontsize=18)
plt.ylabel('感染者数',fontsize=18)
plt.show()コードは上のようになります。
ちょっとごちゃごちゃしているので、ここから棒グラフを書くために最低限必要な部分だけを抜き出してみます。
fig = plt.figure(figsize=(12.0, 8.0))
ax = fig.add_subplot(111)
ax.bar([d.strftime('%m-%d') for d in country_data[i].日付.values[::-1]],country_data[i].感染者.values[::-1],color='mediumseagreen',linewidth=4)
plt.show()実は上記だけで棒グラフは書けます。具体的には下のようになります。
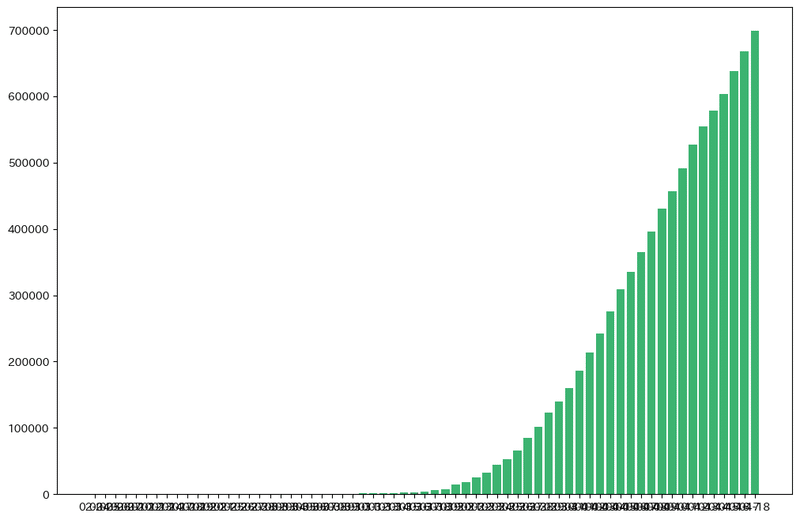
日付が重なってしまっていますが、感染者数の棒グラフが書けましたね。
グラフ描画の基本、figureとaxesについて
matplotlibではグラフを書く際に
FigureインスタンスとAxesオブジェクトを作成しそこにグラフを描画していきます。
それぞれの役割は
Figureインスタンスが描画領域の確保
Axesオブジェクトは目盛り、軸の描画の設定
となっています。図で説明します。
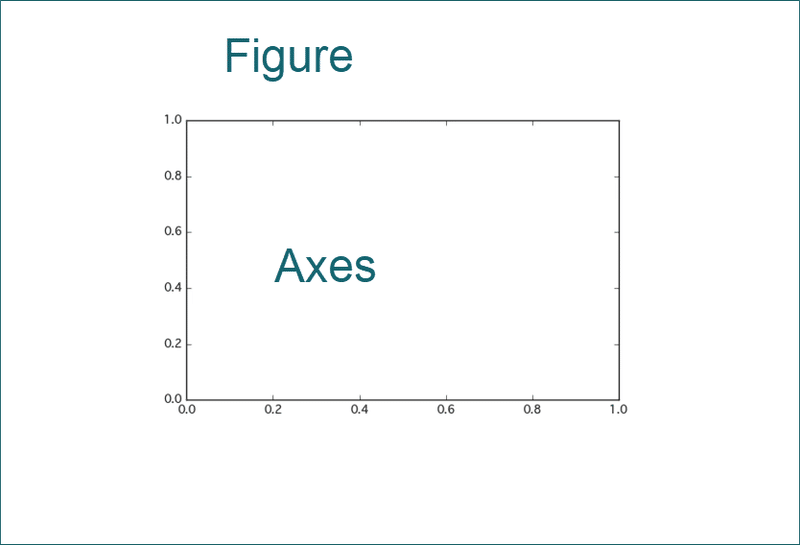
↑の図で言えば、Figureインスタンスが外枠の描画領域、
Axesオブジェクトが目盛りがある内枠の四角の部分です。
具体的には、
plt.figure()でFigureインスタンスを作成して、
fig.add_subplot()でFigureインスタンスの中に、Axesオブジェクトを作成します。
今回のコードで解説していきます。
fig = plt.figure(figsize=(12.0, 8.0))figsize=(12.0, 8.0)でFigureインスタンスのサイズの設定をしています。
また、
ax = fig.add_subplot(111)の部分ですが、これは111の部分でFigureインスタンスで確保された描画領域のどの位置にAxesオブジェクトを配置するかを決めることができます。
.add_subplot(何行,何列,何番目)
という意味になります。前半の何行、何列という部分で描画領域を行列に分割します。
fig.add_subplot(111) だと、1行の1列に描画領域を分割した1番目に配置します。
つまり描画領域の中央に配置することになります。イメージとしては下記です。
例えば、fig.add_subplot(221)だと
だと2行目の2列に描画領域を分割した1番目に配置します。
例えば、次のようにAxesオブジェクトを3つ作ると、
fig.add_subplot(221) # 2行、2列の1番目
fig.add_subplot(222) # 2行、2列の2番目
fig.add_subplot(223) # 2行、2列の3番目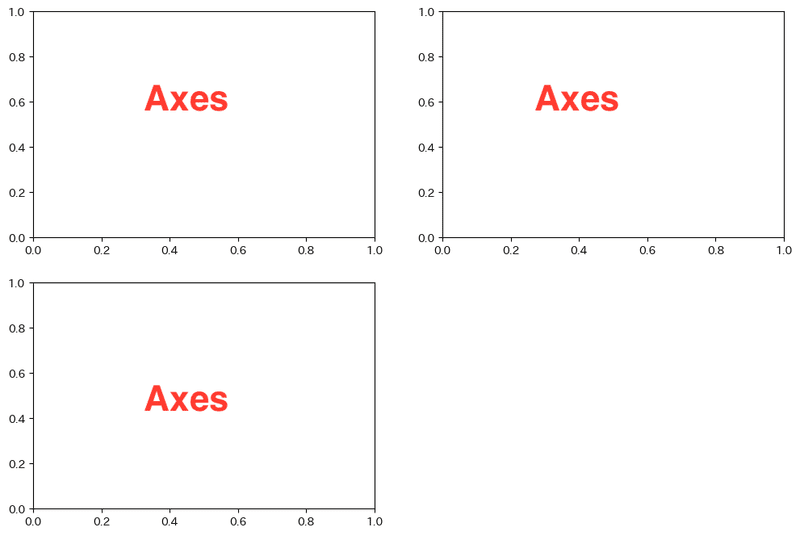
上記のように3つAxesオブジェクトが配置されます。
あとはこのAxesオブジェクトの中にグラフを書いていくことになります。
・棒グラフの作成
棒グラフは一般的にax.bar(x, y)で書きます。xが横軸、yが縦軸の要素です。
xとyのデータはlistでもarrayでも大丈夫です。
今回のコードだと棒グラフは下の部分です。
ax.bar([d.strftime('%m-%d') for d in country_data[i].日付.values[::-1]],country_data[i].感染者.values[::-1],color='mediumseagreen',linewidth=4)i=0を入れてみると
country_data[0]は米国の表
country_data[0].日付で日付の行だけを抜き出す。
また、一般的にDataframe.valuesでDataFrameをNumpy配列にするので、
country_data[i].日付.valuesで、下記のようなNumpy配列を取得します。
具体的には下記のようになっています。
また、value.[::-1]
というようにスライスが出てきていますが、
スライスは、[どこから:どこまで:ステップ]という書き方です。
[::1]のようにどこから、どこまでの部分を書かないと全体をステップごとに取り出せます。
今回はステップが-1で逆から1ずつ数えることになるので、下のようになります。順番を入れ替えたのと同じです。
下のforでは、この中から日付を一つ一つ取り出し、dとして、
d.strftime('%m-%d') for d in country_data[i].日付.values[::-1]d.strftime('%m-%d')によって03-04のような形にしてくれています。
この日付を集めてリストにしているのがax.barの第一引数です。
[d.strftime('%m-%d') for d in country_data[i].日付.values[::-1]]ax.barの第二引数の
country_data[i].感染者.values[::-1]では感染者数の要素を小さい順に並べてNumpy配列を作っています。
color='mediumseagreen',linewidth=4上の部分では、引数で、棒グラフの色と線の幅を設定しています。
つまり、
ax.bar([d.strftime('%m-%d') for d in country_data[i].日付.values[::-1]],country_data[i].感染者.values[::-1],color='mediumseagreen',linewidth=4)で下の棒グラフになります。
横軸の日付ですが、1日単位で描画すると上のようになってしまいました。
・横軸のラベル位置の調整
横軸のラベル位置が重なっちゃってて見えないので、調整していきます。
x軸のラベルを調整するにはplt.xticks()を使い、第一引数で「どの位置」にだ第二引数で「何を」表示するかをリストで指定します。
具体的には
plt.xticks([1,2,3],["a","b","c"])のような形です。
今回のコードでは下のようになっています。
plt.xticks([n for n in range(0,len(x),7)],[d.strftime('%m-%d') for d in country_data[i].日付.values[::-1][::7]])第一引数では、0から7刻みで表示位置を決めて、03-04のような日付を7刻みで表示させるように指定しています。
つまり、下のコードで
fig = plt.figure(figsize=(12.0, 8.0))
ax = fig.add_subplot(111)
x = [i for i in range(0,country_data[i].shape[0])]
ax.bar([d.strftime('%m-%d') for d in country_data[i].日付.values[::-1]],country_data[i].感染者.values[::-1],color='mediumseagreen',linewidth=4)
plt.xticks([n for n in range(0,len(x),7)],[d.strftime('%m-%d') for d in country_data[i].日付.values[::-1][::7]])
plt.show()次のような棒グラフができます。
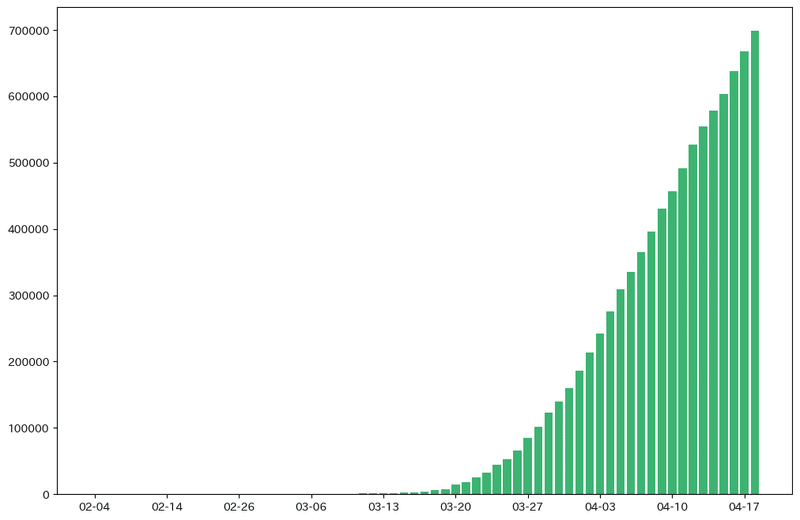
もうほぼ完璧な感染者数のグラフですよね。
あとはグラフのスタイルシートの設定や、グラフタイトルをつけたり、X軸のラベルやY軸のラベルの設定をしていきます。
そして、最終的に完成したコードが下です。
plt.style.use('default')
fig = plt.figure(figsize=(12.0, 8.0))
plt.rcParams['font.family'] = 'IPAexGothic'
ax = fig.add_subplot(111)
x = [i for i in range(0,country_data[i].shape[0])]
ax.bar([d.strftime('%m-%d') for d in country_data[i].日付.values[::-1]],country_data[i].感染者.values[::-1],color='mediumseagreen',linewidth=4)
ax.set_title('{}日時点-{}'.format(today,top_20[i]),fontsize=18)
plt.xticks([n for n in range(0,len(x),7)],[d.strftime('%m-%d') for d in country_data[i].日付.values[::-1][::7]])
plt.xlabel('日付',fontsize=18)
plt.ylabel('感染者数',fontsize=18)
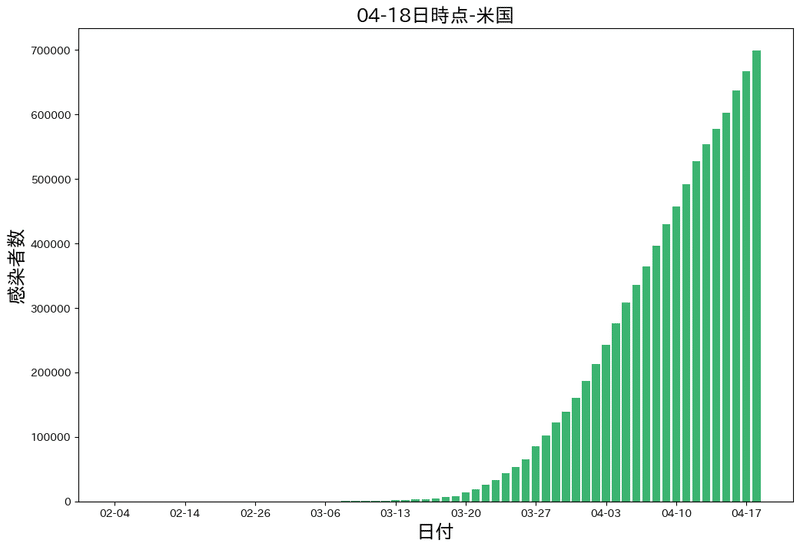
plt.show()大体は見れば分かると思うので、少しだけ解説すると
plt.style.use('default')の行では、スタイルシートの設定
plt.rcParams['font.family'] = 'IPAexGothic'の行では、日本語フォントが文字化けしないためにフォントの設定をしています。
棒グラフが完成しました。
上位20カ国の折れ線グラフ
次は上位20カ国の折れ線グラフです。
棒グラフはax.barでしたが、折れ線グラフはax.plot
で書いていきます。
# 上位20カ国折れ線グラフ出力
country_data = [0]*len(top_20)
today = max(days).strftime('%m-%d')
fig = plt.figure(figsize=(12.0, 8.0))
plt.style.use('default')
plt.rcParams['font.family'] = 'IPAexGothic'
ax = fig.add_subplot(111)
plt.xlabel('日付',fontsize=18)
plt.ylabel('感染者数',fontsize=18)
ax.set_title('{}日時点'.format(today),fontsize=18)
for i in range(len(top_20)):
country_data[i] =plt_data[plt_data['国・地域']==top_20[i]]
ax.plot([d.strftime('%m-%d') for d in country_data[i].日付.values[::-1]],country_data[i].感染者.values[::-1],linewidth=2,label=top_20[i])
plt.legend()
plt.xticks([n for n in range(0,country_data[0].shape[0],7)],[d.strftime('%m-%d') for d in country_data[0].日付.values[::-1][::7]])
plt.xlim(0,country_data[0].shape[0])
plt.ylim(0,)
plt.show()このコードで下のグラフになります。
上のfor文で棒グラフの線を書いています。
for i in range(len(top_20)):
country_data[i] =plt_data[plt_data['国・地域']==top_20[i]]
ax.plot([d.strftime('%m-%d') for d in country_data[i].日付.values[::-1]],country_data[i].感染者.values[::-1],linewidth=2,label=top_20[i])ax.plot(x,y)で折れ線グラフが書けます。
xは横軸要素、yは縦軸要素です。要素はリストでもNumpy配列でもどちらでも大丈夫です。棒グラフの時とほぼ同じですね。
このfor文以外で棒グラフから追加されてる部分を少し解説していきます。
plt.legend()は左上の帯である

を表示させてくれます。plt.legend()を消すと帯は無くなります。
plt.xlim()で横軸のデータの開始位置と終了位置
plt.ylim()で縦軸のデータの開始位置と終了位置の指定ができます。
上位20カ国の日別感染者数の棒グラフ
最後に日別感染者数の棒グラフのコードです。
# 日毎感染者各国棒グラフ出力
country_data = [0]*len(top_20)
today = max(days).strftime('%m-%d')
for i in range(len(top_20)):
#country_data [i] =plt_data[plt_data['国・地域']==top_20[i]]
country_data[i] =plt_data[plt_data['国・地域']==top_20[i]].copy()
#country_data [i]['日毎感染者'] = (country_data[i]['感染者'] - country_data[i]['感染者'].shift(-1))/(country_data[i].日付-country_data[i].日付.shift(-1)).dt.days
country_data[i].loc[:,"日毎感染者"]= (country_data[i].loc[:,"感染者"] - country_data[i].loc[:,"感染者"].shift(-1))/(country_data[i].日付-country_data[i].日付.shift(-1)).dt.days
plt.style.use('default')
fig = plt.figure(figsize=(12.0, 8.0))
plt.rcParams['font.family'] = 'IPAexGothic'
ax = fig.add_subplot(111)
x = [i for i in range(0,country_data[i].shape[0])]
ax.bar([d.strftime('%m-%d') for d in country_data[i].日付.values[::-1]],country_data[i].日毎感染者.values[::-1],color='turquoise',linewidth=5)
ax.set_title('{}日時点-{}'.format(today,top_20[i]),fontsize=18)
plt.xticks([n for n in range(0,len(x),7)],[d.strftime('%m-%d') for d in country_data[i].日付.values[::-1][::7]])
plt.xlabel('日付',fontsize=18)
plt.ylabel('日毎感染者数',fontsize=18)
plt.ylim(0,)
plt.show()日別感染者数については厚生労働省のページから直接は取れなかったので、
日別感染者数 =(今日の感染者数)-(前日の感染者数)
の計算をして棒グラフを描画しています。
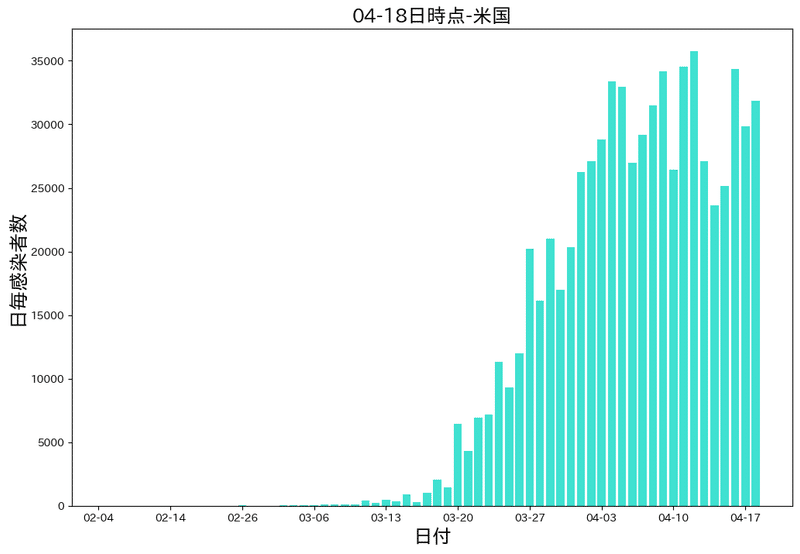
これで3種類のグラフ描画ができました。細かい解説は最初の棒グラフの時とかぶるのでそちらの解説を読んでみて下さい。
今回完成したコード全体
完成したコード全体は下のようになります。
from urllib import request
from urllib.request import urlopen
import urllib.parse
from bs4 import BeautifulSoup
import re
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import datetime as dt
import numpy as np
from tqdm.notebook import tqdm #from tqdm import tqdm_notebook
%matplotlib inline
##1ページ分の内容をsoupとして取得
def get_page_data(url):
#get html
html = request.urlopen(url)
#set BueatifulSoup
soup = BeautifulSoup(html, "html.parser")
return soup
##テーブルデータがある場合
##取得対象のテーブルか判定
def get_table_data(url,day):
for table_data in pd.read_html(url,header=0):
if '国・地域' in table_data.columns:
table_data.columns = ['国・地域','感染者','死亡者']
table_data.loc[:,'国・地域']=table_data['国・地域'].str.replace('※','')
table_data.loc[:,'日付'] = day
table_data = table_data[['日付','国・地域','感染者','死亡者']]
try:
table_data.loc[:,'感染者'] = table_data['感染者'].str.replace('名','')
table_data.loc[:,'死亡者'] = table_data['死亡者'].str.replace('名','')
table_data.loc[:,'感染者'] = table_data['感染者'].str.replace(',','')
table_data.loc[:,'死亡者'] = table_data['死亡者'].str.replace(',','')
table_data.loc[:,'感染者'] = table_data['感染者'].astype(int)
table_data.loc[:,'死亡者'] = table_data['死亡者'].astype(int)
except:
return table_data
return table_data
return ''
##テーブルデータがない場合
def get_not_table_data(soup,day):
row_data_list = []
for i in range(len(soup.find_all(name='p'))):
append_data = re.findall(r'・\D*感染者.\d*名.*死亡者\d*名',soup.find_all(name='p')[i].get_text().replace(',',''))
if len(append_data)!=0:
row_data = append_data
for i in row_data:
country = re.search(r'・(.*):',i).group(1)
infected = re.search(r'感染者\D?(\d*)名',i).group(1)
deaths = re.search(r'死亡者\D?(\d+)名',i).group(1)
row_data_list.append([day,country,int(infected),int(deaths)])
return row_data_list
##plotデータ作成
def make_plot_data(data_list):
plt_data = pd.DataFrame(["","","",""]).T
plt_data.columns = ['日付','国・地域','感染者','死亡者']
for num,i in enumerate(data_list):
if len(i)>0:
plt_data=plt_data.append(i)
else:
print(num)
plt_data = plt_data.loc[~((plt_data['国・地域']=='その他')|(plt_data['国・地域']=='計'))]
plt_data = plt_data.iloc[1:].reset_index(drop=True)
return plt_data
##urlと日付データの取得
url = "https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000121431_00086.html"
#get html
html = request.urlopen(url)
#set BueatifulSoup
soup = BeautifulSoup(html, "html.parser")
##取得対象URL/日付取得
links =[url.get('href') for url in soup.find_all(name=lambda x: x.name=="a" and "新型コロナウイルス感染症の" in x.text and "状況" in x.text)]
days = [url.get_text() for url in soup.find_all(name=lambda x: x.name=="a" and "新型コロナウイルス感染症の" in x.text and "状況" in x.text)]
days = [[((re.search(r'\d+月',i)).group()).replace('月',''),((re.search(r'\d+日',i)).group()).replace('日','')] for i in days]
days = [dt.date(dt.datetime.today().year,int(i[0]),int(i[1])) for i in days]
##データ取得
data_list = [] #for i,d in zip(tqdm_notebook(links,desc='進捗', leave=True),days):
for i,d in zip(tqdm(links,desc='進捗', leave=True),days):
data = get_table_data(i,d)
if len(data) == 0:
data = get_not_table_data(get_page_data(i),d)
data = pd.DataFrame(data)
data.columns = ['日付','国・地域','感染者','死亡者']
data_list.append(data)
##plot用テーブルデータ作成
plt_data = make_plot_data(data_list)
##上位20カ国+日本取得
top_20 = list(plt_data.query('日付==@plt_data.日付.max()').sort_values(by='感染者',ascending=False)['国・地域'].iloc[:20])
top_20.append('日本')
## 各国棒グラフ出力(累積)
country_data = ['0']*len(top_20)
print(country_data)
today = max(days).strftime('%m-%d')
for i in range(len(top_20)):
country_data[i] =plt_data[plt_data['国・地域']==top_20[i]]
plt.style.use('default')
fig = plt.figure(figsize=(12.0, 8.0))
plt.rcParams['font.family'] = 'IPAexGothic'
ax = fig.add_subplot(111)
print(country_data[i].日付.values[::-1])
ax.bar([d.strftime('%m-%d') for d in country_data[i].日付.values[::-1]],country_data[i].感染者.values[::-1],color='mediumseagreen',linewidth=4)
ax.set_title('{}日時点-{}'.format(today,top_20[i]),fontsize=18)
x = [i for i in range(0,country_data[i].shape[0])]
plt.xticks([n for n in range(0,len(x),7)],[d.strftime('%m-%d') for d in country_data[i].日付.values[::-1][::7]])
plt.xlabel('日付',fontsize=18)
plt.ylabel('感染者数',fontsize=18)
plt.show()
#上位20カ国折れ線グラフ出力
country_data = [0]*len(top_20)
today = max(days).strftime('%m-%d')
fig = plt.figure(figsize=(12.0, 8.0))
plt.style.use('default')
plt.rcParams['font.family'] = 'IPAexGothic'
ax = fig.add_subplot(111)
plt.xlabel('日付',fontsize=18)
plt.ylabel('感染者数',fontsize=18)
ax.set_title('{}日時点'.format(today),fontsize=18)
for i in range(len(top_20)):
country_data[i] =plt_data[plt_data['国・地域']==top_20[i]]
ax.plot([d.strftime('%m-%d') for d in country_data[i].日付.values[::-1]],country_data[i].感染者.values[::-1],linewidth=2,label=top_20[i])
plt.legend()
plt.xticks([n for n in range(0,country_data[0].shape[0],7)],[d.strftime('%m-%d') for d in country_data[0].日付.values[::-1][::7]])
plt.xlim(0,country_data[0].shape[0])
plt.ylim(0,)
plt.show()
## 日毎感染者各国棒グラフ出力
country_data = [0]*len(top_20)
today = max(days).strftime('%m-%d')
for i in range(len(top_20)):
#country_data [i] =plt_data[plt_data['国・地域']==top_20[i]]
country_data[i] =plt_data[plt_data['国・地域']==top_20[i]].copy()
#country_data [i]['日毎感染者'] = (country_data[i]['感染者'] - country_data[i]['感染者'].shift(-1))/(country_data[i].日付-country_data[i].日付.shift(-1)).dt.days
country_data[i].loc[:,"日毎感染者"]= (country_data[i].loc[:,"感染者"] - country_data[i].loc[:,"感染者"].shift(-1))/(country_data[i].日付-country_data[i].日付.shift(-1)).dt.days
plt.style.use('default')
fig = plt.figure(figsize=(12.0, 8.0))
plt.rcParams['font.family'] = 'IPAexGothic'
ax = fig.add_subplot(111)
x = [i for i in range(0,country_data[i].shape[0])]
ax.bar([d.strftime('%m-%d') for d in country_data[i].日付.values[::-1]],country_data[i].日毎感染者.values[::-1],color='turquoise',linewidth=5)
ax.set_title('{}日時点-{}'.format(today,top_20[i]),fontsize=18)
plt.xticks([n for n in range(0,len(x),7)],[d.strftime('%m-%d') for d in country_data[i].日付.values[::-1][::7]])
plt.xlabel('日付',fontsize=18)
plt.ylabel('日毎感染者数',fontsize=18)
plt.ylim(0,)
plt.show()ここまでがコード全体です。
以下のグラフに挑戦してみて下さい
さて、今回グラフを描画しましたが、以下を実際に描画して確認してみて下さい。
・20カ国分のグラフの表示
・死亡者数のデータを取ってあるのですが、そのグラフ
・圏外に行ったスウェーデンと韓国の日毎の感染者数のグラフ
以上はまだできていないので、ぜひ時間がある時に挑戦してみて下さい。
この記事が気に入ったらサポートをしてみませんか?