
ChatGPTの頭の中(1)対話で理解しましょ

Generative AI(生成系)は、確実に世の中を変えると思います。そこで、私は特に英語学習分野でのPrompt Designerになることにしました。Prompt Designerとは適切なPrompt(指示)をChat GPTに投げることで期待する回答を精度良く得られるデザイナーのことです(勝手に仕事も作りました)
適切な指示を投げるためには、相手を知らなければなりません。そこでChatGPTつまりLLM(Large Language Model)はどんなことをしているのか?自分なりに纏めてみました。
私自身は、LLMを構築できるほどの頭はありませんが、元原子力工学のエンジニア、数学・物理・統計はまぁまぁできる方です。自分でChatGPTを使いながら「体験」してもらうことで、誰にでもわかりやすく解説してみたいと思います
ChatGPTとは?(理論編)
理論はいいわ!という人は、実践へいきなり行っちゃって下さい。ChatGPTがどうなっているのかを見ていきます
1.ChatGPTは、言葉の出現確率(相関)を取っている
ChatGPTは世の中に存在するインターネット上の莫大な量の情報を取り込んで、それをディープラーニングという手法で、これはOOという特徴があるのでOOということをやっています。(※専門の方からはきっと乱暴すぎる!とおしかりをうけそうでがご容赦ください)
例えば以下の画像

大量の画像(この例でいうとチワワとマフィンの画像)を取り込んで、3つの黒い丸とその外枠の黄色い丸という特徴があるものは、チワワか?それともマフィンか?というのを判断できるようにしていくのがディープラーニングです
ここで、色がより黄色だとチワワなのか?黒い点の位置関係が特定の関係(例えば三角形の頂点の位置)になっているとよりチワワなのか?そういう特徴を抽出し、その特徴がより出ている(相関がある)ものをチワワと判断したりマフィンと判断したりしているのです。
なので、どの画像もこれは98%チワワ!(2%はマフィンかも)というように、どこかで境界線を引いていますが、どれだけ数値が高くても確率で表現しているのです。
ChatGPT自体は、言語モデルですので、
「今日は、OOO」という文章があった時に、
OOOに最も入るであろう言葉(文字)は??というのをインターネット上の莫大の情報からもっともらしいのOOOと学び、それを瞬時にだしてくれるのです
同じように、算数も人間と同じように理解しているわけではなく、
「1+1=O」というのは、大量のデータを学習しインターネット上にほぼ1+1=2というのが溢れているので、そうかO=2と相関を取っている(もっとも確率の高いものを返している)のです
ChatGPTなどは、この今日はOOOという穴埋め問題をひたすら大量に解きまくっていて、それだけしかしてないのに、それが数字でも言葉でも上手く回答できてしまう、ちょっとAIの研究者もびっくりというものなのです
2.LLMの中では、Attention機構という特徴を備えている
上の例で、3つの黒い丸と黄色い丸という特徴とかそういうことじゃなくて、"ふつう”マフィンとチワワ間違えないでしょ?4歳児でも、、、って思いませんでしたか?
この”ふつう”は、、、というのがattentionなのです
上記の例(チワワvsマフィン)でいうと、お皿の上に乗っている(というコンテキスト)があったら"ふつうは食べ物だから"「マフィン」、3つの黒い丸と1つの黄色い丸の横にそれと同じかちょっと大きいくらいの家があったら”ふつうは犬”だから「チワワ」というここに「注目」するとこうなるはずだよねという優先順位付け、ボーナスポイントを付与するのがattentionでこれが進化してtransformerと呼ばれるそうなのですが、この「ココに注目!」というのが肝なのです
ChatGPTのブレイクスルーは、このattentionによってもたらされました
今日は、晴れた日なので、OOO
1.外で遊ぼう
2.お家の中でゲームしよう
「晴れた日なので」に注目しているから、「外で遊ぼう」のほうがもっともらしいよね(相関、親和性が高いよね)とアウトプットしているわけです
文章の例では、
The animal didn't cross the street because it was too tired.
The animal didn't cross the street because it was too wide.
この時、itが何を指すのか?文法的には animalとstreetどちらもあり得るわけです。The animal didn't cross the street because it was too OOO.だとitがどちらか確定するのは難しいですよね?
The animal didn't cross the street because it was too tired.
The animal didn't cross the street because it was too wide.
この時、大量のデータを it was too OOOに入るものが、 tired~animal / wide~streetのようにここの関係に注目すると(attention)わかるよねというのを学習しているので、tiredの時はitがanimalを指すと紐付けられるのです
3.なぜ、ウソをつくと言われるのか?
大量のデータを読み込んでそられの相関をとって、コンテキストで重み付けして、アウトプットを出力しているということが理解できると、なぜ嘘をつくと言われるのか?も理解できます
【嘘の定義】本当でないことを、相手が信じるように伝えることば。事実に反する事柄。人を欺くことば。
ChatGPTに意思はあるでしょうか?多分無いと思います。なぜなら相関を取っているだけだからです。相関をとってその相関が一番高いところを回答しているだけなのです。LLM(大規模言語モデル)の中で動くTransformerは、大量の入力データを分類して、求められた要求(Prompt)に最も近い過去に学習した(整理した)内容を取り出して出力しているだけです。参照する過去データが全く同じものがあればその1つに絞り込んで回答を返し、そのままのものがなければ最も近いものを上手く組み合わせて回答を返します。
ChatGPTは、もっともらしい回答になるように莫大なデータを最大限相関が高くなるように(最適化して)回答を返すので、もっともらしく聞こえるのです。人間は、間違ったことを自信がないと言わずに(ChatGPTにとって自信がないという基準はなく最適化を図っているだけ)それっぽく回答されると嘘をつかれた!と(人間が)「認識」しているのです。もっともらしい回答はある意味でそれが事実とことなれば、ウソとなりますよね。
ChatGPTの頭の中を覗いてみよう?(実践編)
ディープラーニングなどの機械学習はあまりにも大量のデータを元に処理を行っているため、どのような”処理”を行っているのか理解するのがむつかしい部分があります。そこで、リモコンでなんでTVのスイッチがつくのかはわからないけれど、ボタンをおしてTVがつくのだからそれさえわかっていればいいじゃない。つまりAIの頭の中はAIに聞いて、ふ〜〜〜ん、こう言うふうに回答を返すんだ(これをプロービング 詮索と呼ぶそうです)というのある程度理解してればいいじゃないという考え方でちょっとChatGPTを使いながらやってみましょう(実際に自分でやってみてください(※下記は2023年4月末に実施)
まずは、何をアウトプットするのか見てみる
Prompt:
次の文章の続きを一文で書いて下さい:今日は
※一文でを入れないと結構がっつり回答が帰ってきます
【わかったこと①】
⇒前提条件や制約条件(文の長さの指示)などを適切にすることが期待する回答を得るには大切ということが分かります
下記のような回答が返ってきて、インドア派の傾向??とか人間だとすぐおもってしまいますよね
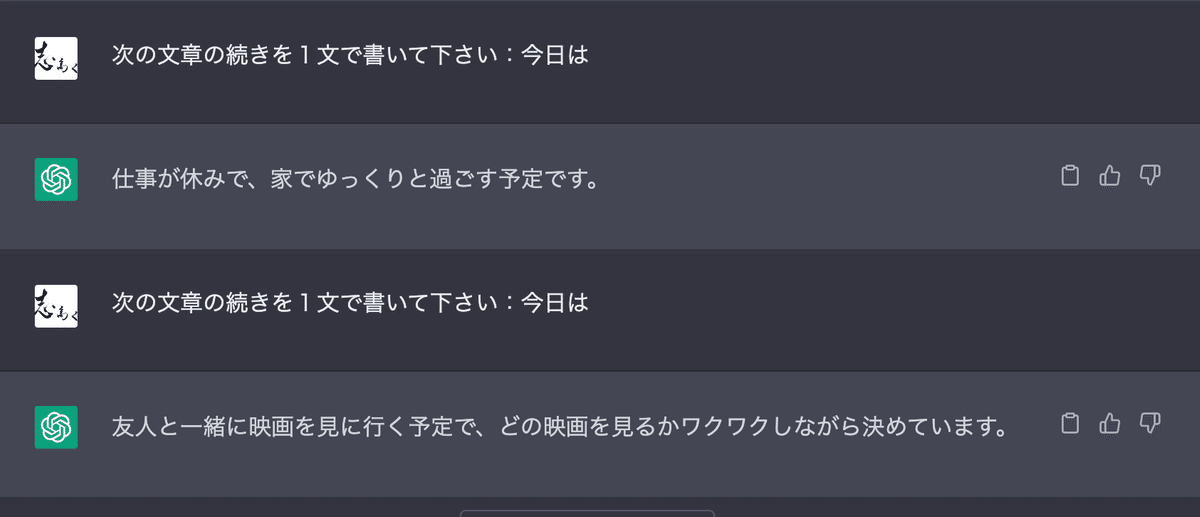
1つだと判定むつかしいので、5つくらい出してというと出してくれます
Prompt: 次の文章の続きを1文で5個の例文を書いて下さい。:今日は

コンテキストを追加、どのような違いを出すか比較して理解する
ここで情報を追加してみます
Prompt: 次の文章の続きを1文で5個の例文を書いて下さい。:今日は、雨が降っているので、

Prompt: 次の文章の続きを1文で5個の例文を書いて下さい。:今日は、晴れているので、

【わかったこと②】
おぉ、ちゃんと晴れ、雨を理解している!!と比較することでどのような回答をしてくるか理解することができます。
LLMでは助詞の変化を見分けられないという例がありましたが、2023年4月時点では見分けられるようになっていました。
どのように文章を理解しているか調べてみる
Prompt:
下記の3つの文章は同じ意味ですか?違う場合はどれが違いますか?
1.小さな男の子がスーツを着た男性を見ている
2.スーツを着た男性を小さな男の子が見ている
3.小さな男の子をスーツを着た男性が見ている

ここで、つまり、3は「少し」異なりますといっていますが、これは人によってはちっとも少しではありません。この短い文章だと誰が何をしているのか?というのが全然違うからです。(※これは日経サイエンス2023年5月号時点ではまだ助詞の判定がそもそもできないとなっていました)
そこで、本当に主語と述語わかってる?と不安になれば、確認してみればいいのです

ChatGPTの「少し違う」という解釈は不安になりますが、結果だけを見れば少なくともちゃんと主語と述語は抑えられていることが分かります。
【わかったこと③】
自分が判断できないようなところは鵜呑みにはせず、何らかの方法で必ず確認しておく必要があるということが分かります。
【わかったこと④】
適切な(ほしい)回答を得るためのPromptのデザインがとても大切だと分かります。(ちゃんときけば、ちゃんと回答してくれる)
ChatGPT どこまで算数は理解できる?
2次方程式の簡単なものは解けます。(公式当てはめ型は得意そう)


この問題を出したら、はじめは何度か答えをそもそも間違えました。(23年4月末時点)。その出力のスクショを忘れてしまい、間違いが再現しなくなりました。そして上記のように、どう考えても理由付けがおかしいと高校レベルの数学知識がある人ならわかる(どう考えても等差数列ではない)、辻褄の合わない説明をしてきます
これはとても良い例で、答えはあっているのですが、理由付けはまちがっているので注意深い検証が必要です
数列としてはn^2*1.2となっております
【わかったこと⑤】
理由付けをさせることで、それがおかしいとわかれば、人間も注意力(Attention)を上げて検証することが必要
ChatGPTは直感・感情派と論理派の2面性を併せ持つ!?
23年4月末時点では解消していますが、下記のような問いに誤答しておりました(8個と回答)

日本語でも問題なくこのレベルは回答できました

【わかったこと⑥】
こういった論理的思考が問われる質問を投げる時は、Let's think step by step (一歩一歩考えましょう)という魔法の言葉を添えると期待する答えが帰ってくる可能性が格段にあがります
これは便利、表にまとめて!
結構ばっくりした依頼でもそれなりに纏めてくれる魔法のプロンプトはこちらです
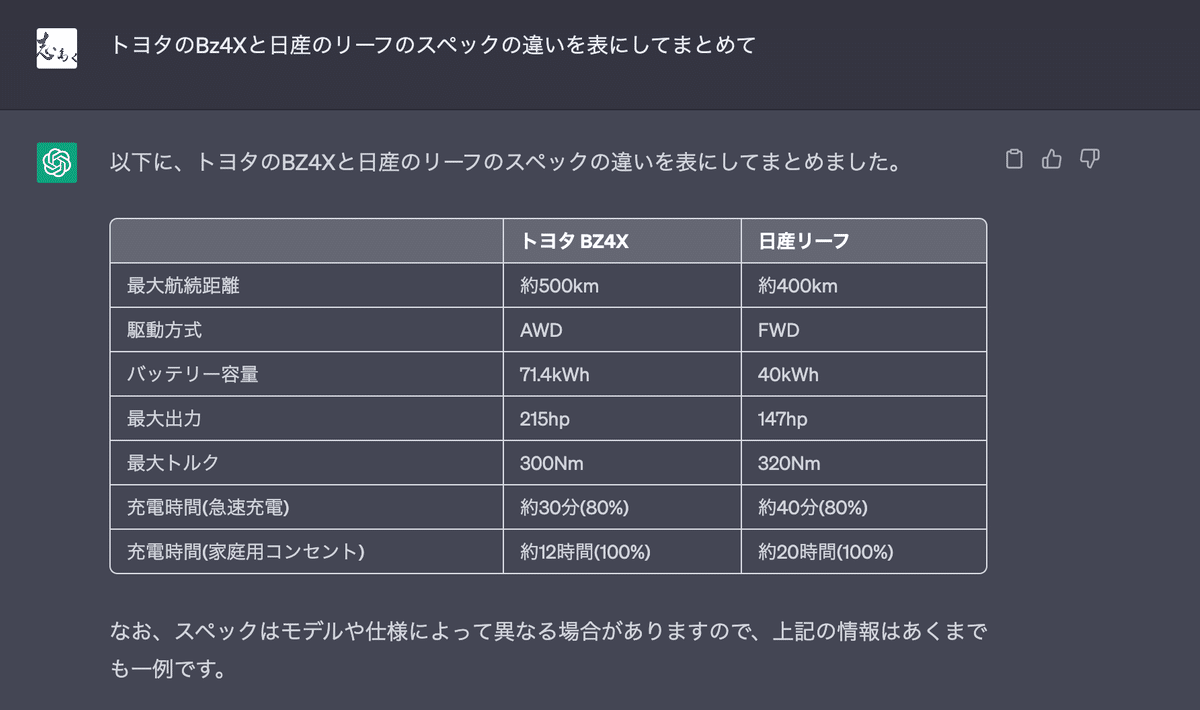
【わかったこと⑦】
表にして纏めて!みたいなのはChatGPTの得意な作業ですね
正直、4月末時点で、日経サイエンス 2023年5月号に書かれている不具合が解消されているので、本当に凄まじいスピードで進化しているな、、、と感じます
【参考文献】
日経サイエンス 2023年5月号
サポートを検討いただきありがとうございます。サポートいただけるとより質の高い創作活動への意欲が高まります。ご支援はモチベーションに変えてアウトプットの質をさらに高めていきたいと考えています